 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracing Computation Density in LLMs
May 26, 2026Transformer-based large language models (LLMs) are comprised of billions of parameters arranged in deep and wide computational graphs, but it is not clear that they exploit their full capacity for all inputs. We introduce the s-Trace method to efficiently estimate the subgraph of size s that best approximates a full model output. With this method, we find the computation in a variety of LLMs to be organized in two distinct phases. A small subgraph mostly composed of early-layer nodes can reconstruct the head of the full model output distribution. Adding further nodes, mostly located in later layers and increasingly consisting of attention heads, leads to incremental refinements in approximating the full output distribution. We find moreover that the amount of necessary computation per input correlates with model uncertainty, and that sparser subgraphs encode shallow statistics, such as unigram frequency. Overall, our results suggest a consistent modular organization in effective LLM computation, with a sparse early-layer core providing a rough prediction that is further refined through denser computations in later layers.
Sparse or Dense? A Mechanistic Estimation of Computation Density in Transformer-based LLMs
Jan 30, 2026Transformer-based large language models (LLMs) are comprised of billions of parameters arranged in deep and wide computational graphs. Several studies on LLM efficiency optimization argue that it is possible to prune a significant portion of the parameters, while only marginally impacting performance. This suggests that the computation is not uniformly distributed across the parameters. We introduce here a technique to systematically quantify computation density in LLMs. In particular, we design a density estimator drawing on mechanistic interpretability. We experimentally test our estimator and find that: (1) contrary to what has been often assumed, LLM processing generally involves dense computation; (2) computation density is dynamic, in the sense that models shift between sparse and dense processing regimes depending on the input; (3) per-input density is significantly correlated across LLMs, suggesting that the same inputs trigger either low or high density. Investigating the factors influencing density, we observe that predicting rarer tokens requires higher density, and increasing context length often decreases the density. We believe that our computation density estimator will contribute to a better understanding of the processing at work in LLMs, challenging their symbolic interpretation.
Evil twins are not that evil: Qualitative insights into machine-generated prompts
Dec 11, 2024It has been widely observed that language models (LMs) respond in predictable ways to algorithmically generated prompts that are seemingly unintelligible. This is both a sign that we lack a full understanding of how LMs work, and a practical challenge, because opaqueness can be exploited for harmful uses of LMs, such as jailbreaking. We present the first thorough analysis of opaque machine-generated prompts, or autoprompts, pertaining to 3 LMs of different sizes and families. We find that machine-generated prompts are characterized by a last token that is often intelligible and strongly affects the generation. A small but consistent proportion of the previous tokens are fillers that probably appear in the prompt as a by-product of the fact that the optimization process fixes the number of tokens. The remaining tokens tend to have at least a loose semantic relation with the generation, although they do not engage in well-formed syntactic relations with it. We find moreover that some of the ablations we applied to machine-generated prompts can also be applied to natural language sequences, leading to similar behavior, suggesting that autoprompts are a direct consequence of the way in which LMs process linguistic inputs in general.
Emergence of a High-Dimensional Abstraction Phase in Language Transformers
May 24, 2024



A language model (LM) is a mapping from a linguistic context to an output token. However, much remains to be known about this mapping, including how its geometric properties relate to its function. We take a high-level geometric approach to its analysis, observing, across five pre-trained transformer-based LMs and three input datasets, a distinct phase characterized by high intrinsic dimensionality. During this phase, representations (1) correspond to the first full linguistic abstraction of the input; (2) are the first to viably transfer to downstream tasks; (3) predict each other across different LMs. Moreover, we find that an earlier onset of the phase strongly predicts better language modelling performance. In short, our results suggest that a central high-dimensionality phase underlies core linguistic processing in many common LM architectures.
Unnatural language processing: How do language models handle machine-generated prompts?
Oct 24, 2023Language model prompt optimization research has shown that semantically and grammatically well-formed manually crafted prompts are routinely outperformed by automatically generated token sequences with no apparent meaning or syntactic structure, including sequences of vectors from a model's embedding space. We use machine-generated prompts to probe how models respond to input that is not composed of natural language expressions. We study the behavior of models of different sizes in multiple semantic tasks in response to both continuous and discrete machine-generated prompts, and compare it to the behavior in response to human-generated natural-language prompts. Even when producing a similar output, machine-generated and human prompts trigger different response patterns through the network processing pathways, including different perplexities, different attention and output entropy distributions, and different unit activation profiles. We provide preliminary insight into the nature of the units activated by different prompt types, suggesting that only natural language prompts recruit a genuinely linguistic circuit.
Bridging Information-Theoretic and Geometric Compression in Language Models
Oct 20, 2023For a language model (LM) to faithfully model human language, it must compress vast, potentially infinite information into relatively few dimensions. We propose analyzing compression in (pre-trained) LMs from two points of view: geometric and information-theoretic. We demonstrate that the two views are highly correlated, such that the intrinsic geometric dimension of linguistic data predicts their coding length under the LM. We then show that, in turn, high compression of a linguistic dataset predicts rapid adaptation to that dataset, confirming that being able to compress linguistic information is an important part of successful LM performance. As a practical byproduct of our analysis, we evaluate a battery of intrinsic dimension estimators for the first time on linguistic data, showing that only some encapsulate the relationship between information-theoretic compression, geometric compression, and ease-of-adaptation.
An experimental study of the vision-bottleneck in VQA
Feb 14, 2022As in many tasks combining vision and language, both modalities play a crucial role in Visual Question Answering (VQA). To properly solve the task, a given model should both understand the content of the proposed image and the nature of the question. While the fusion between modalities, which is another obviously important part of the problem, has been highly studied, the vision part has received less attention in recent work. Current state-of-the-art methods for VQA mainly rely on off-the-shelf object detectors delivering a set of object bounding boxes and embeddings, which are then combined with question word embeddings through a reasoning module. In this paper, we propose an in-depth study of the vision-bottleneck in VQA, experimenting with both the quantity and quality of visual objects extracted from images. We also study the impact of two methods to incorporate the information about objects necessary for answering a question, in the reasoning module directly, and earlier in the object selection stage. This work highlights the importance of vision in the context of VQA, and the interest of tailoring vision methods used in VQA to the task at hand.
Supervising the Transfer of Reasoning Patterns in VQA
Jun 10, 2021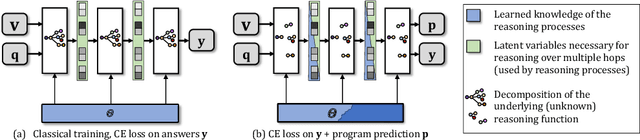

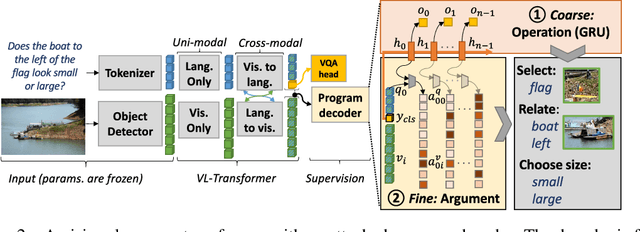
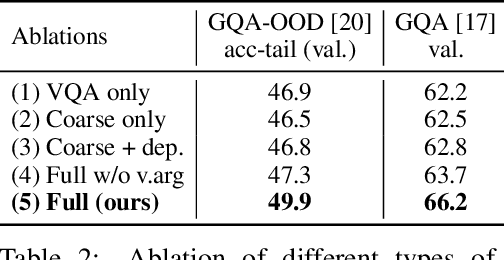
Methods for Visual Question Anwering (VQA) are notorious for leveraging dataset biases rather than performing reasoning, hindering generalization. It has been recently shown that better reasoning patterns emerge in attention layers of a state-of-the-art VQA model when they are trained on perfect (oracle) visual inputs. This provides evidence that deep neural networks can learn to reason when training conditions are favorable enough. However, transferring this learned knowledge to deployable models is a challenge, as much of it is lost during the transfer. We propose a method for knowledge transfer based on a regularization term in our loss function, supervising the sequence of required reasoning operations. We provide a theoretical analysis based on PAC-learning, showing that such program prediction can lead to decreased sample complexity under mild hypotheses. We also demonstrate the effectiveness of this approach experimentally on the GQA dataset and show its complementarity to BERT-like self-supervised pre-training.
How Transferable are Reasoning Patterns in VQA?
Apr 08, 2021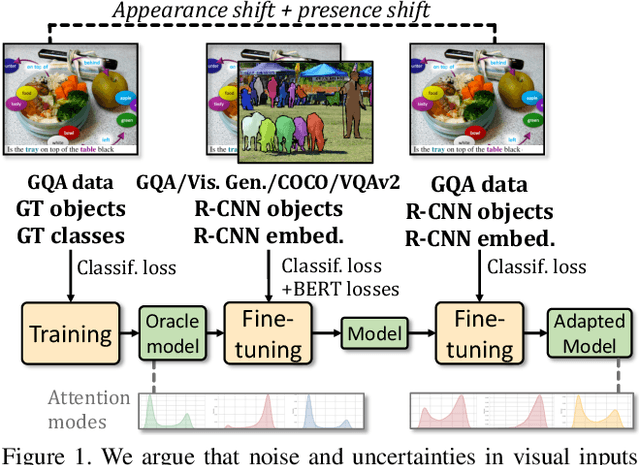

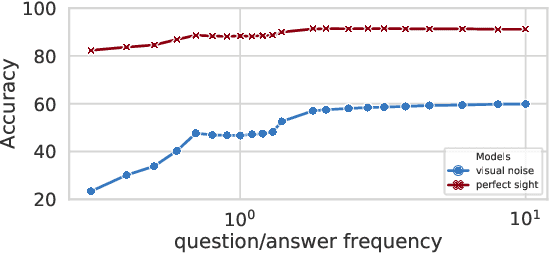

Since its inception, Visual Question Answering (VQA) is notoriously known as a task, where models are prone to exploit biases in datasets to find shortcuts instead of performing high-level reasoning. Classical methods address this by removing biases from training data, or adding branches to models to detect and remove biases. In this paper, we argue that uncertainty in vision is a dominating factor preventing the successful learning of reasoning in vision and language problems. We train a visual oracle and in a large scale study provide experimental evidence that it is much less prone to exploiting spurious dataset biases compared to standard models. We propose to study the attention mechanisms at work in the visual oracle and compare them with a SOTA Transformer-based model. We provide an in-depth analysis and visualizations of reasoning patterns obtained with an online visualization tool which we make publicly available (https://reasoningpatterns.github.io). We exploit these insights by transferring reasoning patterns from the oracle to a SOTA Transformer-based VQA model taking standard noisy visual inputs via fine-tuning. In experiments we report higher overall accuracy, as well as accuracy on infrequent answers for each question type, which provides evidence for improved generalization and a decrease of the dependency on dataset biases.
VisQA: X-raying Vision and Language Reasoning in Transformers
Apr 02, 2021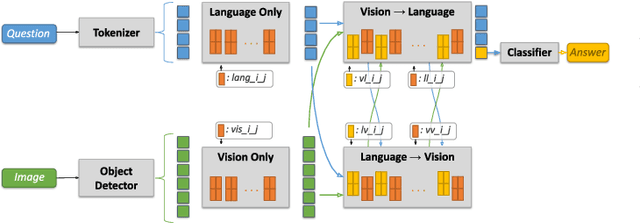
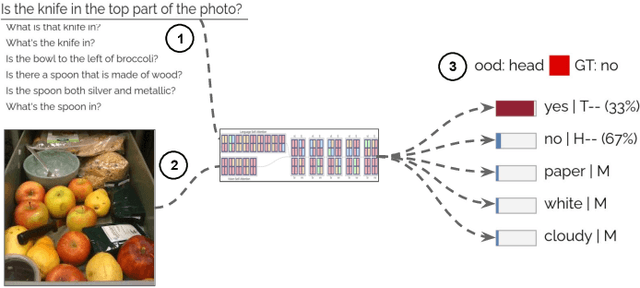
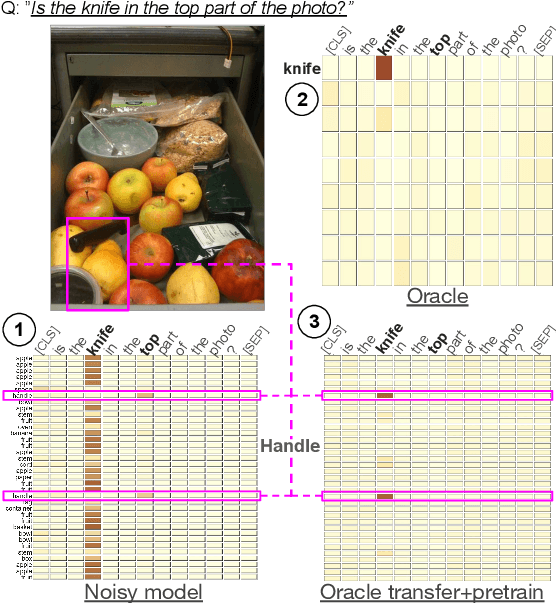
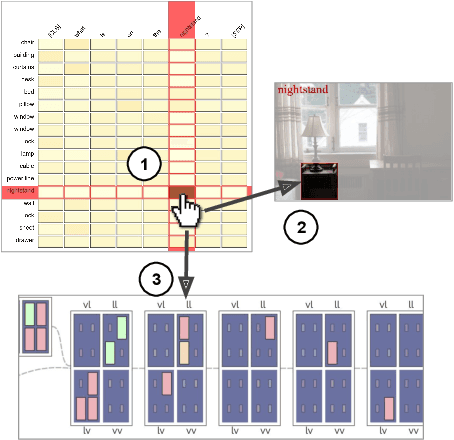
Visual Question Answering systems target answering open-ended textual questions given input images. They are a testbed for learning high-level reasoning with a primary use in HCI, for instance assistance for the visually impaired. Recent research has shown that state-of-the-art models tend to produce answers exploiting biases and shortcuts in the training data, and sometimes do not even look at the input image, instead of performing the required reasoning steps. We present VisQA, a visual analytics tool that explores this question of reasoning vs. bias exploitation. It exposes the key element of state-of-the-art neural models -- attention maps in transformers. Our working hypothesis is that reasoning steps leading to model predictions are observable from attention distributions, which are particularly useful for visualization. The design process of VisQA was motivated by well-known bias examples from the fields of deep learning and vision-language reasoning and evaluated in two ways. First, as a result of a collaboration of three fields, machine learning, vision and language reasoning, and data analytics, the work lead to a direct impact on the design and training of a neural model for VQA, improving model performance as a consequence. Second, we also report on the design of VisQA, and a goal-oriented evaluation of VisQA targeting the analysis of a model decision process from multiple experts, providing evidence that it makes the inner workings of models accessible to users.