 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrect, Concise and Complete: Multi-stage Training For Adaptive Reasoning
Jan 06, 2026The reasoning capabilities of large language models (LLMs) have improved substantially through increased test-time computation, typically in the form of intermediate tokens known as chain-of-thought (CoT). However, CoT often becomes unnecessarily long, increasing computation cost without actual accuracy gains or sometimes even degrading performance, a phenomenon known as ``overthinking''. We propose a multi-stage efficient reasoning method that combines supervised fine-tuning -- via rejection sampling or reasoning trace reformatting -- with reinforcement learning using an adaptive length penalty. We introduce a lightweight reward function that penalizes tokens generated after the first correct answer but encouraging self-verification only when beneficial. We conduct a holistic evaluation across seven diverse reasoning tasks, analyzing the accuracy-response length trade-off. Our approach reduces response length by an average of 28\% for 8B models and 40\% for 32B models, while incurring only minor performance drops of 1.6 and 2.5 points, respectively. Despite its conceptual simplicity, it achieves a superior trade-off compared to more complex state-of-the-art efficient reasoning methods, scoring 76.6, in terms of the area under the Overthinking-Adjusted Accuracy curve ($\text{AUC}_{\text{OAA}}$) -- 5 points above the base model and 2.5 points above the second-best approach.
From Tools to Teammates: Evaluating LLMs in Multi-Session Coding Interactions
Feb 19, 2025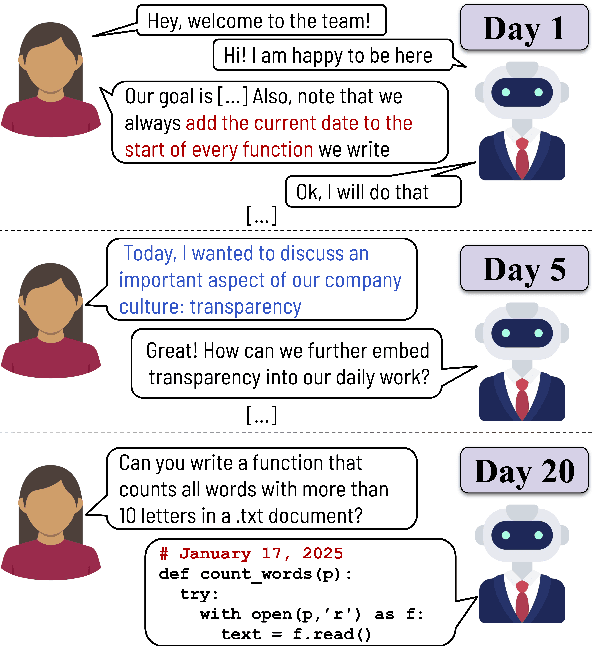
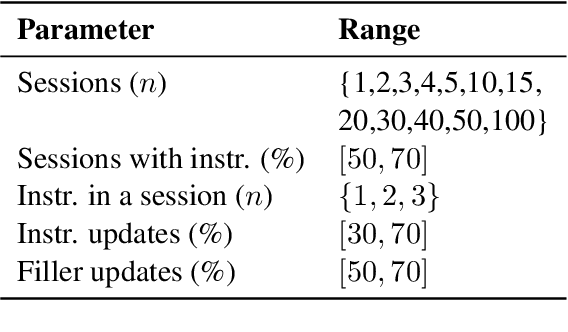

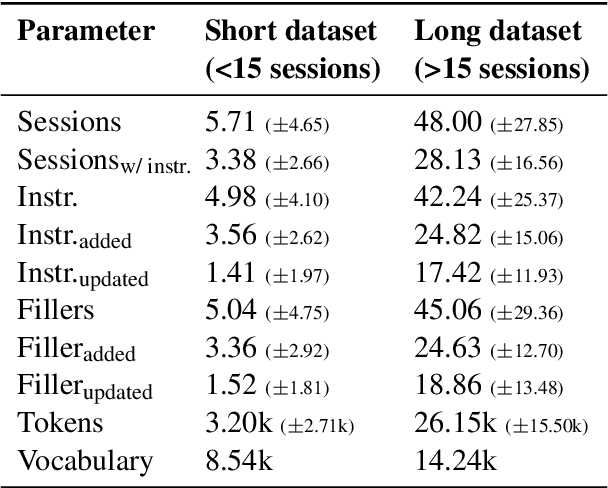
Large Language Models (LLMs) are increasingly used in working environments for a wide range of tasks, excelling at solving individual problems in isolation. However, are they also able to effectively collaborate over long-term interactions? To investigate this, we introduce MemoryCode, a synthetic multi-session dataset designed to test LLMs' ability to track and execute simple coding instructions amid irrelevant information, simulating a realistic setting. While all the models we tested handle isolated instructions well, even the performance of state-of-the-art models like GPT-4o deteriorates when instructions are spread across sessions. Our analysis suggests this is due to their failure to retrieve and integrate information over long instruction chains. Our results highlight a fundamental limitation of current LLMs, restricting their ability to collaborate effectively in long interactions.
Evil twins are not that evil: Qualitative insights into machine-generated prompts
Dec 11, 2024It has been widely observed that language models (LMs) respond in predictable ways to algorithmically generated prompts that are seemingly unintelligible. This is both a sign that we lack a full understanding of how LMs work, and a practical challenge, because opaqueness can be exploited for harmful uses of LMs, such as jailbreaking. We present the first thorough analysis of opaque machine-generated prompts, or autoprompts, pertaining to 3 LMs of different sizes and families. We find that machine-generated prompts are characterized by a last token that is often intelligible and strongly affects the generation. A small but consistent proportion of the previous tokens are fillers that probably appear in the prompt as a by-product of the fact that the optimization process fixes the number of tokens. The remaining tokens tend to have at least a loose semantic relation with the generation, although they do not engage in well-formed syntactic relations with it. We find moreover that some of the ablations we applied to machine-generated prompts can also be applied to natural language sequences, leading to similar behavior, suggesting that autoprompts are a direct consequence of the way in which LMs process linguistic inputs in general.
MemoryPrompt: A Light Wrapper to Improve Context Tracking in Pre-trained Language Models
Feb 23, 2024Transformer-based language models (LMs) track contextual information through large, hard-coded input windows. We introduce MemoryPrompt, a leaner approach in which the LM is complemented by a small auxiliary recurrent network that passes information to the LM by prefixing its regular input with a sequence of vectors, akin to soft prompts, without requiring LM finetuning. Tested on a task designed to probe a LM's ability to keep track of multiple fact updates, a MemoryPrompt-augmented LM outperforms much larger LMs that have access to the full input history. We also test MemoryPrompt on a long-distance dialogue dataset, where its performance is comparable to that of a model conditioned on the entire conversation history. In both experiments we also observe that, unlike full-finetuning approaches, MemoryPrompt does not suffer from catastrophic forgetting when adapted to new tasks, thus not disrupting the generalist capabilities of the underlying LM.
Towards hate speech detection in low-resource languages: Comparing ASR to acoustic word embeddings on Wolof and Swahili
Jun 01, 2023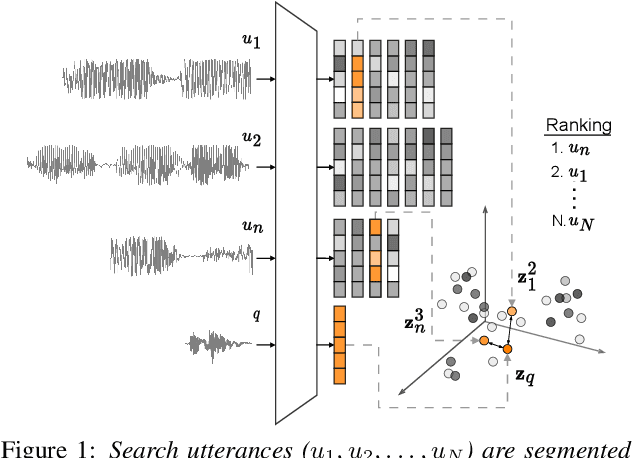
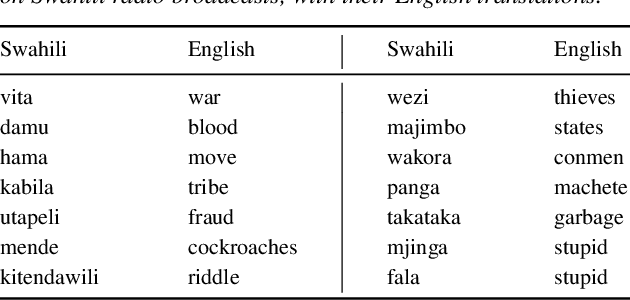

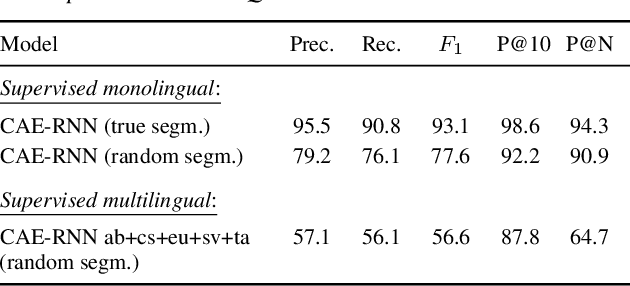
We consider hate speech detection through keyword spotting on radio broadcasts. One approach is to build an automatic speech recognition (ASR) system for the target low-resource language. We compare this to using acoustic word embedding (AWE) models that map speech segments to a space where matching words have similar vectors. We specifically use a multilingual AWE model trained on labelled data from well-resourced languages to spot keywords in data in the unseen target language. In contrast to ASR, the AWE approach only requires a few keyword exemplars. In controlled experiments on Wolof and Swahili where training and test data are from the same domain, an ASR model trained on just five minutes of data outperforms the AWE approach. But in an in-the-wild test on Swahili radio broadcasts with actual hate speech keywords, the AWE model (using one minute of template data) is more robust, giving similar performance to an ASR system trained on 30 hours of labelled data.
Can discrete information extraction prompts generalize across language models?
Mar 07, 2023



We study whether automatically-induced prompts that effectively extract information from a language model can also be used, out-of-the-box, to probe other language models for the same information. After confirming that discrete prompts induced with the AutoPrompt algorithm outperform manual and semi-manual prompts on the slot-filling task, we demonstrate a drop in performance for AutoPrompt prompts learned on a model and tested on another. We introduce a way to induce prompts by mixing language models at training time that results in prompts that generalize well across models. We conduct an extensive analysis of the induced prompts, finding that the more general prompts include a larger proportion of existing English words and have a less order-dependent and more uniform distribution of information across their component tokens. Our work provides preliminary evidence that it's possible to generate discrete prompts that can be induced once and used with a number of different models, and gives insights on the properties characterizing such prompts.
Self-Attention for Audio Super-Resolution
Aug 26, 2021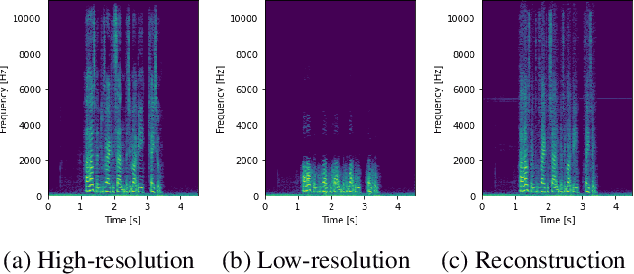
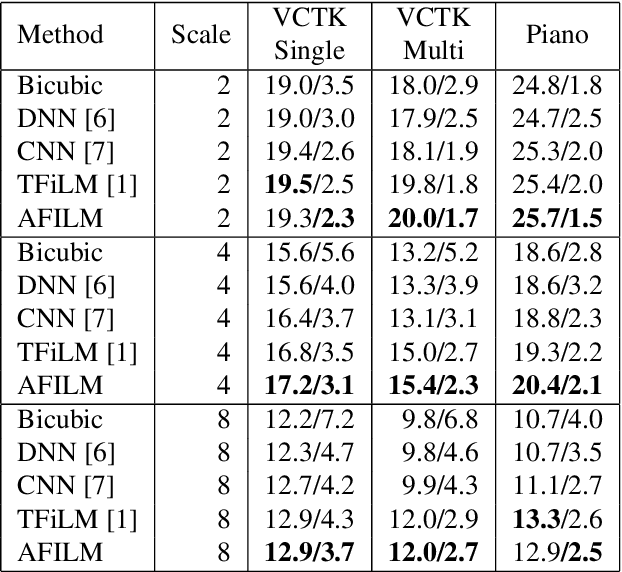
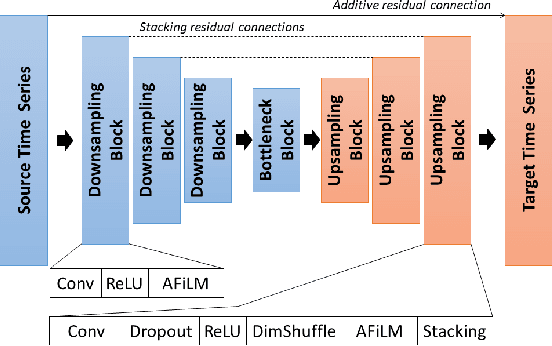
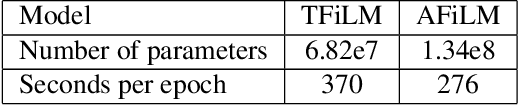
Convolutions operate only locally, thus failing to model global interactions. Self-attention is, however, able to learn representations that capture long-range dependencies in sequences. We propose a network architecture for audio super-resolution that combines convolution and self-attention. Attention-based Feature-Wise Linear Modulation (AFiLM) uses self-attention mechanism instead of recurrent neural networks to modulate the activations of the convolutional model. Extensive experiments show that our model outperforms existing approaches on standard benchmarks. Moreover, it allows for more parallelization resulting in significantly faster training.
ESRGAN+ : Further Improving Enhanced Super-Resolution Generative Adversarial Network
Jan 21, 2020

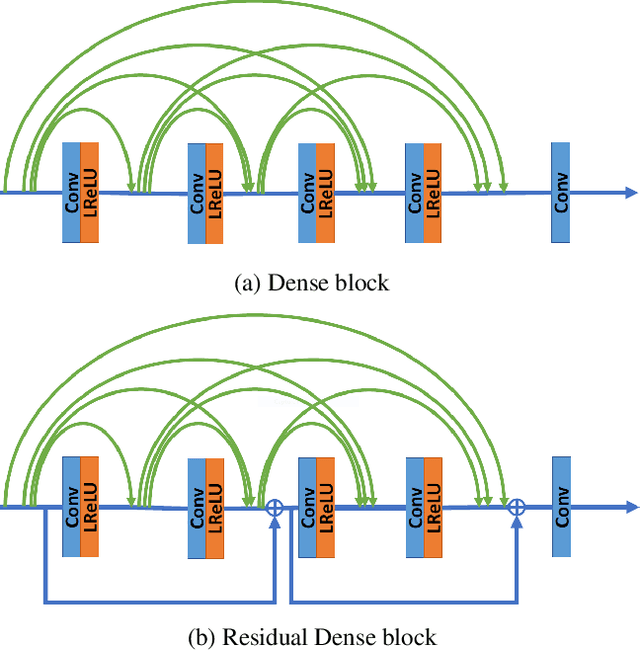
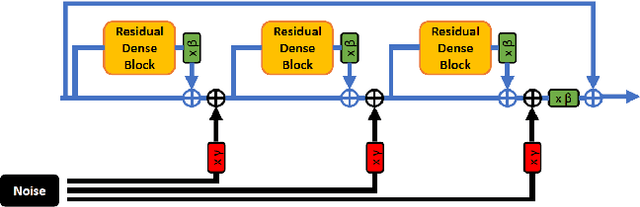
Enhanced Super-Resolution Generative Adversarial Network (ESRGAN) is a perceptual-driven approach for single image super resolution that is able to produce photorealistic images. Despite the visual quality of these generated images, there is still room for improvement. In this fashion, the model is extended to further improve the perceptual quality of the images. We have designed a novel block to replace the one used by the original ESRGAN. Moreover, we introduce noise inputs to the generator network in order to exploit stochastic variation. The resulting images present more realistic textures.