 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBOGausS: Better Optimized Gaussian Splatting
Apr 02, 2025
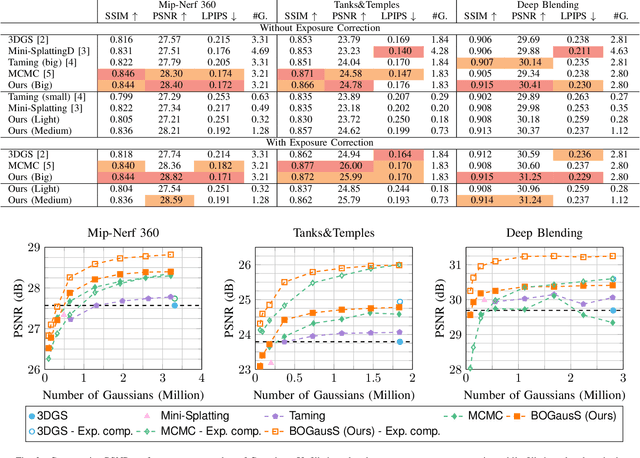
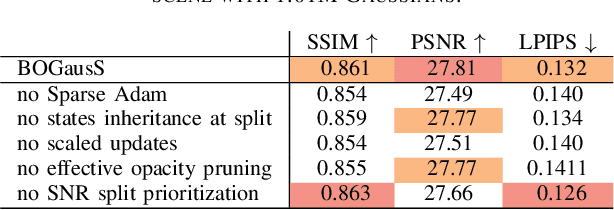
3D Gaussian Splatting (3DGS) proposes an efficient solution for novel view synthesis. Its framework provides fast and high-fidelity rendering. Although less complex than other solutions such as Neural Radiance Fields (NeRF), there are still some challenges building smaller models without sacrificing quality. In this study, we perform a careful analysis of 3DGS training process and propose a new optimization methodology. Our Better Optimized Gaussian Splatting (BOGausS) solution is able to generate models up to ten times lighter than the original 3DGS with no quality degradation, thus significantly boosting the performance of Gaussian Splatting compared to the state of the art.
Adaptive Dimension Reduction and Variational Inference for Transductive Few-Shot Classification
Sep 18, 2022

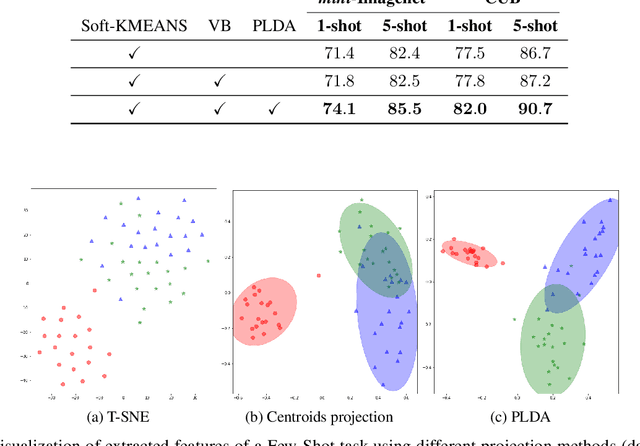
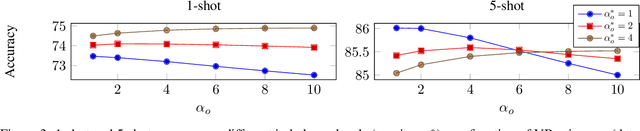
Transductive Few-Shot learning has gained increased attention nowadays considering the cost of data annotations along with the increased accuracy provided by unlabelled samples in the domain of few shot. Especially in Few-Shot Classification (FSC), recent works explore the feature distributions aiming at maximizing likelihoods or posteriors with respect to the unknown parameters. Following this vein, and considering the parallel between FSC and clustering, we seek for better taking into account the uncertainty in estimation due to lack of data, as well as better statistical properties of the clusters associated with each class. Therefore in this paper we propose a new clustering method based on Variational Bayesian inference, further improved by Adaptive Dimension Reduction based on Probabilistic Linear Discriminant Analysis. Our proposed method significantly improves accuracy in the realistic unbalanced transductive setting on various Few-Shot benchmarks when applied to features used in previous studies, with a gain of up to $6\%$ in accuracy. In addition, when applied to balanced setting, we obtain very competitive results without making use of the class-balance artefact which is disputable for practical use cases. We also provide the performance of our method on a high performing pretrained backbone, with the reported results further surpassing the current state-of-the-art accuracy, suggesting the genericity of the proposed method.
EASY: Ensemble Augmented-Shot Y-shaped Learning: State-Of-The-Art Few-Shot Classification with Simple Ingredients
Feb 07, 2022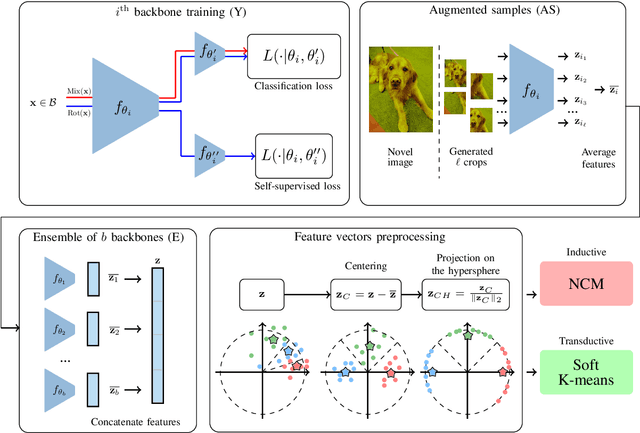
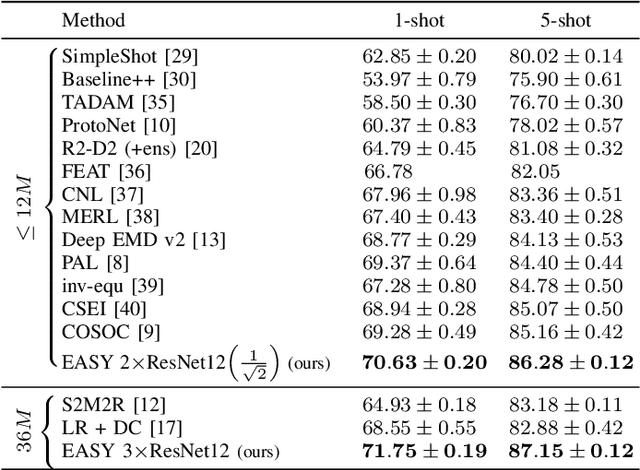
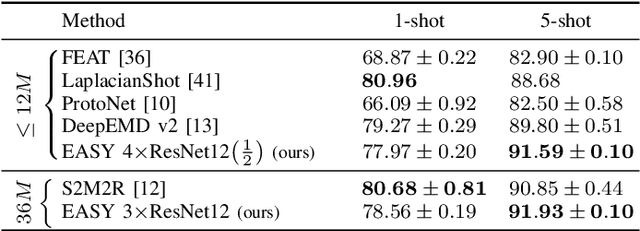

Few-shot learning aims at leveraging knowledge learned by one or more deep learning models, in order to obtain good classification performance on new problems, where only a few labeled samples per class are available. Recent years have seen a fair number of works in the field, introducing methods with numerous ingredients. A frequent problem, though, is the use of suboptimally trained models to extract knowledge, leading to interrogations on whether proposed approaches bring gains compared to using better initial models without the introduced ingredients. In this work, we propose a simple methodology, that reaches or even beats state of the art performance on multiple standardized benchmarks of the field, while adding almost no hyperparameters or parameters to those used for training the initial deep learning models on the generic dataset. This methodology offers a new baseline on which to propose (and fairly compare) new techniques or adapt existing ones.
Squeezing Backbone Feature Distributions to the Max for Efficient Few-Shot Learning
Oct 18, 2021
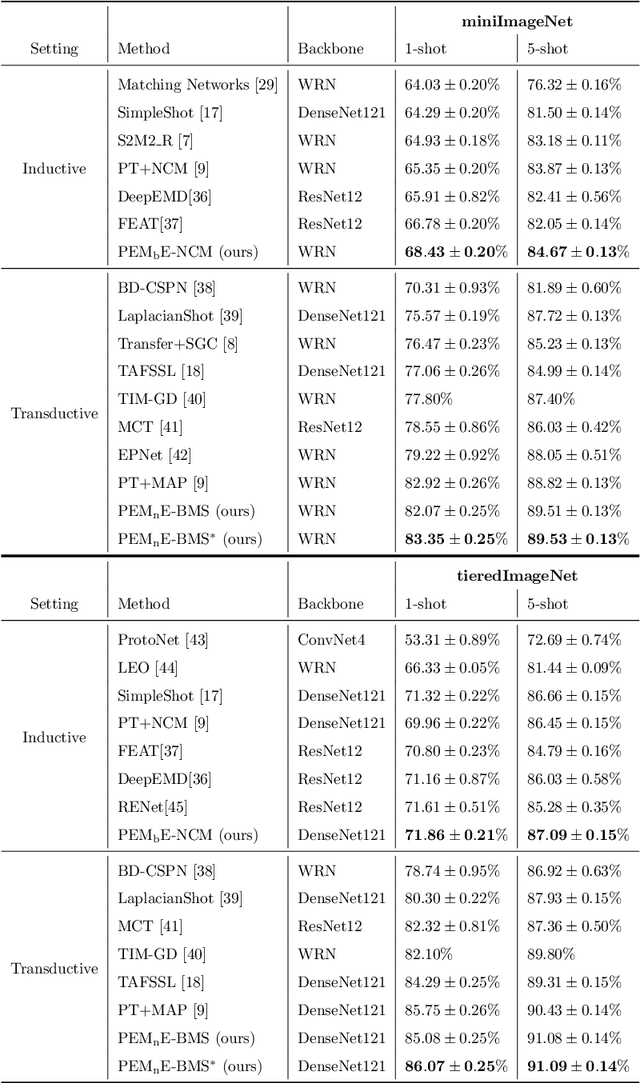
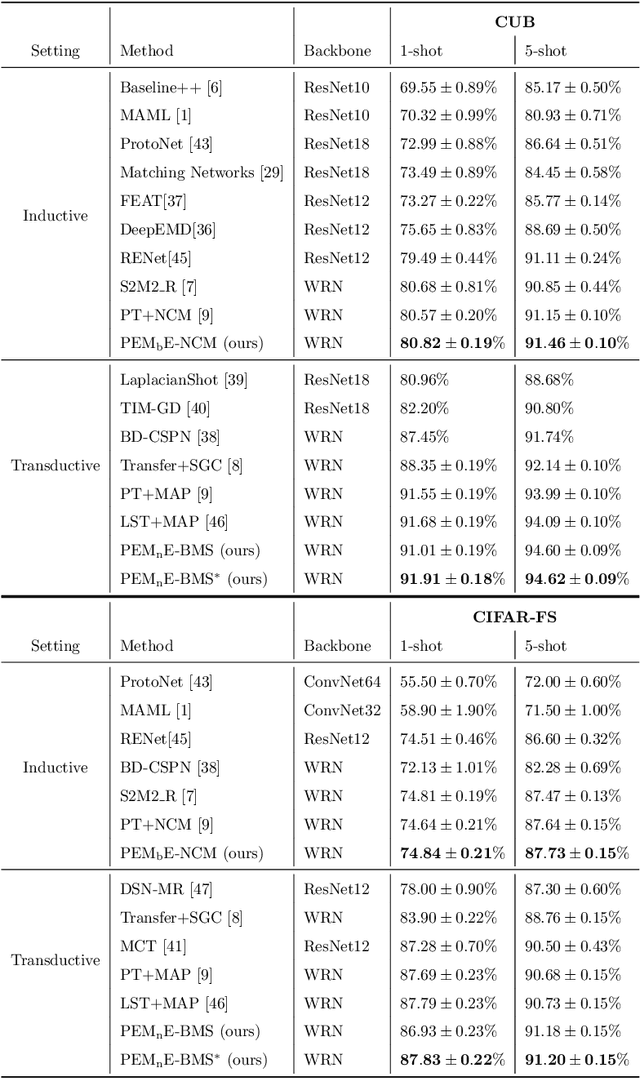

Few-shot classification is a challenging problem due to the uncertainty caused by using few labelled samples. In the past few years, many methods have been proposed with the common aim of transferring knowledge acquired on a previously solved task, what is often achieved by using a pretrained feature extractor. Following this vein, in this paper we propose a novel transfer-based method which aims at processing the feature vectors so that they become closer to Gaussian-like distributions, resulting in increased accuracy. In the case of transductive few-shot learning where unlabelled test samples are available during training, we also introduce an optimal-transport inspired algorithm to boost even further the achieved performance. Using standardized vision benchmarks, we show the ability of the proposed methodology to achieve state-of-the-art accuracy with various datasets, backbone architectures and few-shot settings.
Leveraging the Feature Distribution in Transfer-based Few-Shot Learning
Jun 06, 2020
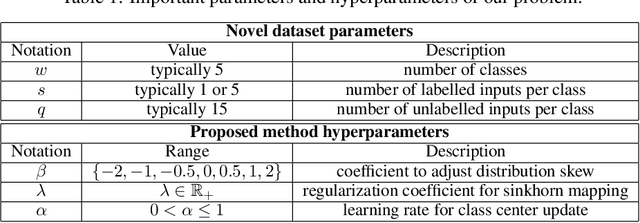


Few-shot classification is a challenging problem due to the uncertainty caused by using few labelled samples. In the past few years, transfer-based methods have proved to achieve the best performance, thanks to well-thought-out backbone architectures combined with efficient postprocessing steps. Following this vein, in this paper we propose a transfer-based novel method that builds on two steps: 1) preprocessing the feature vectors so that they become closer to Gaussian-like distributions, and 2) leveraging this preprocessing using an optimal-transport inspired algorithm. Using standardized vision benchmarks, we prove the ability of the proposed methodology to achieve state-of-the-art accuracy with various datasets, backbone architectures and few-shot settings.
Exploiting Unsupervised Inputs for Accurate Few-Shot Classification
Feb 26, 2020


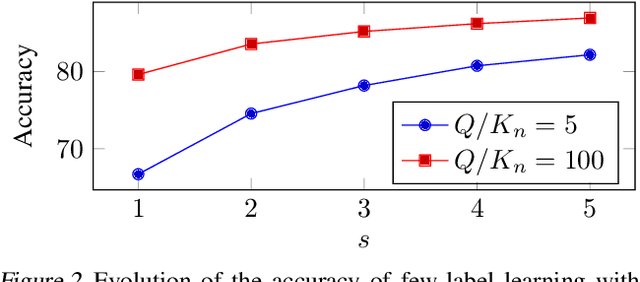
In few-shot classification, the aim is to learn models able to discriminate classes with only a small number of labelled examples. Most of the literature considers the problem of labelling a single unknown input at a time. Instead, it can be beneficial to consider a setting where a batch of unlabelled inputs are treated conjointly and non-independently. In this vein, we propose a method able to exploit three levels of information: a) feature extractors pretrained on generic datasets, b) few labelled examples of classes to discriminate and c) other available unlabelled inputs. If for a), we use state-of-the-art approaches, we introduce the use of simplified graph convolutions to perform b) and c) together. Our proposed model reaches state-of-the-art accuracy with a $6-11\%$ increase compared to available alternatives on standard few-shot vision classification datasets.
Towards a General Model of Knowledge for Facial Analysis by Multi-Source Transfer Learning
Nov 08, 2019

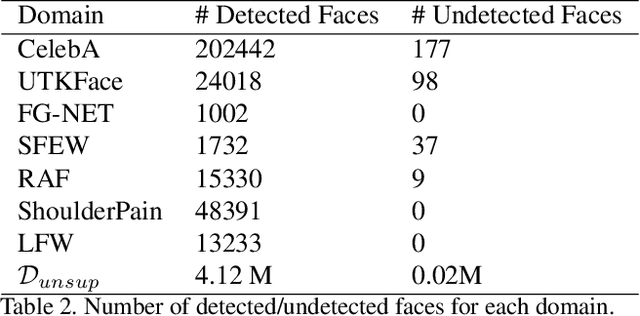

This paper proposes a step toward obtaining general models of knowledge for facial analysis, by addressing the question of multi-source transfer learning. More precisely, the proposed approach consists in two successive training steps: the first one consists in applying a combination operator to define a common embedding for the multiple sources materialized by different existing trained models. The proposed operator relies on an auto-encoder, trained on a large dataset, efficient both in terms of compression ratio and transfer learning performance. In a second step we exploit a distillation approach to obtain a lightweight student model mimicking the collection of the fused existing models. This model outperforms its teacher on novel tasks, achieving results on par with state-of-the-art methods on 15 facial analysis tasks (and domains), at an affordable training cost. Moreover, this student has 75 times less parameters than the original teacher and can be applied to a variety of novel face-related tasks.
MFAS: Multimodal Fusion Architecture Search
Mar 15, 2019

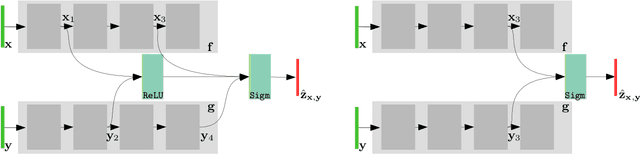

We tackle the problem of finding good architectures for multimodal classification problems. We propose a novel and generic search space that spans a large number of possible fusion architectures. In order to find an optimal architecture for a given dataset in the proposed search space, we leverage an efficient sequential model-based exploration approach that is tailored for the problem. We demonstrate the value of posing multimodal fusion as a neural architecture search problem by extensive experimentation on a toy dataset and two other real multimodal datasets. We discover fusion architectures that exhibit state-of-the-art performance for problems with different domain and dataset size, including the NTU RGB+D dataset, the largest multi-modal action recognition dataset available.
Multi-Level Sensor Fusion with Deep Learning
Nov 05, 2018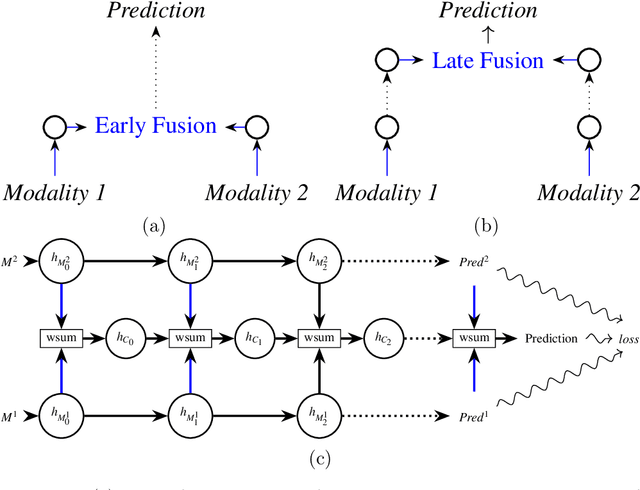


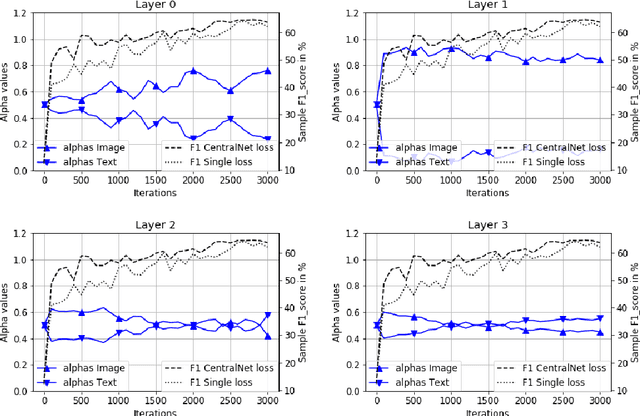
In the context of deep learning, this article presents an original deep network, namely CentralNet, for the fusion of information coming from different sensors. This approach is designed to efficiently and automatically balance the trade-off between early and late fusion (i.e. between the fusion of low-level vs high-level information). More specifically, at each level of abstraction-the different levels of deep networks-uni-modal representations of the data are fed to a central neural network which combines them into a common embedding. In addition, a multi-objective regularization is also introduced, helping to both optimize the central network and the unimodal networks. Experiments on four multimodal datasets not only show state-of-the-art performance, but also demonstrate that CentralNet can actually choose the best possible fusion strategy for a given problem.
The Many Moods of Emotion
Oct 31, 2018

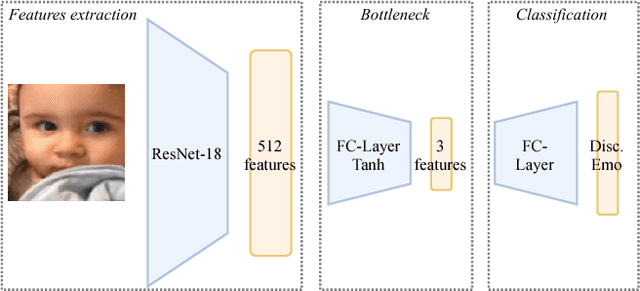

This paper presents a novel approach to the facial expression generation problem. Building upon the assumption of the psychological community that emotion is intrinsically continuous, we first design our own continuous emotion representation with a 3-dimensional latent space issued from a neural network trained on discrete emotion classification. The so-obtained representation can be used to annotate large in the wild datasets and later used to trained a Generative Adversarial Network. We first show that our model is able to map back to discrete emotion classes with a objectively and subjectively better quality of the images than usual discrete approaches. But also that we are able to pave the larger space of possible facial expressions, generating the many moods of emotion. Moreover, two axis in this space may be found to generate similar expression changes as in traditional continuous representations such as arousal-valence. Finally we show from visual interpretation, that the third remaining dimension is highly related to the well-known dominance dimension from psychology.