 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeak Supervision helps Emergence of Word-Object Alignment and improves Vision-Language Tasks
Paper and Code
Dec 06, 2019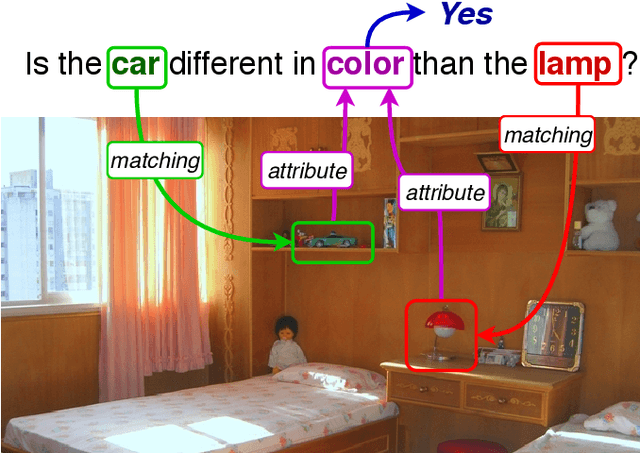
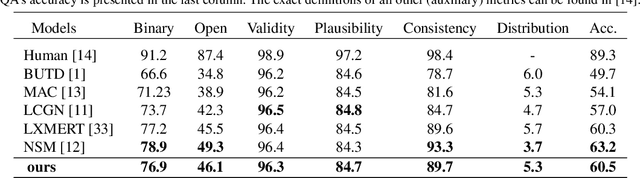
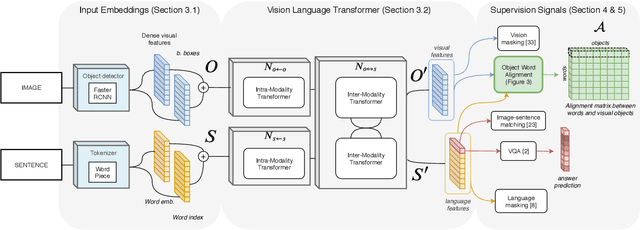

The large adoption of the self-attention (i.e. transformer model) and BERT-like training principles has recently resulted in a number of high performing models on a large panoply of vision-and-language problems (such as Visual Question Answering (VQA), image retrieval, etc.). In this paper we claim that these State-Of-The-Art (SOTA) approaches perform reasonably well in structuring information inside a single modality but, despite their impressive performances , they tend to struggle to identify fine-grained inter-modality relationships. Indeed, such relations are frequently assumed to be implicitly learned during training from application-specific losses, mostly cross-entropy for classification. While most recent works provide inductive bias for inter-modality relationships via cross attention modules, in this work, we demonstrate (1) that the latter assumption does not hold, i.e. modality alignment does not necessarily emerge automatically, and (2) that adding weak supervision for alignment between visual objects and words improves the quality of the learned models on tasks requiring reasoning. In particular , we integrate an object-word alignment loss into SOTA vision-language reasoning models and evaluate it on two tasks VQA and Language-driven Comparison of Images. We show that the proposed fine-grained inter-modality supervision significantly improves performance on both tasks. In particular, this new learning signal allows obtaining SOTA-level performances on GQA dataset (VQA task) with pre-trained models without finetuning on the task, and a new SOTA on NLVR2 dataset (Language-driven Comparison of Images). Finally, we also illustrate the impact of the contribution on the models reasoning by visualizing attention distributions.