 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn experimental study of the vision-bottleneck in VQA
Feb 14, 2022As in many tasks combining vision and language, both modalities play a crucial role in Visual Question Answering (VQA). To properly solve the task, a given model should both understand the content of the proposed image and the nature of the question. While the fusion between modalities, which is another obviously important part of the problem, has been highly studied, the vision part has received less attention in recent work. Current state-of-the-art methods for VQA mainly rely on off-the-shelf object detectors delivering a set of object bounding boxes and embeddings, which are then combined with question word embeddings through a reasoning module. In this paper, we propose an in-depth study of the vision-bottleneck in VQA, experimenting with both the quantity and quality of visual objects extracted from images. We also study the impact of two methods to incorporate the information about objects necessary for answering a question, in the reasoning module directly, and earlier in the object selection stage. This work highlights the importance of vision in the context of VQA, and the interest of tailoring vision methods used in VQA to the task at hand.
Supervising the Transfer of Reasoning Patterns in VQA
Jun 10, 2021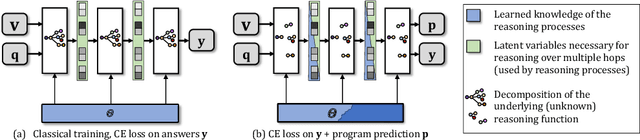

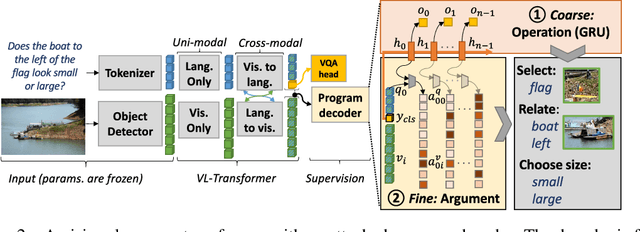
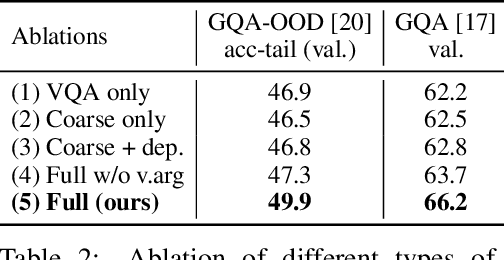
Methods for Visual Question Anwering (VQA) are notorious for leveraging dataset biases rather than performing reasoning, hindering generalization. It has been recently shown that better reasoning patterns emerge in attention layers of a state-of-the-art VQA model when they are trained on perfect (oracle) visual inputs. This provides evidence that deep neural networks can learn to reason when training conditions are favorable enough. However, transferring this learned knowledge to deployable models is a challenge, as much of it is lost during the transfer. We propose a method for knowledge transfer based on a regularization term in our loss function, supervising the sequence of required reasoning operations. We provide a theoretical analysis based on PAC-learning, showing that such program prediction can lead to decreased sample complexity under mild hypotheses. We also demonstrate the effectiveness of this approach experimentally on the GQA dataset and show its complementarity to BERT-like self-supervised pre-training.
How Transferable are Reasoning Patterns in VQA?
Apr 08, 2021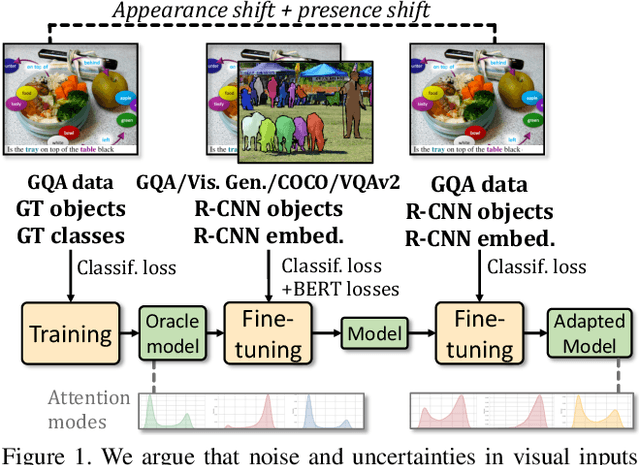

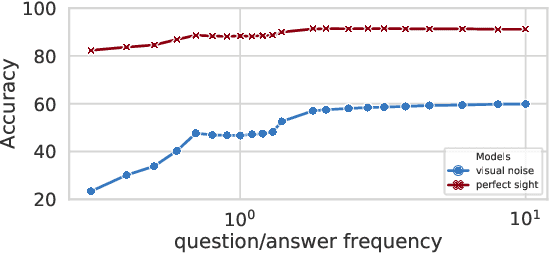

Since its inception, Visual Question Answering (VQA) is notoriously known as a task, where models are prone to exploit biases in datasets to find shortcuts instead of performing high-level reasoning. Classical methods address this by removing biases from training data, or adding branches to models to detect and remove biases. In this paper, we argue that uncertainty in vision is a dominating factor preventing the successful learning of reasoning in vision and language problems. We train a visual oracle and in a large scale study provide experimental evidence that it is much less prone to exploiting spurious dataset biases compared to standard models. We propose to study the attention mechanisms at work in the visual oracle and compare them with a SOTA Transformer-based model. We provide an in-depth analysis and visualizations of reasoning patterns obtained with an online visualization tool which we make publicly available (https://reasoningpatterns.github.io). We exploit these insights by transferring reasoning patterns from the oracle to a SOTA Transformer-based VQA model taking standard noisy visual inputs via fine-tuning. In experiments we report higher overall accuracy, as well as accuracy on infrequent answers for each question type, which provides evidence for improved generalization and a decrease of the dependency on dataset biases.
VisQA: X-raying Vision and Language Reasoning in Transformers
Apr 02, 2021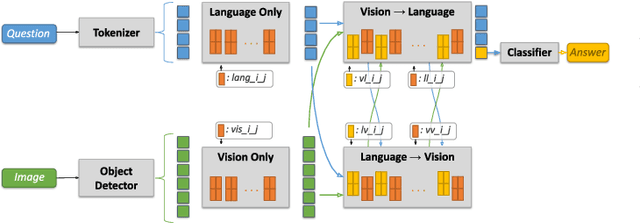
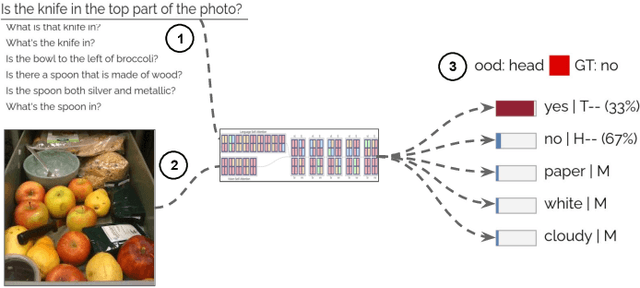
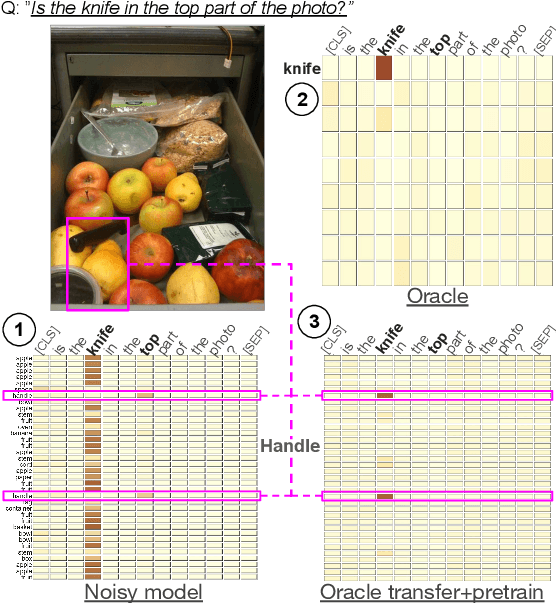
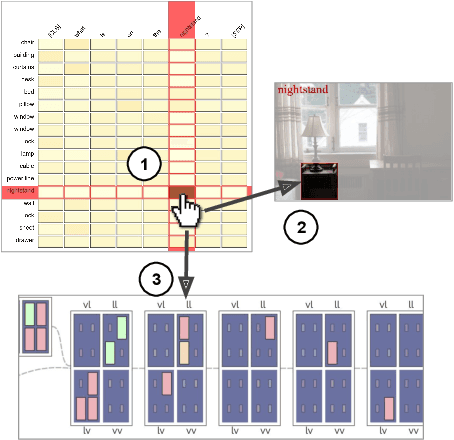
Visual Question Answering systems target answering open-ended textual questions given input images. They are a testbed for learning high-level reasoning with a primary use in HCI, for instance assistance for the visually impaired. Recent research has shown that state-of-the-art models tend to produce answers exploiting biases and shortcuts in the training data, and sometimes do not even look at the input image, instead of performing the required reasoning steps. We present VisQA, a visual analytics tool that explores this question of reasoning vs. bias exploitation. It exposes the key element of state-of-the-art neural models -- attention maps in transformers. Our working hypothesis is that reasoning steps leading to model predictions are observable from attention distributions, which are particularly useful for visualization. The design process of VisQA was motivated by well-known bias examples from the fields of deep learning and vision-language reasoning and evaluated in two ways. First, as a result of a collaboration of three fields, machine learning, vision and language reasoning, and data analytics, the work lead to a direct impact on the design and training of a neural model for VQA, improving model performance as a consequence. Second, we also report on the design of VisQA, and a goal-oriented evaluation of VisQA targeting the analysis of a model decision process from multiple experts, providing evidence that it makes the inner workings of models accessible to users.
Estimating semantic structure for the VQA answer space
Jun 10, 2020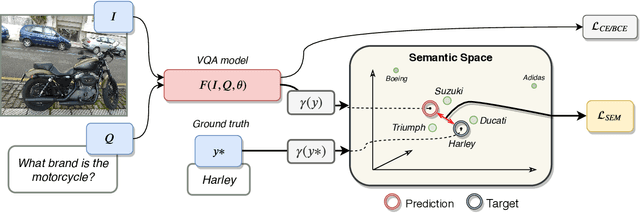
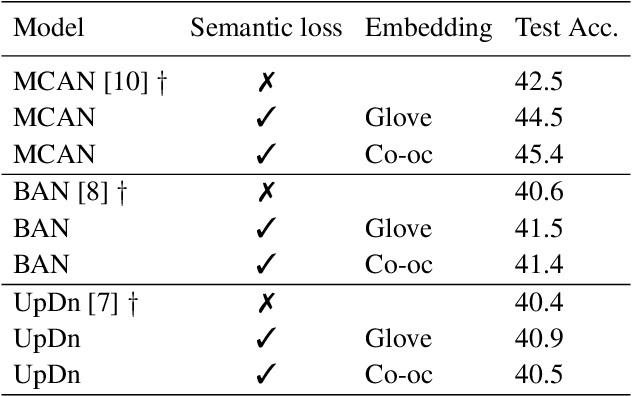

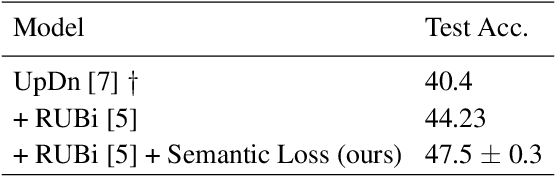
Since its appearance, Visual Question Answering (VQA, i.e. answering a question posed over an image), has always been treated as a classification problem over a set of predefined answers. Despite its convenience, this classification approach poorly reflects the semantics of the problem limiting the answering to a choice between independent proposals, without taking into account the similarity between them (e.g. equally penalizing for answering cat or German shepherd instead of dog). We address this issue by proposing (1) two measures of proximity between VQA classes, and (2) a corresponding loss which takes into account the estimated proximity. This significantly improves the generalization of VQA models by reducing their language bias. In particular, we show that our approach is completely model-agnostic since it allows consistent improvements with three different VQA models. Finally, by combining our method with a language bias reduction approach, we report SOTA-level performance on the challenging VQAv2-CP dataset.
Roses Are Red, Violets Are Blue but Should Vqa Expect Them To?
Jun 09, 2020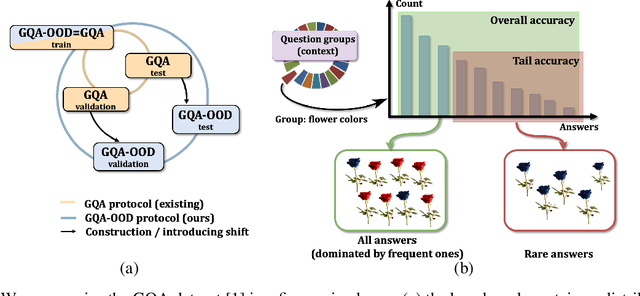


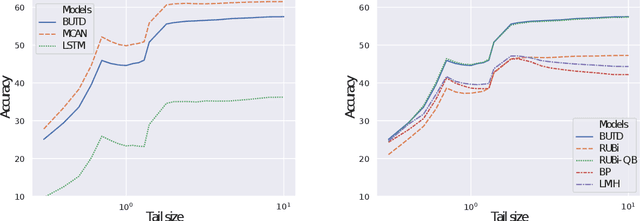
To be reliable on rare events is an important requirement for systems based on machine learning. In this work we focus on Visual Question Answering (VQA), where, in spite of recent efforts, datasets remain imbalanced, causing shortcomings of current models: tendencies to overly exploit dataset biases and struggles to generalise to unseen associations of concepts. We focus on a systemic evaluation of model error distributions and address fundamental questions: How is the prediction error distributed? What is the prediction accuracy on infrequent vs. frequent concepts? In this work, we design a new benchmark based on a fine-grained reorganization of the GQA dataset [1], which allows to precisely answer these questions. It introduces distributions shifts in both validation and test splits, which are defined on question groups and are thus tailored to each question. We performed a large-scale study and we experimentally demonstrate that several state-of-the-art VQA models, even those specifically designed for bias reduction, fail to address questions involving infrequent concepts. Furthermore, we show that the high accuracy obtained on the frequent concepts alone is mechanically increasing overall accuracy, covering up the true behavior of current VQA models.
Weak Supervision helps Emergence of Word-Object Alignment and improves Vision-Language Tasks
Dec 06, 2019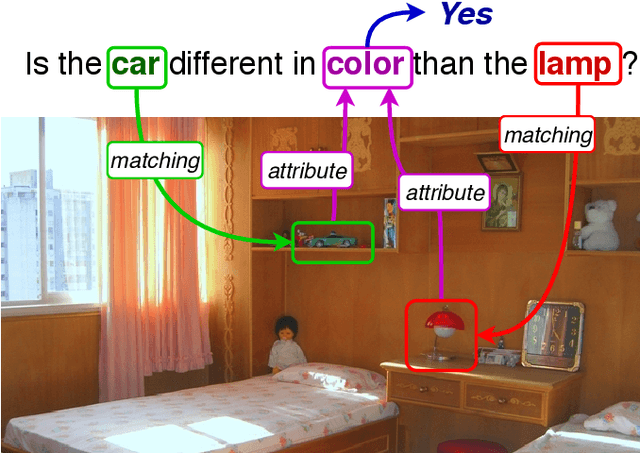
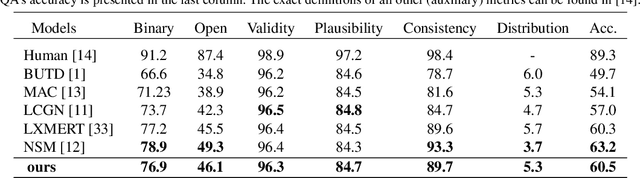
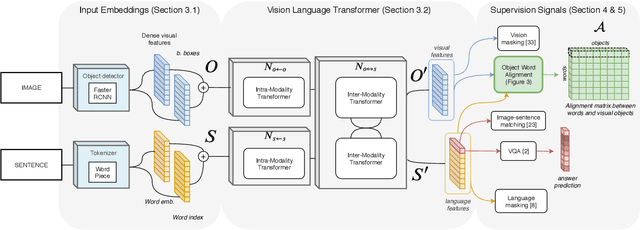

The large adoption of the self-attention (i.e. transformer model) and BERT-like training principles has recently resulted in a number of high performing models on a large panoply of vision-and-language problems (such as Visual Question Answering (VQA), image retrieval, etc.). In this paper we claim that these State-Of-The-Art (SOTA) approaches perform reasonably well in structuring information inside a single modality but, despite their impressive performances , they tend to struggle to identify fine-grained inter-modality relationships. Indeed, such relations are frequently assumed to be implicitly learned during training from application-specific losses, mostly cross-entropy for classification. While most recent works provide inductive bias for inter-modality relationships via cross attention modules, in this work, we demonstrate (1) that the latter assumption does not hold, i.e. modality alignment does not necessarily emerge automatically, and (2) that adding weak supervision for alignment between visual objects and words improves the quality of the learned models on tasks requiring reasoning. In particular , we integrate an object-word alignment loss into SOTA vision-language reasoning models and evaluate it on two tasks VQA and Language-driven Comparison of Images. We show that the proposed fine-grained inter-modality supervision significantly improves performance on both tasks. In particular, this new learning signal allows obtaining SOTA-level performances on GQA dataset (VQA task) with pre-trained models without finetuning on the task, and a new SOTA on NLVR2 dataset (Language-driven Comparison of Images). Finally, we also illustrate the impact of the contribution on the models reasoning by visualizing attention distributions.
MFAS: Multimodal Fusion Architecture Search
Mar 15, 2019

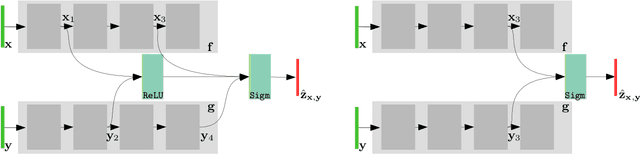

We tackle the problem of finding good architectures for multimodal classification problems. We propose a novel and generic search space that spans a large number of possible fusion architectures. In order to find an optimal architecture for a given dataset in the proposed search space, we leverage an efficient sequential model-based exploration approach that is tailored for the problem. We demonstrate the value of posing multimodal fusion as a neural architecture search problem by extensive experimentation on a toy dataset and two other real multimodal datasets. We discover fusion architectures that exhibit state-of-the-art performance for problems with different domain and dataset size, including the NTU RGB+D dataset, the largest multi-modal action recognition dataset available.
Efficient Progressive Neural Architecture Search
Aug 01, 2018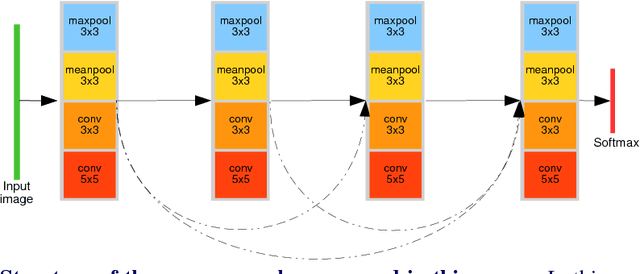
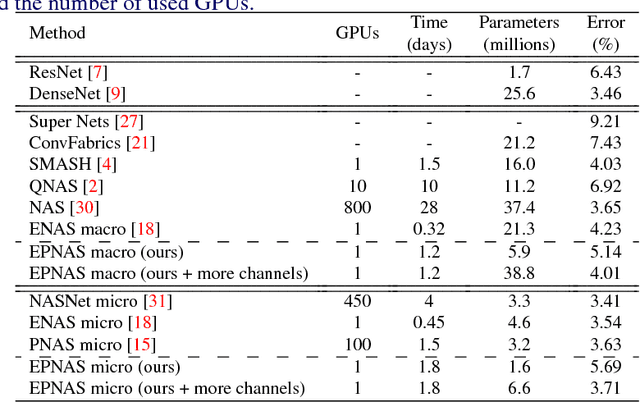

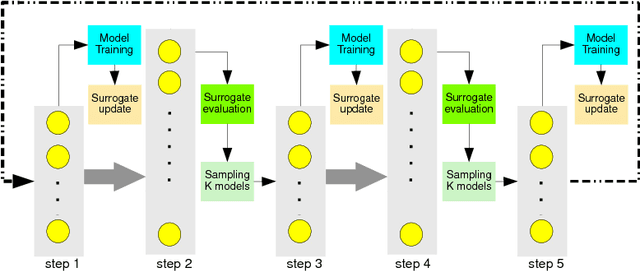
This paper addresses the difficult problem of finding an optimal neural architecture design for a given image classification task. We propose a method that aggregates two main results of the previous state-of-the-art in neural architecture search. These are, appealing to the strong sampling efficiency of a search scheme based on sequential model-based optimization (SMBO), and increasing training efficiency by sharing weights among sampled architectures. Sequential search has previously demonstrated its capabilities to find state-of-the-art neural architectures for image classification. However, its computational cost remains high, even unreachable under modest computational settings. Affording SMBO with weight-sharing alleviates this problem. On the other hand, progressive search with SMBO is inherently greedy, as it leverages a learned surrogate function to predict the validation error of neural architectures. This prediction is directly used to rank the sampled neural architectures. We propose to attenuate the greediness of the original SMBO method by relaxing the role of the surrogate function so it predicts architecture sampling probability instead. We demonstrate with experiments on the CIFAR-10 dataset that our method, denominated Efficient progressive neural architecture search (EPNAS), leads to increased search efficiency, while retaining competitiveness of found architectures.
Face Aging With Conditional Generative Adversarial Networks
May 30, 2017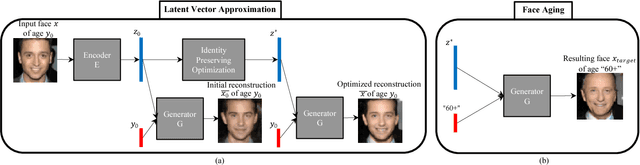


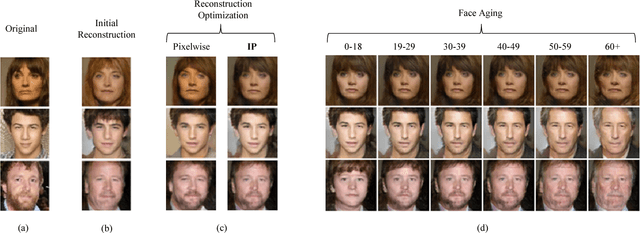
It has been recently shown that Generative Adversarial Networks (GANs) can produce synthetic images of exceptional visual fidelity. In this work, we propose the GAN-based method for automatic face aging. Contrary to previous works employing GANs for altering of facial attributes, we make a particular emphasize on preserving the original person's identity in the aged version of his/her face. To this end, we introduce a novel approach for "Identity-Preserving" optimization of GAN's latent vectors. The objective evaluation of the resulting aged and rejuvenated face images by the state-of-the-art face recognition and age estimation solutions demonstrate the high potential of the proposed method.