 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Benchmark for Few-Shot Semantic Segmentation in the Era of Foundation Models
Jan 20, 2024
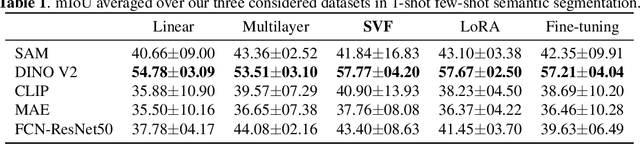
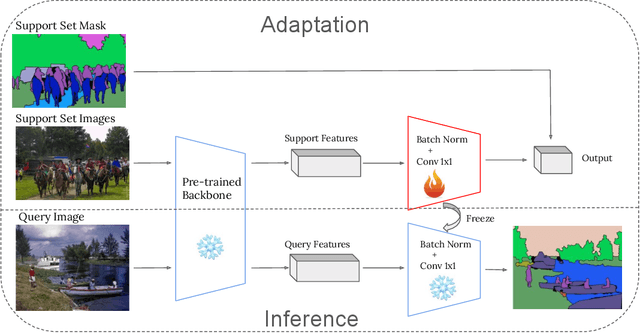
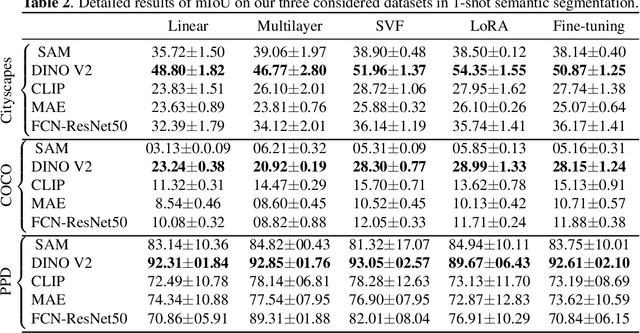
In recent years, the rapid evolution of computer vision has seen the emergence of various vision foundation models, each tailored to specific data types and tasks. While large language models often share a common pretext task, the diversity in vision foundation models arises from their varying training objectives. In this study, we delve into the quest for identifying the most effective vision foundation models for few-shot semantic segmentation, a critical task in computer vision. Specifically, we conduct a comprehensive comparative analysis of four prominent foundation models: DINO V2, Segment Anything, CLIP, Masked AutoEncoders, and a straightforward ResNet50 pre-trained on the COCO dataset. Our investigation focuses on their adaptability to new semantic segmentation tasks, leveraging only a limited number of segmented images. Our experimental findings reveal that DINO V2 consistently outperforms the other considered foundation models across a diverse range of datasets and adaptation methods. This outcome underscores DINO V2's superior capability to adapt to semantic segmentation tasks compared to its counterparts. Furthermore, our observations indicate that various adapter methods exhibit similar performance, emphasizing the paramount importance of selecting a robust feature extractor over the intricacies of the adaptation technique itself. This insight sheds light on the critical role of feature extraction in the context of few-shot semantic segmentation. This research not only contributes valuable insights into the comparative performance of vision foundation models in the realm of few-shot semantic segmentation but also highlights the significance of a robust feature extractor in this domain.