 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Foundation Model for Massive MIMO Precoding with an Adaptive per-User Rate-Power Tradeoff
Jul 24, 2025Deep learning (DL) has emerged as a solution for precoding in massive multiple-input multiple-output (mMIMO) systems due to its capacity to learn the characteristics of the propagation environment. However, training such a model requires high-quality, local datasets at the deployment site, which are often difficult to collect. We propose a transformer-based foundation model for mMIMO precoding that seeks to minimize the energy consumption of the transmitter while dynamically adapting to per-user rate requirements. At equal energy consumption, zero-shot deployment of the proposed foundation model significantly outperforms zero forcing, and approaches weighted minimum mean squared error performance with 8x less complexity. To address model adaptation in data-scarce settings, we introduce a data augmentation method that finds training samples similar to the target distribution by computing the cosine similarity between the outputs of the pre-trained feature extractor. Our work enables the implementation of DL-based solutions in practice by addressing challenges of data availability and training complexity. Moreover, the ability to dynamically configure per-user rate requirements can be leveraged by higher level resource allocation and scheduling algorithms for greater control over energy efficiency, spectral efficiency and fairness.
A Low-Complexity Plug-and-Play Deep Learning Model for Massive MIMO Precoding Across Sites
Feb 12, 2025



Massive multiple-input multiple-output (mMIMO) technology has transformed wireless communication by enhancing spectral efficiency and network capacity. This paper proposes a novel deep learning-based mMIMO precoder to tackle the complexity challenges of existing approaches, such as weighted minimum mean square error (WMMSE), while leveraging meta-learning domain generalization and a teacher-student architecture to improve generalization across diverse communication environments. When deployed to a previously unseen site, the proposed model achieves excellent sum-rate performance while maintaining low computational complexity by avoiding matrix inversions and by using a simpler neural network structure. The model is trained and tested on a custom ray-tracing dataset composed of several base station locations. The experimental results indicate that our method effectively balances computational efficiency with high sum-rate performance while showcasing strong generalization performance in unseen environments. Furthermore, with fine-tuning, the proposed model outperforms WMMSE across all tested sites and SNR conditions while reducing complexity by at least 73$\times$.
Compression of Site-Specific Deep Neural Networks for Massive MIMO Precoding
Feb 12, 2025



The deployment of deep learning (DL) models for precoding in massive multiple-input multiple-output (mMIMO) systems is often constrained by high computational demands and energy consumption. In this paper, we investigate the compute energy efficiency of mMIMO precoders using DL-based approaches, comparing them to conventional methods such as zero forcing and weighted minimum mean square error (WMMSE). Our energy consumption model accounts for both memory access and calculation energy within DL accelerators. We propose a framework that incorporates mixed-precision quantization-aware training and neural architecture search to reduce energy usage without compromising accuracy. Using a ray-tracing dataset covering various base station sites, we analyze how site-specific conditions affect the energy efficiency of compressed models. Our results show that deep neural network compression generates precoders with up to 35 times higher energy efficiency than WMMSE at equal performance, depending on the scenario and the desired rate. These results establish a foundation and a benchmark for the development of energy-efficient DL-based mMIMO precoders.
A Novel Benchmark for Few-Shot Semantic Segmentation in the Era of Foundation Models
Jan 20, 2024
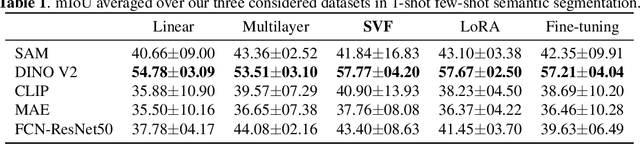
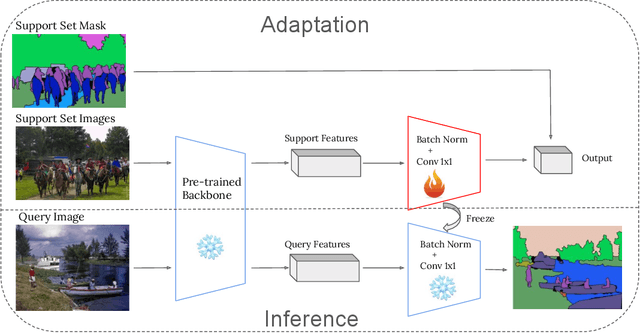
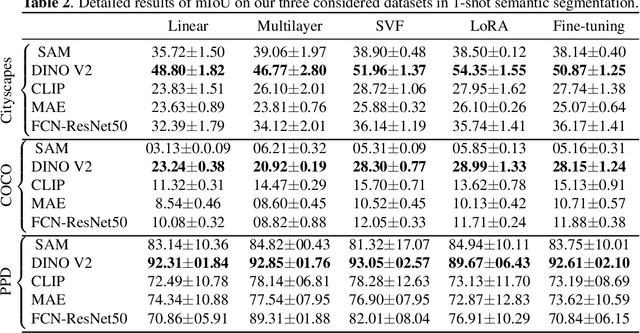
In recent years, the rapid evolution of computer vision has seen the emergence of various vision foundation models, each tailored to specific data types and tasks. While large language models often share a common pretext task, the diversity in vision foundation models arises from their varying training objectives. In this study, we delve into the quest for identifying the most effective vision foundation models for few-shot semantic segmentation, a critical task in computer vision. Specifically, we conduct a comprehensive comparative analysis of four prominent foundation models: DINO V2, Segment Anything, CLIP, Masked AutoEncoders, and a straightforward ResNet50 pre-trained on the COCO dataset. Our investigation focuses on their adaptability to new semantic segmentation tasks, leveraging only a limited number of segmented images. Our experimental findings reveal that DINO V2 consistently outperforms the other considered foundation models across a diverse range of datasets and adaptation methods. This outcome underscores DINO V2's superior capability to adapt to semantic segmentation tasks compared to its counterparts. Furthermore, our observations indicate that various adapter methods exhibit similar performance, emphasizing the paramount importance of selecting a robust feature extractor over the intricacies of the adaptation technique itself. This insight sheds light on the critical role of feature extraction in the context of few-shot semantic segmentation. This research not only contributes valuable insights into the comparative performance of vision foundation models in the realm of few-shot semantic segmentation but also highlights the significance of a robust feature extractor in this domain.
SAGE-HB: Swift Adaptation and Generalization in Massive MIMO Hybrid Beamforming
Jan 19, 2024



Deep learning (DL)-based solutions have emerged as promising candidates for beamforming in massive Multiple-Input Multiple-Output (mMIMO) systems. Nevertheless, it remains challenging to seamlessly adapt these solutions to practical deployment scenarios, typically necessitating extensive data for fine-tuning while grappling with domain adaptation and generalization issues. In response, we propose a novel approach combining Meta-Learning Domain Generalization (MLDG) with novel data augmentation techniques during fine-tuning. This approach not only accelerates adaptation to new channel environments but also significantly reduces the data requirements for fine-tuning, thereby enhancing the practicality and efficiency of DL-based mMIMO systems. The proposed approach is validated by simulating the performance of a backbone model when deployed in a new channel environment, and with different antenna configurations, path loss, and base station height parameters. Our proposed approach demonstrates superior zero-shot performance compared to existing methods and also achieves near-optimal performance with significantly fewer fine-tuning data samples.
Learning Energy-Efficient Hardware Configurations for Massive MIMO Beamforming
Aug 11, 2023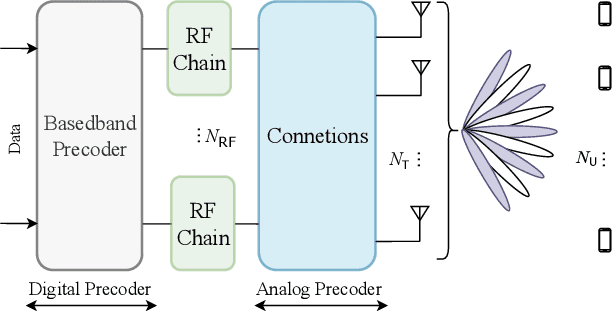
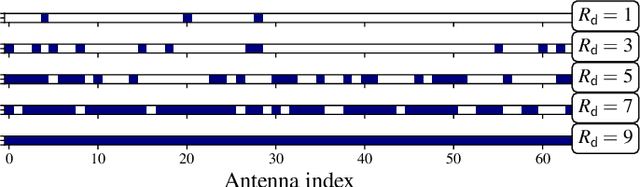
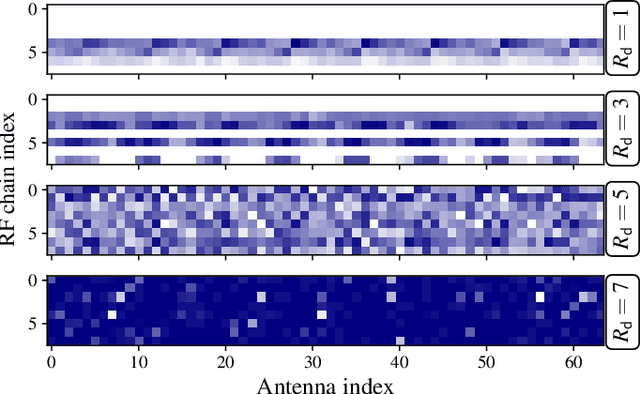
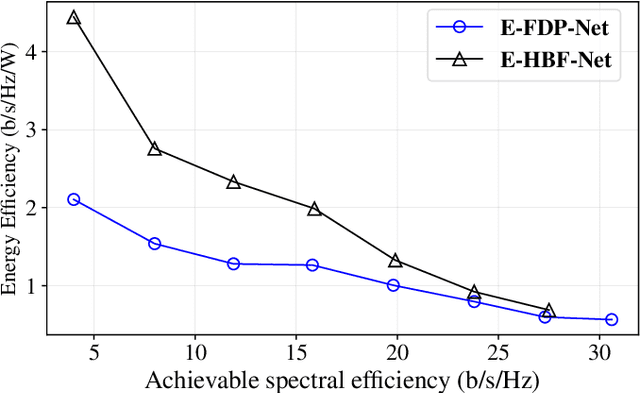
Hybrid beamforming (HBF) and antenna selection are promising techniques for improving the energy efficiency~(EE) of massive multiple-input multiple-output~(mMIMO) systems. However, the transmitter architecture may contain several parameters that need to be optimized, such as the power allocated to the antennas and the connections between the antennas and the radio frequency chains. Therefore, finding the optimal transmitter architecture requires solving a non-convex mixed integer problem in a large search space. In this paper, we consider the problem of maximizing the EE of fully digital precoder~(FDP) and hybrid beamforming~(HBF) transmitters. First, we propose an energy model for different beamforming structures. Then, based on the proposed energy model, we develop an unsupervised deep learning method to maximize the EE by designing the transmitter configuration for FDP and HBF. The proposed deep neural networks can provide different trade-offs between spectral efficiency and energy consumption while adapting to different numbers of active users. Finally, to ensure that the proposed method can be implemented in practice, we investigate the ability of the model to be trained exclusively using imperfect channel state information~(CSI), both for the input to the deep learning model and for the calculation of the loss function. Simulation results show that the proposed solutions can outperform conventional methods in terms of EE while being trained with imperfect CSI. Furthermore, we show that the proposed solutions are less complex and more robust to noise than conventional methods.
Sharpness-Aware Training for Accurate Inference on Noisy DNN Accelerators
Nov 18, 2022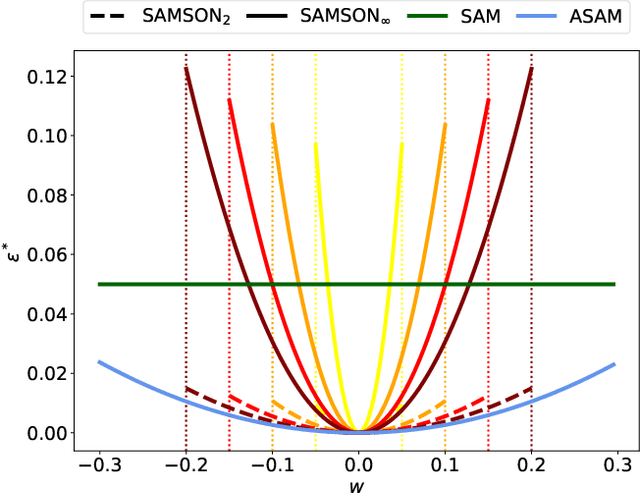
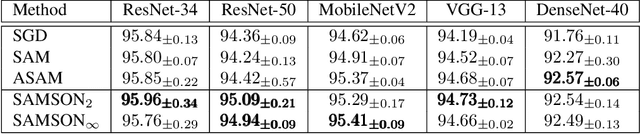
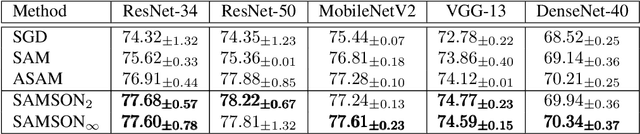
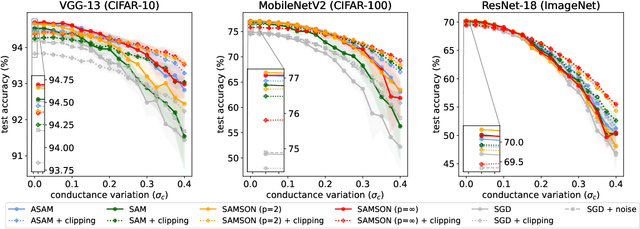
Energy-efficient deep neural network (DNN) accelerators are prone to non-idealities that degrade DNN performance at inference time. To mitigate such degradation, existing methods typically add perturbations to the DNN weights during training to simulate inference on noisy hardware. However, this often requires knowledge about the target hardware and leads to a trade-off between DNN performance and robustness, decreasing the former to increase the latter. In this work, we show that applying sharpness-aware training by optimizing for both the loss value and the loss sharpness significantly improves robustness to noisy hardware at inference time while also increasing DNN performance. We further motivate our results by showing a high correlation between loss sharpness and model robustness. We show superior performance compared to injecting noise during training and aggressive weight clipping on multiple architectures, optimizers, datasets, and training regimes without relying on any assumptions about the target hardware. This is observed on a generic noise model as well as on accurate noise simulations from real hardware.
Flexible Unsupervised Learning for Massive MIMO Subarray Hybrid Beamforming
Aug 10, 2022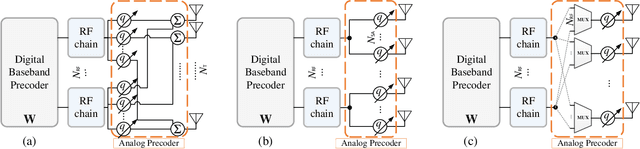
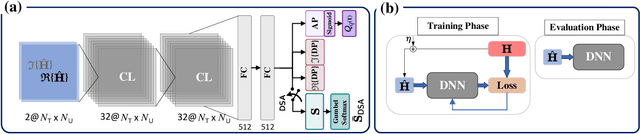
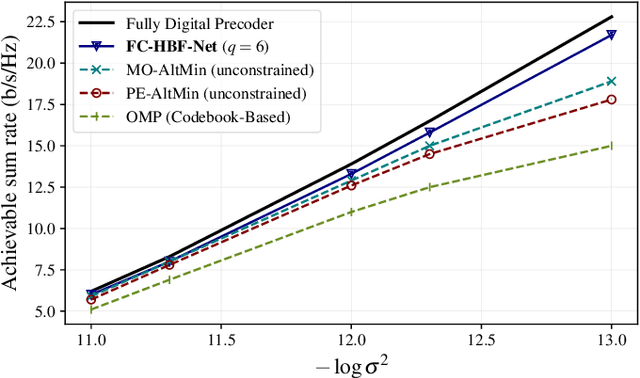
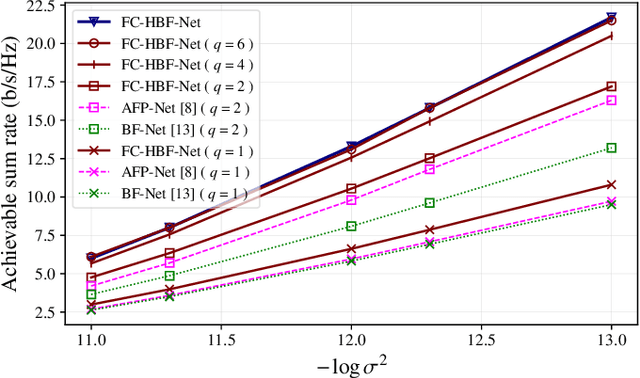
Hybrid beamforming is a promising technology to improve the energy efficiency of massive MIMO systems. In particular, subarray hybrid beamforming can further decrease power consumption by reducing the number of phase-shifters. However, designing the hybrid beamforming vectors is a complex task due to the discrete nature of the subarray connections and the phase-shift amounts. Finding the optimal connections between RF chains and antennas requires solving a non-convex problem in a large search space. In addition, conventional solutions assume that perfect CSI is available, which is not the case in practical systems. Therefore, we propose a novel unsupervised learning approach to design the hybrid beamforming for any subarray structure while supporting quantized phase-shifters and noisy CSI. One major feature of the proposed architecture is that no beamforming codebook is required, and the neural network is trained to take into account the phase-shifter quantization. Simulation results show that the proposed deep learning solutions can achieve higher sum-rates than existing methods.
MemSE: Fast MSE Prediction for Noisy Memristor-Based DNN Accelerators
May 03, 2022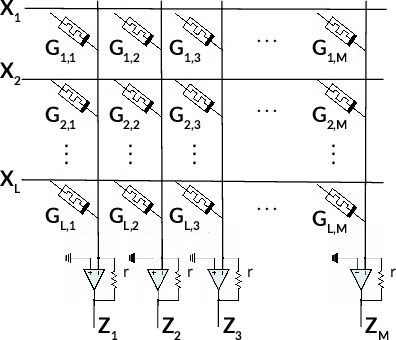
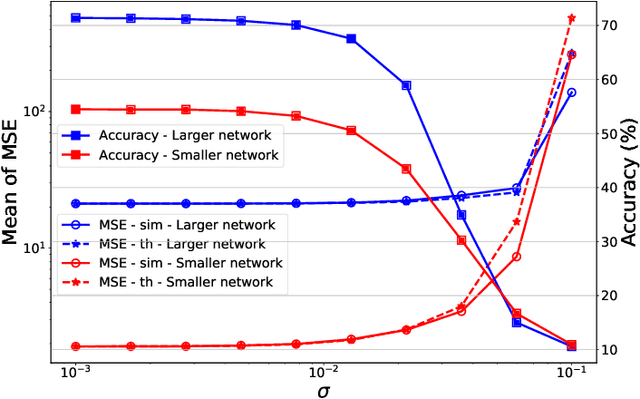
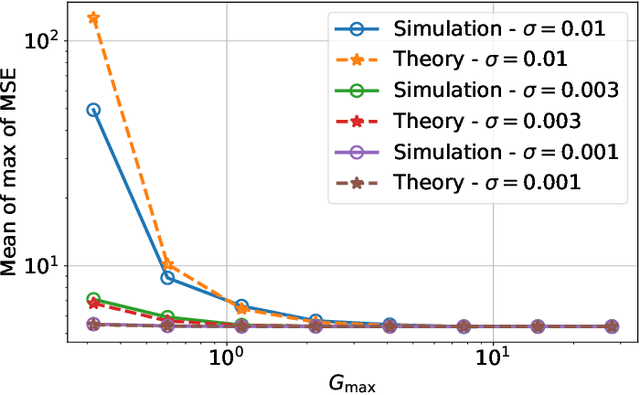
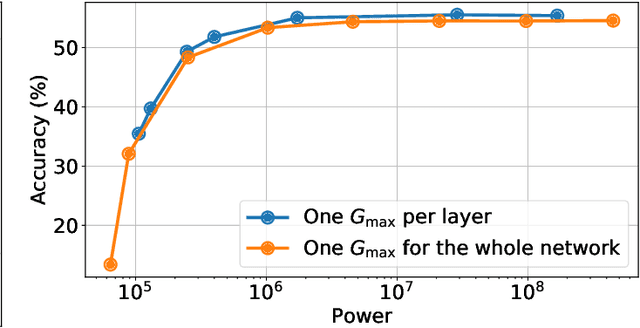
Memristors enable the computation of matrix-vector multiplications (MVM) in memory and, therefore, show great potential in highly increasing the energy efficiency of deep neural network (DNN) inference accelerators. However, computations in memristors suffer from hardware non-idealities and are subject to different sources of noise that may negatively impact system performance. In this work, we theoretically analyze the mean squared error of DNNs that use memristor crossbars to compute MVM. We take into account both the quantization noise, due to the necessity of reducing the DNN model size, and the programming noise, stemming from the variability during the programming of the memristance value. Simulations on pre-trained DNN models showcase the accuracy of the analytical prediction. Furthermore the proposed method is almost two order of magnitude faster than Monte-Carlo simulation, thus making it possible to optimize the implementation parameters to achieve minimal error for a given power constraint.
Optimizing the Energy Efficiency of Unreliable Memories for Quantized Kalman Filtering
Sep 03, 2021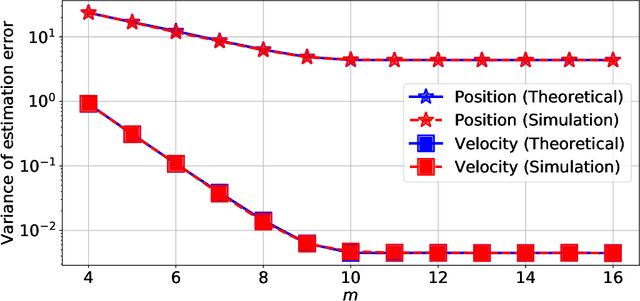
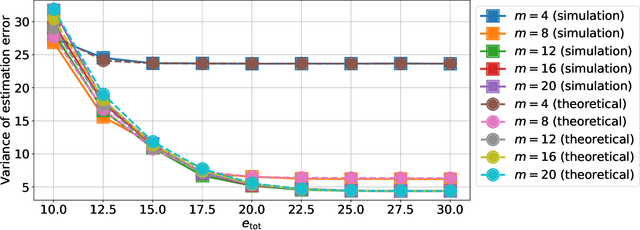
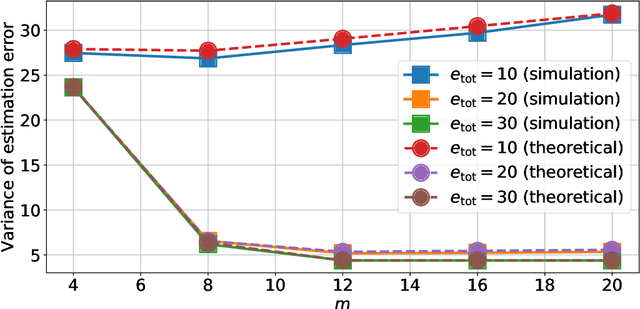
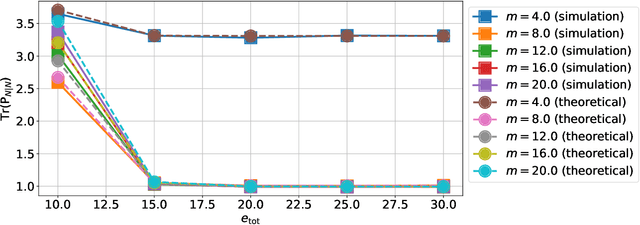
This paper presents a quantized Kalman filter implemented using unreliable memories. We consider that both the quantization and the unreliable memories introduce errors in the computations, and develop an error propagation model that takes into account these two sources of errors. In addition to providing updated Kalman filter equations, the proposed error model accurately predicts the covariance of the estimation error and gives a relation between the performance of the filter and its energy consumption, depending on the noise level in the memories. Then, since memories are responsible for a large part of the energy consumption of embedded systems, optimization methods are introduced so as to minimize the memory energy consumption under a desired estimation performance of the filter. The first method computes the optimal energy levels allocated to each memory bank individually, and the second one optimizes the energy allocation per groups of memory banks. Simulations show a close match between the theoretical analysis and experimental results. Furthermore, they demonstrate an important reduction in energy consumption of more than 50%.