 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoses Are Red, Violets Are Blue but Should Vqa Expect Them To?
Paper and Code
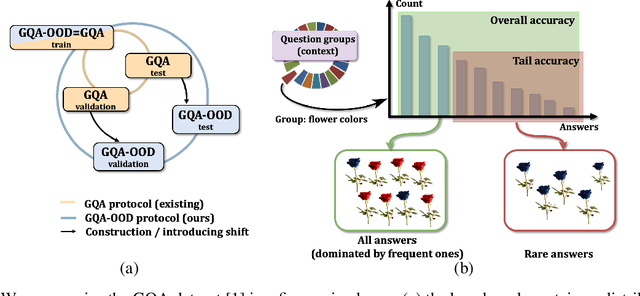


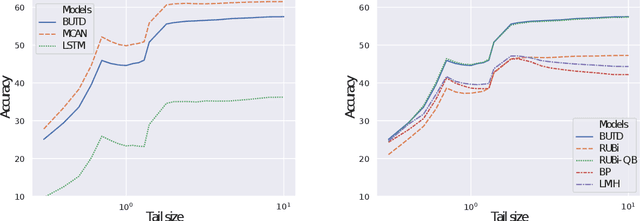
To be reliable on rare events is an important requirement for systems based on machine learning. In this work we focus on Visual Question Answering (VQA), where, in spite of recent efforts, datasets remain imbalanced, causing shortcomings of current models: tendencies to overly exploit dataset biases and struggles to generalise to unseen associations of concepts. We focus on a systemic evaluation of model error distributions and address fundamental questions: How is the prediction error distributed? What is the prediction accuracy on infrequent vs. frequent concepts? In this work, we design a new benchmark based on a fine-grained reorganization of the GQA dataset [1], which allows to precisely answer these questions. It introduces distributions shifts in both validation and test splits, which are defined on question groups and are thus tailored to each question. We performed a large-scale study and we experimentally demonstrate that several state-of-the-art VQA models, even those specifically designed for bias reduction, fail to address questions involving infrequent concepts. Furthermore, we show that the high accuracy obtained on the frequent concepts alone is mechanically increasing overall accuracy, covering up the true behavior of current VQA models.