 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREVE: A Foundation Model for EEG -- Adapting to Any Setup with Large-Scale Pretraining on 25,000 Subjects
Oct 24, 2025Foundation models have transformed AI by reducing reliance on task-specific data through large-scale pretraining. While successful in language and vision, their adoption in EEG has lagged due to the heterogeneity of public datasets, which are collected under varying protocols, devices, and electrode configurations. Existing EEG foundation models struggle to generalize across these variations, often restricting pretraining to a single setup, resulting in suboptimal performance, in particular under linear probing. We present REVE (Representation for EEG with Versatile Embeddings), a pretrained model explicitly designed to generalize across diverse EEG signals. REVE introduces a novel 4D positional encoding scheme that enables it to process signals of arbitrary length and electrode arrangement. Using a masked autoencoding objective, we pretrain REVE on over 60,000 hours of EEG data from 92 datasets spanning 25,000 subjects, representing the largest EEG pretraining effort to date. REVE achieves state-of-the-art results on 10 downstream EEG tasks, including motor imagery classification, seizure detection, sleep staging, cognitive load estimation, and emotion recognition. With little to no fine-tuning, it demonstrates strong generalization, and nuanced spatio-temporal modeling. We release code, pretrained weights, and tutorials to support standardized EEG research and accelerate progress in clinical neuroscience.
Anomalous Samples for Few-Shot Anomaly Detection
Jul 31, 2025Several anomaly detection and classification methods rely on large amounts of non-anomalous or "normal" samples under the assump- tion that anomalous data is typically harder to acquire. This hypothesis becomes questionable in Few-Shot settings, where as little as one anno- tated sample can make a significant difference. In this paper, we tackle the question of utilizing anomalous samples in training a model for bi- nary anomaly classification. We propose a methodology that incorporates anomalous samples in a multi-score anomaly detection score leveraging recent Zero-Shot and memory-based techniques. We compare the utility of anomalous samples to that of regular samples and study the benefits and limitations of each. In addition, we propose an augmentation-based validation technique to optimize the aggregation of the different anomaly scores and demonstrate its effectiveness on popular industrial anomaly detection datasets.
Object-Centric Cropping for Visual Few-Shot Classification
Jul 31, 2025In the domain of Few-Shot Image Classification, operating with as little as one example per class, the presence of image ambiguities stemming from multiple objects or complex backgrounds can significantly deteriorate performance. Our research demonstrates that incorporating additional information about the local positioning of an object within its image markedly enhances classification across established benchmarks. More importantly, we show that a significant fraction of the improvement can be achieved through the use of the Segment Anything Model, requiring only a pixel of the object of interest to be pointed out, or by employing fully unsupervised foreground object extraction methods.
ProKeR: A Kernel Perspective on Few-Shot Adaptation of Large Vision-Language Models
Jan 19, 2025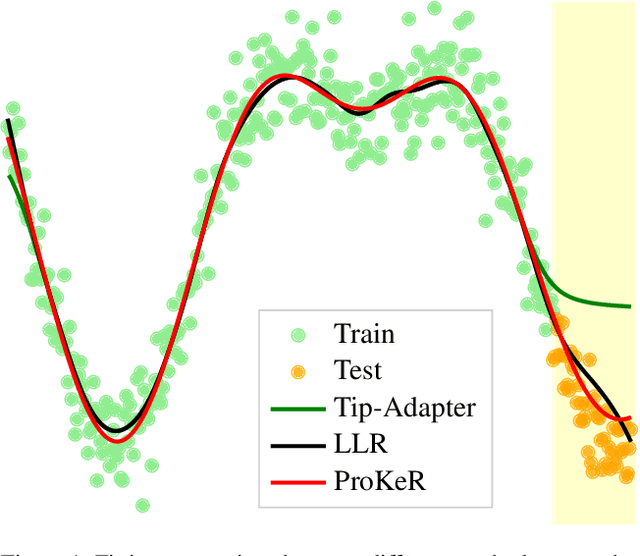
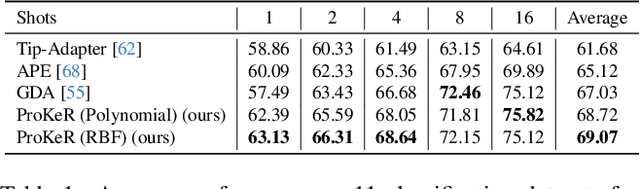
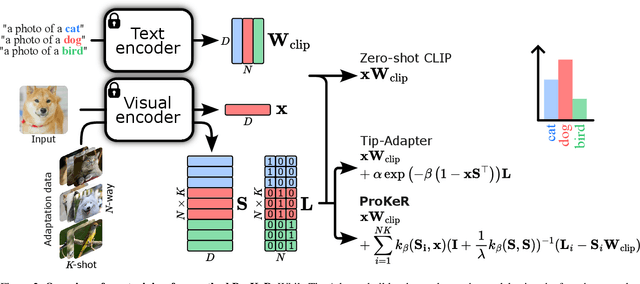
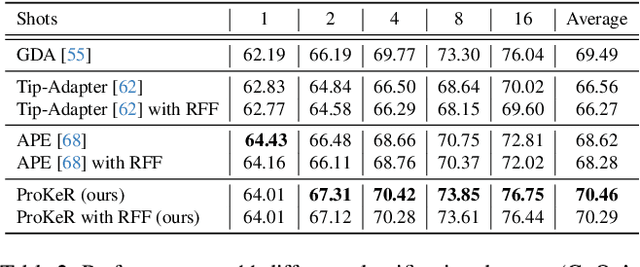
The growing popularity of Contrastive Language-Image Pretraining (CLIP) has led to its widespread application in various visual downstream tasks. To enhance CLIP's effectiveness and versatility, efficient few-shot adaptation techniques have been widely adopted. Among these approaches, training-free methods, particularly caching methods exemplified by Tip-Adapter, have gained attention for their lightweight adaptation without the need for additional fine-tuning. In this paper, we revisit Tip-Adapter from a kernel perspective, showing that caching methods function as local adapters and are connected to a well-established kernel literature. Drawing on this insight, we offer a theoretical understanding of how these methods operate and suggest multiple avenues for enhancing the Tip-Adapter baseline. Notably, our analysis shows the importance of incorporating global information in local adapters. Therefore, we subsequently propose a global method that learns a proximal regularizer in a reproducing kernel Hilbert space (RKHS) using CLIP as a base learner. Our method, which we call ProKeR (Proximal Kernel ridge Regression), has a closed form solution and achieves state-of-the-art performances across 11 datasets in the standard few-shot adaptation benchmark.
Oops, I Sampled it Again: Reinterpreting Confidence Intervals in Few-Shot Learning
Sep 04, 2024



The predominant method for computing confidence intervals (CI) in few-shot learning (FSL) is based on sampling the tasks with replacement, i.e.\ allowing the same samples to appear in multiple tasks. This makes the CI misleading in that it takes into account the randomness of the sampler but not the data itself. To quantify the extent of this problem, we conduct a comparative analysis between CIs computed with and without replacement. These reveal a notable underestimation by the predominant method. This observation calls for a reevaluation of how we interpret confidence intervals and the resulting conclusions in FSL comparative studies. Our research demonstrates that the use of paired tests can partially address this issue. Additionally, we explore methods to further reduce the (size of the) CI by strategically sampling tasks of a specific size. We also introduce a new optimized benchmark, which can be accessed at https://github.com/RafLaf/FSL-benchmark-again
LLM meets Vision-Language Models for Zero-Shot One-Class Classification
Apr 02, 2024We consider the problem of zero-shot one-class visual classification. In this setting, only the label of the target class is available, and the goal is to discriminate between positive and negative query samples without requiring any validation example from the target task. We propose a two-step solution that first queries large language models for visually confusing objects and then relies on vision-language pre-trained models (e.g., CLIP) to perform classification. By adapting large-scale vision benchmarks, we demonstrate the ability of the proposed method to outperform adapted off-the-shelf alternatives in this setting. Namely, we propose a realistic benchmark where negative query samples are drawn from the same original dataset as positive ones, including a granularity-controlled version of iNaturalist, where negative samples are at a fixed distance in the taxonomy tree from the positive ones. Our work shows that it is possible to discriminate between a single category and other semantically related ones using only its label
Unsupervised Adaptive Deep Learning Method For BCI Motor Imagery Decoding
Mar 15, 2024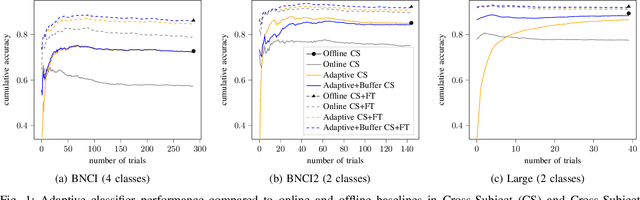
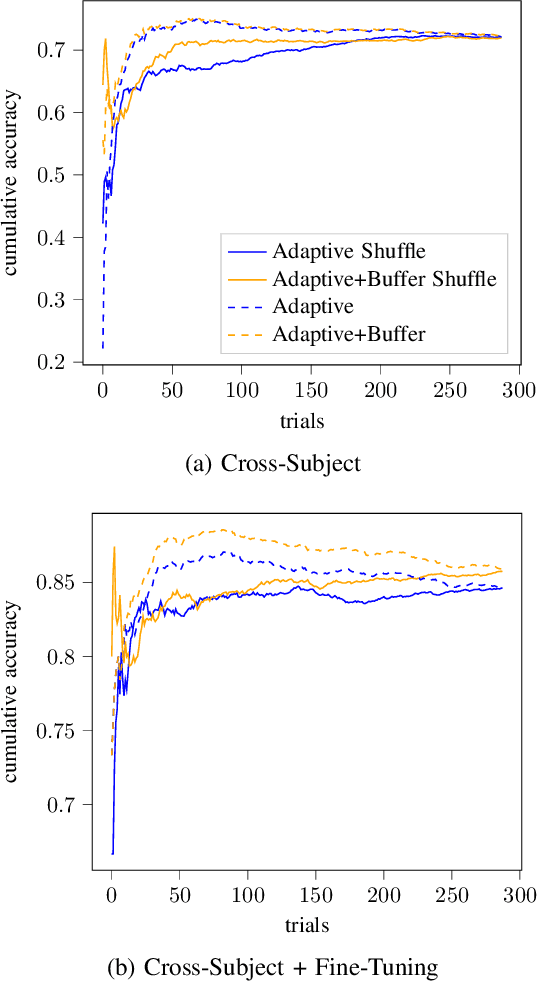
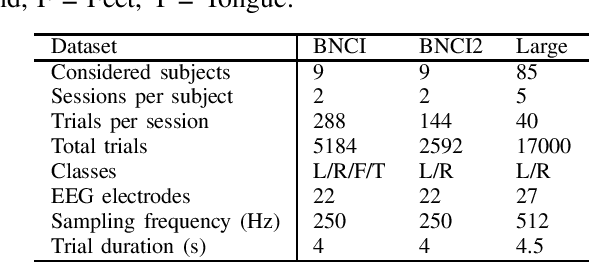
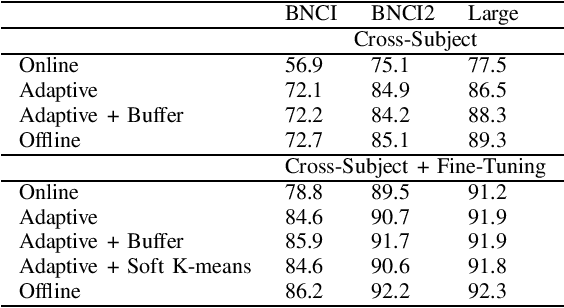
In the context of Brain-Computer Interfaces, we propose an adaptive method that reaches offline performance level while being usable online without requiring supervision. Interestingly, our method does not require retraining the model, as it consists in using a frozen efficient deep learning backbone while continuously realigning data, both at input and latent spaces, based on streaming observations. We demonstrate its efficiency for Motor Imagery brain decoding from electroencephalography data, considering challenging cross-subject scenarios. For reproducibility, we share the code of our experiments.
On Transfer in Classification: How Well do Subsets of Classes Generalize?
Mar 06, 2024In classification, it is usual to observe that models trained on a given set of classes can generalize to previously unseen ones, suggesting the ability to learn beyond the initial task. This ability is often leveraged in the context of transfer learning where a pretrained model can be used to process new classes, with or without fine tuning. Surprisingly, there are a few papers looking at the theoretical roots beyond this phenomenon. In this work, we are interested in laying the foundations of such a theoretical framework for transferability between sets of classes. Namely, we establish a partially ordered set of subsets of classes. This tool allows to represent which subset of classes can generalize to others. In a more practical setting, we explore the ability of our framework to predict which subset of classes can lead to the best performance when testing on all of them. We also explore few-shot learning, where transfer is the golden standard. Our work contributes to better understanding of transfer mechanics and model generalization.
Few and Fewer: Learning Better from Few Examples Using Fewer Base Classes
Jan 29, 2024When training data is scarce, it is common to make use of a feature extractor that has been pre-trained on a large base dataset, either by fine-tuning its parameters on the ``target'' dataset or by directly adopting its representation as features for a simple classifier. Fine-tuning is ineffective for few-shot learning, since the target dataset contains only a handful of examples. However, directly adopting the features without fine-tuning relies on the base and target distributions being similar enough that these features achieve separability and generalization. This paper investigates whether better features for the target dataset can be obtained by training on fewer base classes, seeking to identify a more useful base dataset for a given task.We consider cross-domain few-shot image classification in eight different domains from Meta-Dataset and entertain multiple real-world settings (domain-informed, task-informed and uninformed) where progressively less detail is known about the target task. To our knowledge, this is the first demonstration that fine-tuning on a subset of carefully selected base classes can significantly improve few-shot learning. Our contributions are simple and intuitive methods that can be implemented in any few-shot solution. We also give insights into the conditions in which these solutions are likely to provide a boost in accuracy. We release the code to reproduce all experiments from this paper on GitHub. https://github.com/RafLaf/Few-and-Fewer.git
A Novel Benchmark for Few-Shot Semantic Segmentation in the Era of Foundation Models
Jan 20, 2024
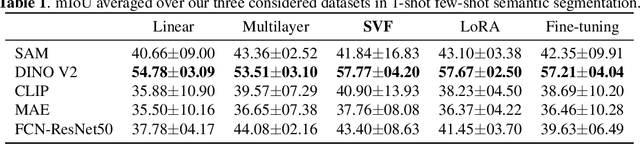
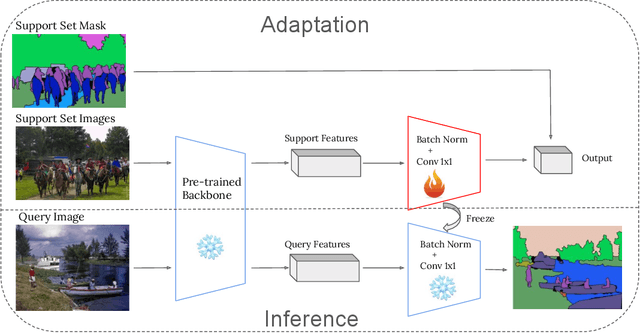
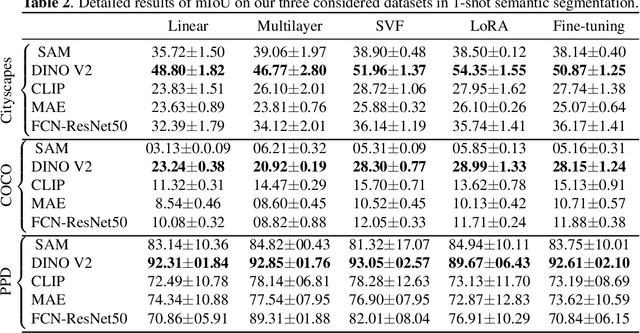
In recent years, the rapid evolution of computer vision has seen the emergence of various vision foundation models, each tailored to specific data types and tasks. While large language models often share a common pretext task, the diversity in vision foundation models arises from their varying training objectives. In this study, we delve into the quest for identifying the most effective vision foundation models for few-shot semantic segmentation, a critical task in computer vision. Specifically, we conduct a comprehensive comparative analysis of four prominent foundation models: DINO V2, Segment Anything, CLIP, Masked AutoEncoders, and a straightforward ResNet50 pre-trained on the COCO dataset. Our investigation focuses on their adaptability to new semantic segmentation tasks, leveraging only a limited number of segmented images. Our experimental findings reveal that DINO V2 consistently outperforms the other considered foundation models across a diverse range of datasets and adaptation methods. This outcome underscores DINO V2's superior capability to adapt to semantic segmentation tasks compared to its counterparts. Furthermore, our observations indicate that various adapter methods exhibit similar performance, emphasizing the paramount importance of selecting a robust feature extractor over the intricacies of the adaptation technique itself. This insight sheds light on the critical role of feature extraction in the context of few-shot semantic segmentation. This research not only contributes valuable insights into the comparative performance of vision foundation models in the realm of few-shot semantic segmentation but also highlights the significance of a robust feature extractor in this domain.