 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarmonizing Dense and Sparse Signals in Multi-turn RL: Dual-Horizon Credit Assignment for Industrial Sales Agents
Mar 02, 2026Optimizing large language models for industrial sales requires balancing long-term commercial objectives (e.g., conversion rate) with immediate linguistic constraints such as fluency and compliance. Conventional reinforcement learning often merges these heterogeneous goals into a single reward, causing high-magnitude session-level rewards to overwhelm subtler turn-level signals, which leads to unstable training or reward hacking. To address this issue, we propose Dual-Horizon Credit Assignment (DuCA), a framework that disentangles optimization across time scales. Its core, Horizon-Independent Advantage Normalization (HIAN), separately normalizes advantages from turn-level and session-level rewards before fusion, ensuring balanced gradient contributions from both immediate and long-term objectives to the policy update. Extensive experiments with a high-fidelity user simulator show DuCA outperforms the state-of-the-art GRPO baseline, achieving a 6.82% relative improvement in conversion rate, reducing inter-sentence repetition by 82.28%, and lowering identity detection rate by 27.35%, indicating a substantial improvement for an industrial sales scenario that effectively balances the dual demands of strategic performance and naturalistic language generation.
Image Tokens Matter: Mitigating Hallucination in Discrete Tokenizer-based Large Vision-Language Models via Latent Editing
May 24, 2025Large Vision-Language Models (LVLMs) with discrete image tokenizers unify multimodal representations by encoding visual inputs into a finite set of tokens. Despite their effectiveness, we find that these models still hallucinate non-existent objects. We hypothesize that this may be due to visual priors induced during training: When certain image tokens frequently co-occur in the same spatial regions and represent shared objects, they become strongly associated with the verbalizations of those objects. As a result, the model may hallucinate by evoking visually absent tokens that often co-occur with present ones. To test this assumption, we construct a co-occurrence graph of image tokens using a segmentation dataset and employ a Graph Neural Network (GNN) with contrastive learning followed by a clustering method to group tokens that frequently co-occur in similar visual contexts. We find that hallucinations predominantly correspond to clusters whose tokens dominate the input, and more specifically, that the visually absent tokens in those clusters show much higher correlation with hallucinated objects compared to tokens present in the image. Based on this observation, we propose a hallucination mitigation method that suppresses the influence of visually absent tokens by modifying latent image embeddings during generation. Experiments show our method reduces hallucinations while preserving expressivity. Code is available at https://github.com/weixingW/CGC-VTD/tree/main
Data Pruning Can Do More: A Comprehensive Data Pruning Approach for Object Re-identification
Dec 13, 2024



Previous studies have demonstrated that not each sample in a dataset is of equal importance during training. Data pruning aims to remove less important or informative samples while still achieving comparable results as training on the original (untruncated) dataset, thereby reducing storage and training costs. However, the majority of data pruning methods are applied to image classification tasks. To our knowledge, this work is the first to explore the feasibility of these pruning methods applied to object re-identification (ReID) tasks, while also presenting a more comprehensive data pruning approach. By fully leveraging the logit history during training, our approach offers a more accurate and comprehensive metric for quantifying sample importance, as well as correcting mislabeled samples and recognizing outliers. Furthermore, our approach is highly efficient, reducing the cost of importance score estimation by 10 times compared to existing methods. Our approach is a plug-and-play, architecture-agnostic framework that can eliminate/reduce 35%, 30%, and 5% of samples/training time on the VeRi, MSMT17 and Market1501 datasets, respectively, with negligible loss in accuracy (< 0.1%). The lists of important, mislabeled, and outlier samples from these ReID datasets are available at https://github.com/Zi-Y/data-pruning-reid.
SeCoKD: Aligning Large Language Models for In-Context Learning with Fewer Shots
Jun 20, 2024



Previous studies have shown that demonstrations can significantly help Large Language Models (LLMs ) perform better on the given tasks. However, this so-called In-Context Learning ( ICL ) ability is very sensitive to the presenting context, and often dozens of demonstrations are needed. In this work, we investigate if we can reduce the shot number while still maintaining a competitive performance. We present SeCoKD, a self-Knowledge Distillation ( KD ) training framework that aligns the student model with a heavily prompted variation, thereby increasing the utilization of a single demonstration. We experiment with the SeCoKD across three LLMs and six benchmarks focusing mainly on reasoning tasks. Results show that our method outperforms the base model and Supervised Fine-tuning ( SFT ), especially in zero-shot and one-shot settings by 30% and 10%, respectively. Moreover, SeCoKD brings little negative artifacts when evaluated on new tasks, which is more robust than Supervised Fine-tuning.
Feature Distribution Shift Mitigation with Contrastive Pretraining for Intrusion Detection
Apr 23, 2024



In recent years, there has been a growing interest in using Machine Learning (ML), especially Deep Learning (DL) to solve Network Intrusion Detection (NID) problems. However, the feature distribution shift problem remains a difficulty, because the change in features' distributions over time negatively impacts the model's performance. As one promising solution, model pretraining has emerged as a novel training paradigm, which brings robustness against feature distribution shift and has proven to be successful in Computer Vision (CV) and Natural Language Processing (NLP). To verify whether this paradigm is beneficial for NID problem, we propose SwapCon, a ML model in the context of NID, which compresses shift-invariant feature information during the pretraining stage and refines during the finetuning stage. We exemplify the evidence of feature distribution shift using the Kyoto2006+ dataset. We demonstrate how pretraining a model with the proper size can increase robustness against feature distribution shifts by over 8%. Moreover, we show how an adequate numerical embedding strategy also enhances the performance of pretrained models. Further experiments show that the proposed SwapCon model also outperforms eXtreme Gradient Boosting (XGBoost) and K-Nearest Neighbor (KNN) based models by a large margin.
Scaled Prompt-Tuning for Few-Shot Natural Language Generation
Sep 13, 2023



The increasingly Large Language Models (LLMs) demonstrate stronger language understanding and generation capabilities, while the memory demand and computation cost of fine-tuning LLMs on downstream tasks are non-negligible. Besides, fine-tuning generally requires a certain amount of data from individual tasks whilst data collection cost is another issue to consider in real-world applications. In this work, we focus on Parameter-Efficient Fine-Tuning (PEFT) methods for few-shot Natural Language Generation (NLG), which freeze most parameters in LLMs and tune a small subset of parameters in few-shot cases so that memory footprint, training cost, and labeling cost are reduced while maintaining or even improving the performance. We propose a Scaled Prompt-Tuning (SPT) method which surpasses conventional PT with better performance and generalization ability but without an obvious increase in training cost. Further study on intermediate SPT suggests the superior transferability of SPT in few-shot scenarios, providing a recipe for data-deficient and computation-limited circumstances. Moreover, a comprehensive comparison of existing PEFT methods reveals that certain approaches exhibiting decent performance with modest training cost such as Prefix-Tuning in prior study could struggle in few-shot NLG tasks, especially on challenging datasets.
Supervised Knowledge May Hurt Novel Class Discovery Performance
Jun 06, 2023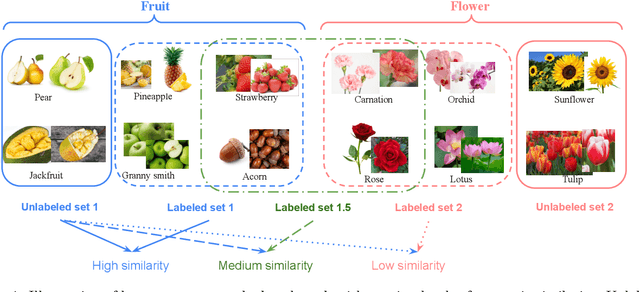
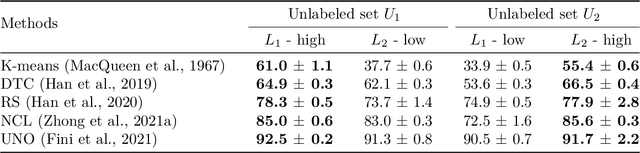
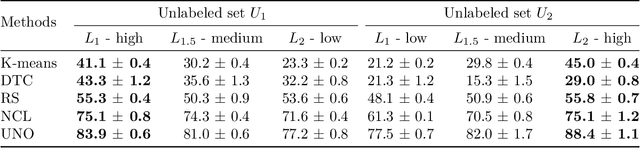

Novel class discovery (NCD) aims to infer novel categories in an unlabeled dataset by leveraging prior knowledge of a labeled set comprising disjoint but related classes. Given that most existing literature focuses primarily on utilizing supervised knowledge from a labeled set at the methodology level, this paper considers the question: Is supervised knowledge always helpful at different levels of semantic relevance? To proceed, we first establish a novel metric, so-called transfer flow, to measure the semantic similarity between labeled/unlabeled datasets. To show the validity of the proposed metric, we build up a large-scale benchmark with various degrees of semantic similarities between labeled/unlabeled datasets on ImageNet by leveraging its hierarchical class structure. The results based on the proposed benchmark show that the proposed transfer flow is in line with the hierarchical class structure; and that NCD performance is consistent with the semantic similarities (measured by the proposed metric). Next, by using the proposed transfer flow, we conduct various empirical experiments with different levels of semantic similarity, yielding that supervised knowledge may hurt NCD performance. Specifically, using supervised information from a low-similarity labeled set may lead to a suboptimal result as compared to using pure self-supervised knowledge. These results reveal the inadequacy of the existing NCD literature which usually assumes that supervised knowledge is beneficial. Finally, we develop a pseudo-version of the transfer flow as a practical reference to decide if supervised knowledge should be used in NCD. Its effectiveness is supported by our empirical studies, which show that the pseudo transfer flow (with or without supervised knowledge) is consistent with the corresponding accuracy based on various datasets. Code is released at https://github.com/J-L-O/SK-Hurt-NCD
DocLangID: Improving Few-Shot Training to Identify the Language of Historical Documents
May 03, 2023



Language identification describes the task of recognizing the language of written text in documents. This information is crucial because it can be used to support the analysis of a document's vocabulary and context. Supervised learning methods in recent years have advanced the task of language identification. However, these methods usually require large labeled datasets, which often need to be included for various domains of images, such as documents or scene images. In this work, we propose DocLangID, a transfer learning approach to identify the language of unlabeled historical documents. We achieve this by first leveraging labeled data from a different but related domain of historical documents. Secondly, we implement a distance-based few-shot learning approach to adapt a convolutional neural network to new languages of the unlabeled dataset. By introducing small amounts of manually labeled examples from the set of unlabeled images, our feature extractor develops a better adaptability towards new and different data distributions of historical documents. We show that such a model can be effectively fine-tuned for the unlabeled set of images by only reusing the same few-shot examples. We showcase our work across 10 languages that mostly use the Latin script. Our experiments on historical documents demonstrate that our combined approach improves the language identification performance, achieving 74% recognition accuracy on the four unseen languages of the unlabeled dataset.
Join the High Accuracy Club on ImageNet with A Binary Neural Network Ticket
Dec 13, 2022



Binary neural networks are the extreme case of network quantization, which has long been thought of as a potential edge machine learning solution. However, the significant accuracy gap to the full-precision counterparts restricts their creative potential for mobile applications. In this work, we revisit the potential of binary neural networks and focus on a compelling but unanswered problem: how can a binary neural network achieve the crucial accuracy level (e.g., 80%) on ILSVRC-2012 ImageNet? We achieve this goal by enhancing the optimization process from three complementary perspectives: (1) We design a novel binary architecture BNext based on a comprehensive study of binary architectures and their optimization process. (2) We propose a novel knowledge-distillation technique to alleviate the counter-intuitive overfitting problem observed when attempting to train extremely accurate binary models. (3) We analyze the data augmentation pipeline for binary networks and modernize it with up-to-date techniques from full-precision models. The evaluation results on ImageNet show that BNext, for the first time, pushes the binary model accuracy boundary to 80.57% and significantly outperforms all the existing binary networks. Code and trained models are available at: https://github.com/hpi-xnor/BNext.git.
Empirical Evaluation of Post-Training Quantization Methods for Language Tasks
Oct 29, 2022



Transformer-based architectures like BERT have achieved great success in a wide range of Natural Language tasks. Despite their decent performance, the models still have numerous parameters and high computational complexity, impeding their deployment in resource-constrained environments. Post-Training Quantization (PTQ), which enables low-bit computations without extra training, could be a promising tool. In this work, we conduct an empirical evaluation of three PTQ methods on BERT-Base and BERT-Large: Linear Quantization (LQ), Analytical Clipping for Integer Quantization (ACIQ), and Outlier Channel Splitting (OCS). OCS theoretically surpasses the others in minimizing the Mean Square quantization Error and avoiding distorting the weights' outliers. That is consistent with the evaluation results of most language tasks of GLUE benchmark and a reading comprehension task, SQuAD. Moreover, low-bit quantized BERT models could outperform the corresponding 32-bit baselines on several small language tasks, which we attribute to the alleviation of over-parameterization. We further explore the limit of quantization bit and show that OCS could quantize BERT-Base and BERT-Large to 3-bits and retain 98% and 96% of the performance on the GLUE benchmark accordingly. Moreover, we conduct quantization on the whole BERT family, i.e., BERT models in different configurations, and comprehensively evaluate their performance on the GLUE benchmark and SQuAD, hoping to provide valuable guidelines for their deployment in various computation environments.