 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSqueezing Backbone Feature Distributions to the Max for Efficient Few-Shot Learning
Paper and Code

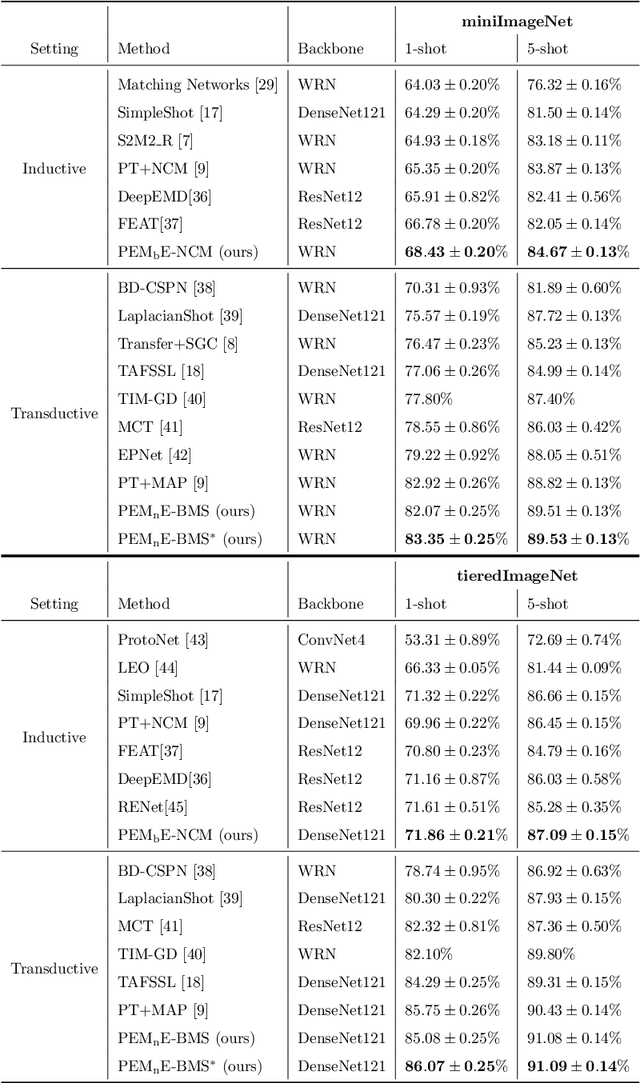
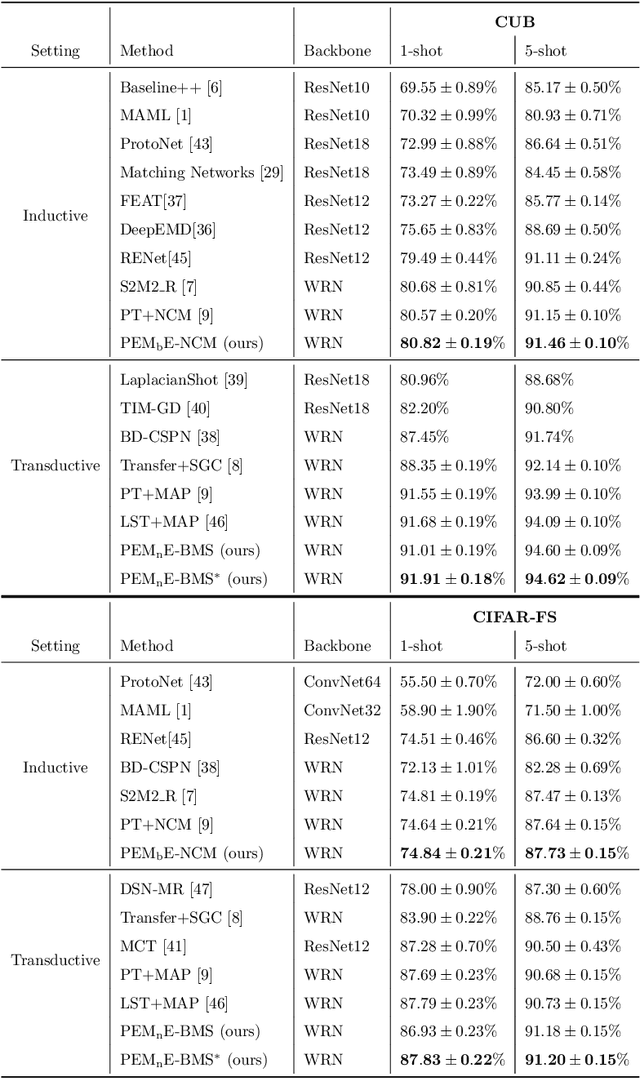

Few-shot classification is a challenging problem due to the uncertainty caused by using few labelled samples. In the past few years, many methods have been proposed with the common aim of transferring knowledge acquired on a previously solved task, what is often achieved by using a pretrained feature extractor. Following this vein, in this paper we propose a novel transfer-based method which aims at processing the feature vectors so that they become closer to Gaussian-like distributions, resulting in increased accuracy. In the case of transductive few-shot learning where unlabelled test samples are available during training, we also introduce an optimal-transport inspired algorithm to boost even further the achieved performance. Using standardized vision benchmarks, we show the ability of the proposed methodology to achieve state-of-the-art accuracy with various datasets, backbone architectures and few-shot settings.