 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Quantization for Efficient Pre-Training of Transformer Language Models
Jul 16, 2024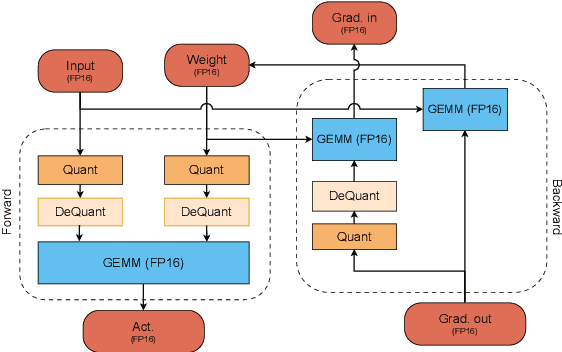


The increasing scale of Transformer models has led to an increase in their pre-training computational requirements. While quantization has proven to be effective after pre-training and during fine-tuning, applying quantization in Transformers during pre-training has remained largely unexplored at scale for language modeling. This study aims to explore the impact of quantization for efficient pre-training of Transformers, with a focus on linear layer components. By systematically applying straightforward linear quantization to weights, activations, gradients, and optimizer states, we assess its effects on model efficiency, stability, and performance during training. By offering a comprehensive recipe of effective quantization strategies to be applied during the pre-training of Transformers, we promote high training efficiency from scratch while retaining language modeling ability. Code is available at https://github.com/chandar-lab/EfficientLLMs.
Lookbehind Optimizer: k steps back, 1 step forward
Jul 31, 2023The Lookahead optimizer improves the training stability of deep neural networks by having a set of fast weights that "look ahead" to guide the descent direction. Here, we combine this idea with sharpness-aware minimization (SAM) to stabilize its multi-step variant and improve the loss-sharpness trade-off. We propose Lookbehind, which computes $k$ gradient ascent steps ("looking behind") at each iteration and combine the gradients to bias the descent step toward flatter minima. We apply Lookbehind on top of two popular sharpness-aware training methods -- SAM and adaptive SAM (ASAM) -- and show that our approach leads to a myriad of benefits across a variety of tasks and training regimes. Particularly, we show increased generalization performance, greater robustness against noisy weights, and higher tolerance to catastrophic forgetting in lifelong learning settings.
Promoting Exploration in Memory-Augmented Adam using Critical Momenta
Jul 18, 2023Adaptive gradient-based optimizers, particularly Adam, have left their mark in training large-scale deep learning models. The strength of such optimizers is that they exhibit fast convergence while being more robust to hyperparameter choice. However, they often generalize worse than non-adaptive methods. Recent studies have tied this performance gap to flat minima selection: adaptive methods tend to find solutions in sharper basins of the loss landscape, which in turn hurts generalization. To overcome this issue, we propose a new memory-augmented version of Adam that promotes exploration towards flatter minima by using a buffer of critical momentum terms during training. Intuitively, the use of the buffer makes the optimizer overshoot outside the basin of attraction if it is not wide enough. We empirically show that our method improves the performance of several variants of Adam on standard supervised language modelling and image classification tasks.
Sharpness-Aware Training for Accurate Inference on Noisy DNN Accelerators
Nov 18, 2022
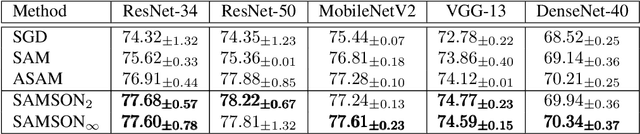
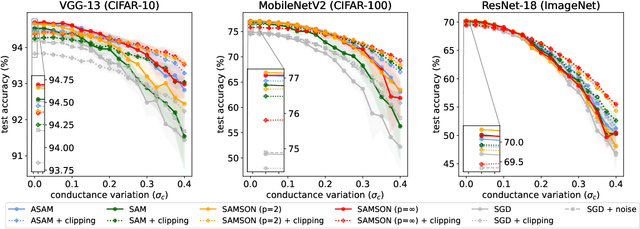
Energy-efficient deep neural network (DNN) accelerators are prone to non-idealities that degrade DNN performance at inference time. To mitigate such degradation, existing methods typically add perturbations to the DNN weights during training to simulate inference on noisy hardware. However, this often requires knowledge about the target hardware and leads to a trade-off between DNN performance and robustness, decreasing the former to increase the latter. In this work, we show that applying sharpness-aware training by optimizing for both the loss value and the loss sharpness significantly improves robustness to noisy hardware at inference time while also increasing DNN performance. We further motivate our results by showing a high correlation between loss sharpness and model robustness. We show superior performance compared to injecting noise during training and aggressive weight clipping on multiple architectures, optimizers, datasets, and training regimes without relying on any assumptions about the target hardware. This is observed on a generic noise model as well as on accurate noise simulations from real hardware.
Improving Meta-Learning Generalization with Activation-Based Early-Stopping
Aug 03, 2022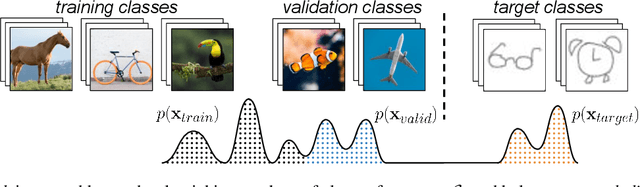



Meta-Learning algorithms for few-shot learning aim to train neural networks capable of generalizing to novel tasks using only a few examples. Early-stopping is critical for performance, halting model training when it reaches optimal generalization to the new task distribution. Early-stopping mechanisms in Meta-Learning typically rely on measuring the model performance on labeled examples from a meta-validation set drawn from the training (source) dataset. This is problematic in few-shot transfer learning settings, where the meta-test set comes from a different target dataset (OOD) and can potentially have a large distributional shift with the meta-validation set. In this work, we propose Activation Based Early-stopping (ABE), an alternative to using validation-based early-stopping for meta-learning. Specifically, we analyze the evolution, during meta-training, of the neural activations at each hidden layer, on a small set of unlabelled support examples from a single task of the target tasks distribution, as this constitutes a minimal and justifiably accessible information from the target problem. Our experiments show that simple, label agnostic statistics on the activations offer an effective way to estimate how the target generalization evolves over time. At each hidden layer, we characterize the activation distributions, from their first and second order moments, then further summarized along the feature dimensions, resulting in a compact yet intuitive characterization in a four-dimensional space. Detecting when, throughout training time, and at which layer, the target activation trajectory diverges from the activation trajectory of the source data, allows us to perform early-stopping and improve generalization in a large array of few-shot transfer learning settings, across different algorithms, source and target datasets.
MemSE: Fast MSE Prediction for Noisy Memristor-Based DNN Accelerators
May 03, 2022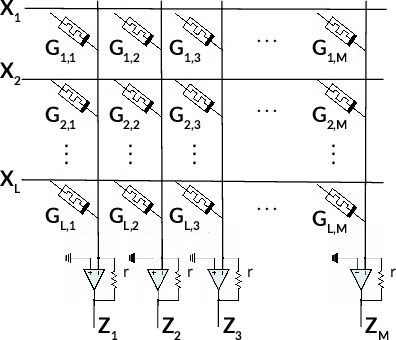
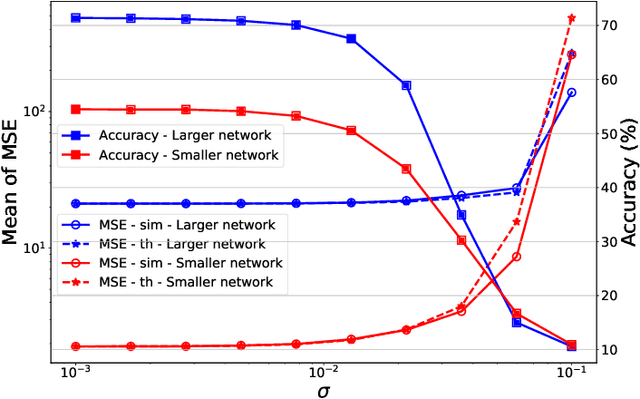
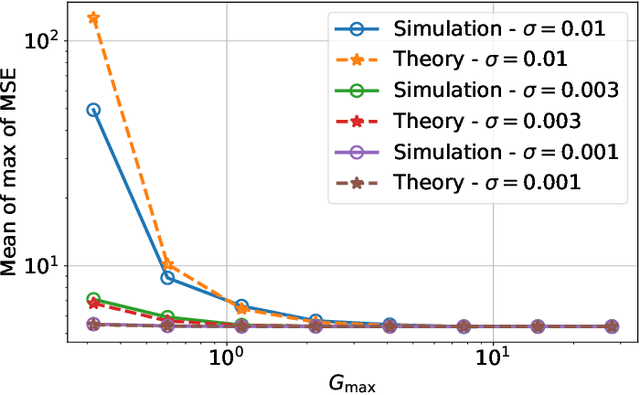
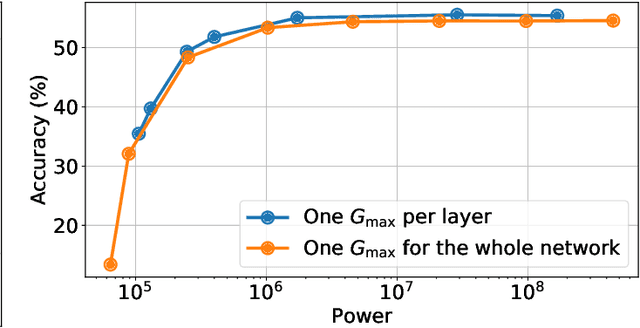
Memristors enable the computation of matrix-vector multiplications (MVM) in memory and, therefore, show great potential in highly increasing the energy efficiency of deep neural network (DNN) inference accelerators. However, computations in memristors suffer from hardware non-idealities and are subject to different sources of noise that may negatively impact system performance. In this work, we theoretically analyze the mean squared error of DNNs that use memristor crossbars to compute MVM. We take into account both the quantization noise, due to the necessity of reducing the DNN model size, and the programming noise, stemming from the variability during the programming of the memristance value. Simulations on pre-trained DNN models showcase the accuracy of the analytical prediction. Furthermore the proposed method is almost two order of magnitude faster than Monte-Carlo simulation, thus making it possible to optimize the implementation parameters to achieve minimal error for a given power constraint.
Compressing 1D Time-Channel Separable Convolutions using Sparse Random Ternary Matrices
Apr 02, 2021
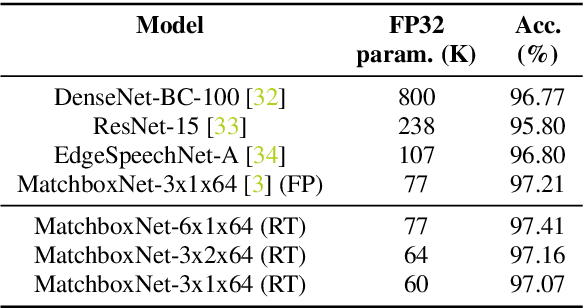

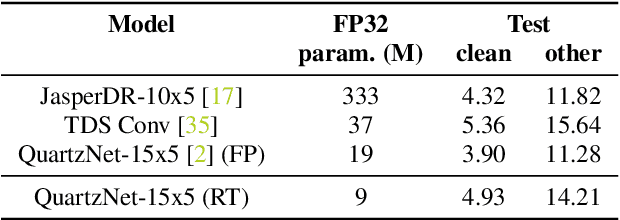
We demonstrate that 1x1-convolutions in 1D time-channel separable convolutions may be replaced by constant, sparse random ternary matrices with weights in $\{-1,0,+1\}$. Such layers do not perform any multiplications and do not require training. Moreover, the matrices may be generated on the chip during computation and therefore do not require any memory access. With the same parameter budget, we can afford deeper and more expressive models, improving the Pareto frontiers of existing models on several tasks. For command recognition on Google Speech Commands v1, we improve the state-of-the-art accuracy from $97.21\%$ to $97.41\%$ at the same network size. Alternatively, we can lower the cost of existing models. For speech recognition on Librispeech, we half the number of weights to be trained while only sacrificing about $1\%$ of the floating-point baseline's word error rate.
Evaluating Post-Training Compression in GANs using Locality-Sensitive Hashing
Mar 22, 2021The analysis of the compression effects in generative adversarial networks (GANs) after training, i.e. without any fine-tuning, remains an unstudied, albeit important, topic with the increasing trend of their computation and memory requirements. While existing works discuss the difficulty of compressing GANs during training, requiring novel methods designed with the instability of GANs training in mind, we show that existing compression methods (namely clipping and quantization) may be directly applied to compress GANs post-training, without any additional changes. High compression levels may distort the generated set, likely leading to an increase of outliers that may negatively affect the overall assessment of existing k-nearest neighbor (KNN) based metrics. We propose two new precision and recall metrics based on locality-sensitive hashing (LSH), which, on top of increasing the outlier robustness, decrease the complexity of assessing an evaluation sample against $n$ reference samples from $O(n)$ to $O(\log(n))$, if using LSH and KNN, and to $O(1)$, if only applying LSH. We show that low-bit compression of several pre-trained GANs on multiple datasets induces a trade-off between precision and recall, retaining sample quality while sacrificing sample diversity.
Mark-Evaluate: Assessing Language Generation using Population Estimation Methods
Oct 09, 2020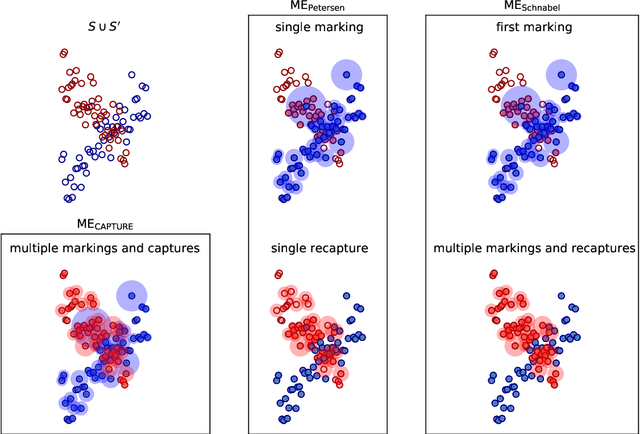

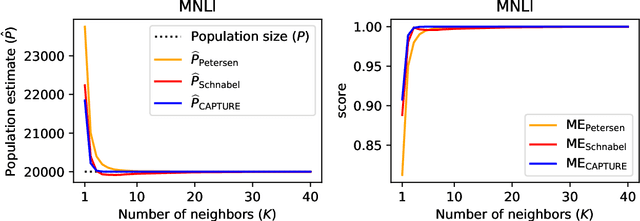
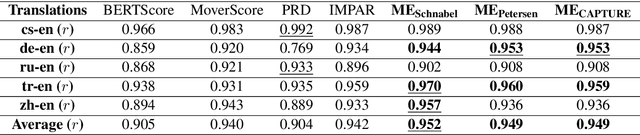
We propose a family of metrics to assess language generation derived from population estimation methods widely used in ecology. More specifically, we use mark-recapture and maximum-likelihood methods that have been applied over the past several decades to estimate the size of closed populations in the wild. We propose three novel metrics: ME$_\text{Petersen}$ and ME$_\text{CAPTURE}$, which retrieve a single-valued assessment, and ME$_\text{Schnabel}$ which returns a double-valued metric to assess the evaluation set in terms of quality and diversity, separately. In synthetic experiments, our family of methods is sensitive to drops in quality and diversity. Moreover, our methods show a higher correlation to human evaluation than existing metrics on several challenging tasks, namely unconditional language generation, machine translation, and text summarization.
Improving the Evaluation of Generative Models with Fuzzy Logic
Feb 03, 2020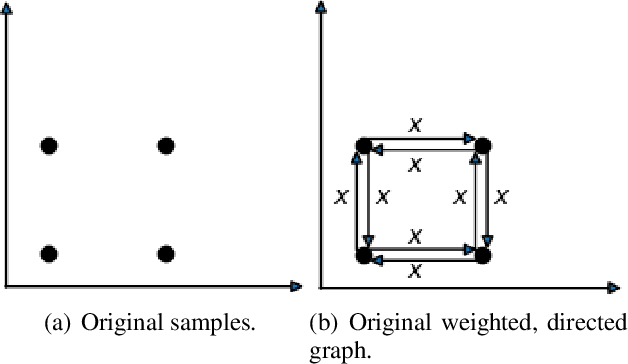


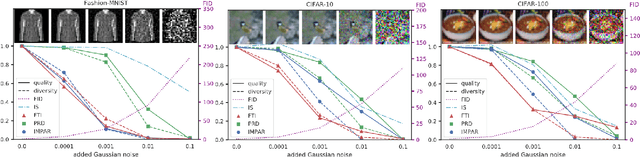
Objective and interpretable metrics to evaluate current artificial intelligent systems are of great importance, not only to analyze the current state of such systems but also to objectively measure progress in the future. In this work, we focus on the evaluation of image generation tasks. We propose a novel approach, called Fuzzy Topology Impact (FTI), that determines both the quality and diversity of an image set using topology representations combined with fuzzy logic. When compared to current evaluation methods, FTI shows better and more stable performance on multiple experiments evaluating the sensitivity to noise, mode dropping and mode inventing.