 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsLoss: Stochastic Calibrated Loss Ensembles for Preventing Overfitting in Classification
Sep 04, 2024Empirical risk minimization (ERM) with a computationally feasible surrogate loss is a widely accepted approach for classification. Notably, the convexity and calibration (CC) properties of a loss function ensure consistency of ERM in maximizing accuracy, thereby offering a wide range of options for surrogate losses. In this article, we propose a novel ensemble method, namely EnsLoss, which extends the ensemble learning concept to combine loss functions within the ERM framework. A key feature of our method is the consideration on preserving the "legitimacy" of the combined losses, i.e., ensuring the CC properties. Specifically, we first transform the CC conditions of losses into loss-derivatives, thereby bypassing the need for explicit loss functions and directly generating calibrated loss-derivatives. Therefore, inspired by Dropout, EnsLoss enables loss ensembles through one training process with doubly stochastic gradient descent (i.e., random batch samples and random calibrated loss-derivatives). We theoretically establish the statistical consistency of our approach and provide insights into its benefits. The numerical effectiveness of EnsLoss compared to fixed loss methods is demonstrated through experiments on a broad range of 14 OpenML tabular datasets and 46 image datasets with various deep learning architectures. Python repository and source code are available on GitHub at https://github.com/statmlben/ensloss.
Supervised Knowledge May Hurt Novel Class Discovery Performance
Jun 06, 2023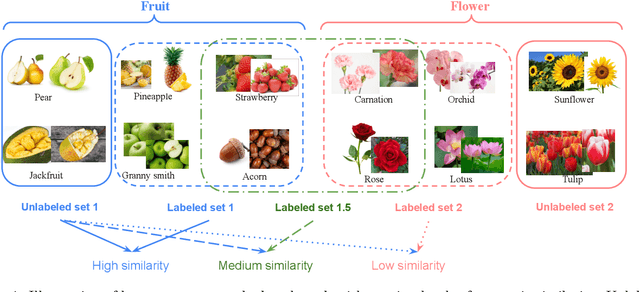
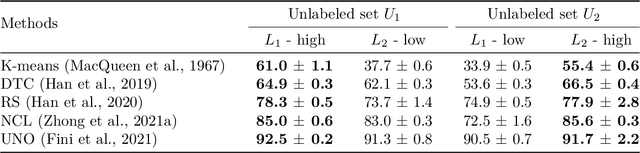
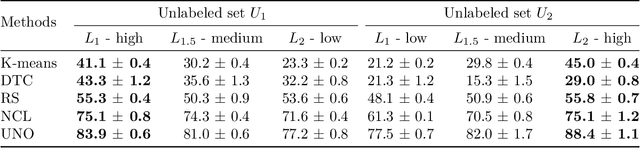

Novel class discovery (NCD) aims to infer novel categories in an unlabeled dataset by leveraging prior knowledge of a labeled set comprising disjoint but related classes. Given that most existing literature focuses primarily on utilizing supervised knowledge from a labeled set at the methodology level, this paper considers the question: Is supervised knowledge always helpful at different levels of semantic relevance? To proceed, we first establish a novel metric, so-called transfer flow, to measure the semantic similarity between labeled/unlabeled datasets. To show the validity of the proposed metric, we build up a large-scale benchmark with various degrees of semantic similarities between labeled/unlabeled datasets on ImageNet by leveraging its hierarchical class structure. The results based on the proposed benchmark show that the proposed transfer flow is in line with the hierarchical class structure; and that NCD performance is consistent with the semantic similarities (measured by the proposed metric). Next, by using the proposed transfer flow, we conduct various empirical experiments with different levels of semantic similarity, yielding that supervised knowledge may hurt NCD performance. Specifically, using supervised information from a low-similarity labeled set may lead to a suboptimal result as compared to using pure self-supervised knowledge. These results reveal the inadequacy of the existing NCD literature which usually assumes that supervised knowledge is beneficial. Finally, we develop a pseudo-version of the transfer flow as a practical reference to decide if supervised knowledge should be used in NCD. Its effectiveness is supported by our empirical studies, which show that the pseudo transfer flow (with or without supervised knowledge) is consistent with the corresponding accuracy based on various datasets. Code is released at https://github.com/J-L-O/SK-Hurt-NCD
Data-Adaptive Discriminative Feature Localization with Statistically Guaranteed Interpretation
Nov 18, 2022

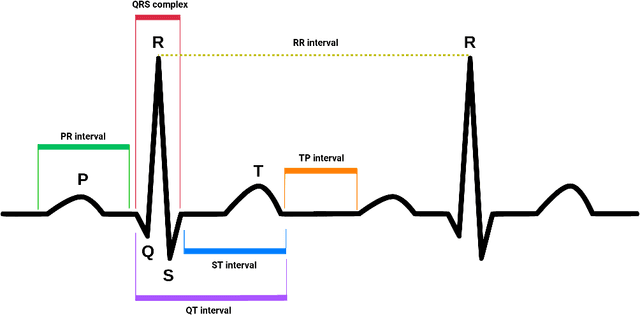

In explainable artificial intelligence, discriminative feature localization is critical to reveal a blackbox model's decision-making process from raw data to prediction. In this article, we use two real datasets, the MNIST handwritten digits and MIT-BIH Electrocardiogram (ECG) signals, to motivate key characteristics of discriminative features, namely adaptiveness, predictive importance and effectiveness. Then, we develop a localization framework based on adversarial attacks to effectively localize discriminative features. In contrast to existing heuristic methods, we also provide a statistically guaranteed interpretability of the localized features by measuring a generalized partial $R^2$. We apply the proposed method to the MNIST dataset and the MIT-BIH dataset with a convolutional auto-encoder. In the first, the compact image regions localized by the proposed method are visually appealing. Similarly, in the second, the identified ECG features are biologically plausible and consistent with cardiac electrophysiological principles while locating subtle anomalies in a QRS complex that may not be discernible by the naked eye. Overall, the proposed method compares favorably with state-of-the-art competitors. Accompanying this paper is a Python library dnn-locate (https://dnn-locate.readthedocs.io/en/latest/) that implements the proposed approach.
* 27 pages, 11 figures
A Closer Look at Novel Class Discovery from the Labeled Set
Sep 21, 2022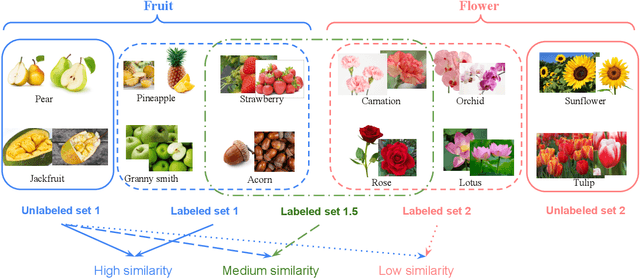
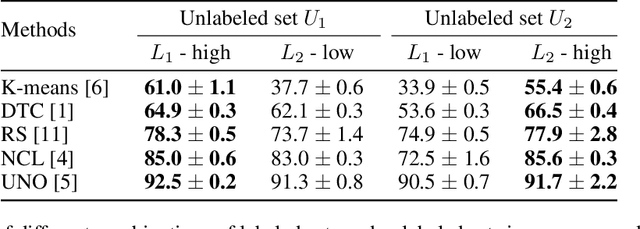
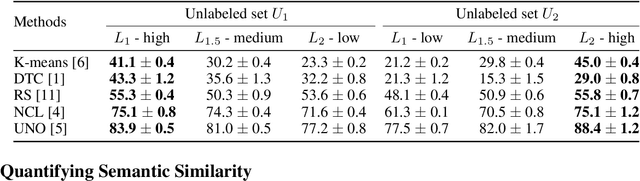
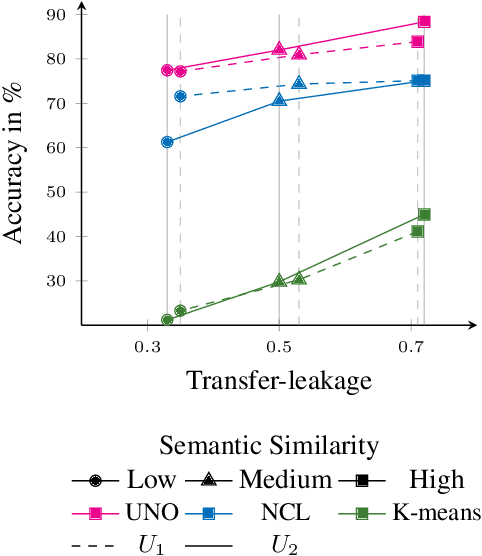
Novel class discovery (NCD) aims to infer novel categories in an unlabeled dataset leveraging prior knowledge of a labeled set comprising disjoint but related classes. Existing research focuses primarily on utilizing the labeled set at the methodological level, with less emphasis on the analysis of the labeled set itself. Thus, in this paper, we rethink novel class discovery from the labeled set and focus on two core questions: (i) Given a specific unlabeled set, what kind of labeled set can best support novel class discovery? (ii) A fundamental premise of NCD is that the labeled set must be related to the unlabeled set, but how can we measure this relation? For (i), we propose and substantiate the hypothesis that NCD could benefit more from a labeled set with a large degree of semantic similarity to the unlabeled set. Specifically, we establish an extensive and large-scale benchmark with varying degrees of semantic similarity between labeled/unlabeled datasets on ImageNet by leveraging its hierarchical class structure. As a sharp contrast, the existing NCD benchmarks are developed based on labeled sets with different number of categories and images, and completely ignore the semantic relation. For (ii), we introduce a mathematical definition for quantifying the semantic similarity between labeled and unlabeled sets. In addition, we use this metric to confirm the validity of our proposed benchmark and demonstrate that it highly correlates with NCD performance. Furthermore, without quantitative analysis, previous works commonly believe that label information is always beneficial. However, counterintuitively, our experimental results show that using labels may lead to sub-optimal outcomes in low-similarity settings.
RankSEG: A Consistent Ranking-based Framework for Segmentation
Jun 27, 2022
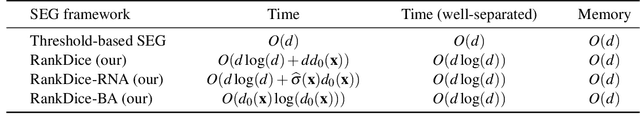
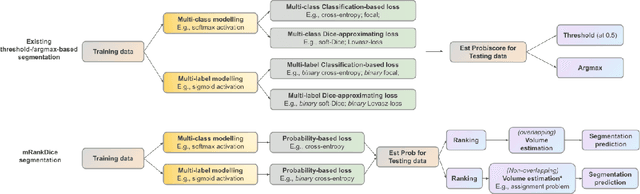
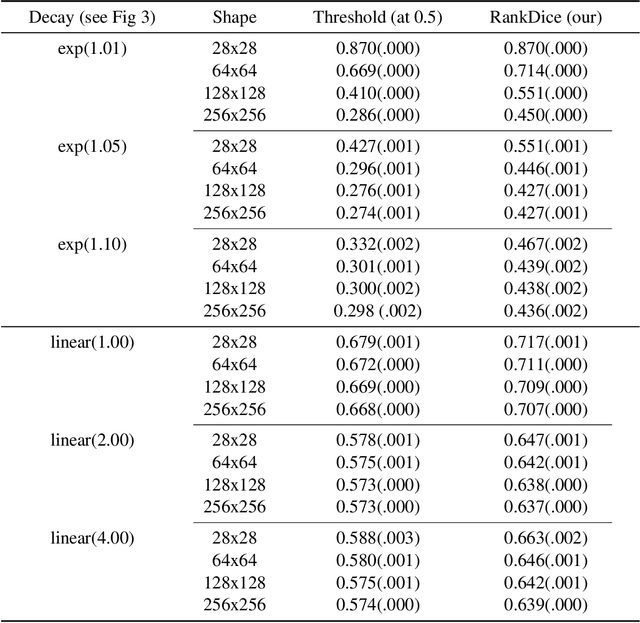
Segmentation has emerged as a fundamental field of computer vision and natural language processing, which assigns a label to every pixel/feature to extract regions of interest from an image/text. To evaluate the performance of segmentation, the Dice and IoU metrics are used to measure the degree of overlap between the ground truth and the predicted segmentation. In this paper, we establish a theoretical foundation of segmentation with respect to the Dice/IoU metrics, including the Bayes rule and Dice/IoU-calibration, analogous to classification-calibration or Fisher consistency in classification. We prove that the existing thresholding-based framework with most operating losses are not consistent with respect to the Dice/IoU metrics, and thus may lead to a suboptimal solution. To address this pitfall, we propose a novel consistent ranking-based framework, namely RankDice/RankIoU, inspired by plug-in rules of the Bayes segmentation rule. Three numerical algorithms with GPU parallel execution are developed to implement the proposed framework in large-scale and high-dimensional segmentation. We study statistical properties of the proposed framework. We show it is Dice-/IoU-calibrated, and its excess risk bounds and the rate of convergence are also provided. The numerical effectiveness of RankDice/mRankDice is demonstrated in various simulated examples and Fine-annotated CityScapes and Pascal VOC datasets with state-of-the-art deep learning architectures.
Two-level monotonic multistage recommender systems
Oct 06, 2021


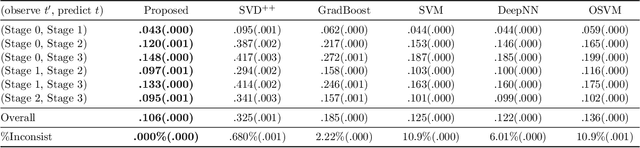
A recommender system learns to predict the user-specific preference or intention over many items simultaneously for all users, making personalized recommendations based on a relatively small number of observations. One central issue is how to leverage three-way interactions, referred to as user-item-stage dependencies on a monotonic chain of events, to enhance the prediction accuracy. A monotonic chain of events occurs, for instance, in an article sharing dataset, where a ``follow'' action implies a ``like'' action, which in turn implies a ``view'' action. In this article, we develop a multistage recommender system utilizing a two-level monotonic property characterizing a monotonic chain of events for personalized prediction. Particularly, we derive a large-margin classifier based on a nonnegative additive latent factor model in the presence of a high percentage of missing observations, particularly between stages, reducing the number of model parameters for personalized prediction while guaranteeing prediction consistency. On this ground, we derive a regularized cost function to learn user-specific behaviors at different stages, linking decision functions to numerical and categorical covariates to model user-item-stage interactions. Computationally, we derive an algorithm based on blockwise coordinate descent. Theoretically, we show that the two-level monotonic property enhances the accuracy of learning as compared to a standard method treating each stage individually and an ordinal method utilizing only one-level monotonicity. Finally, the proposed method compares favorably with existing methods in simulations and an article sharing dataset.
Significance tests of feature relevance for a blackbox learner
Mar 02, 2021



An exciting recent development is the uptake of deep learning in many scientific fields, where the objective is seeking novel scientific insights and discoveries. To interpret a learning outcome, researchers perform hypothesis testing for explainable features to advance scientific domain knowledge. In such a situation, testing for a blackbox learner poses a severe challenge because of intractable models, unknown limiting distributions of parameter estimates, and high computational constraints. In this article, we derive two consistent tests for the feature relevance of a blackbox learner. The first one evaluates a loss difference with perturbation on an inference sample, which is independent of an estimation sample used for parameter estimation in model fitting. The second further splits the inference sample into two but does not require data perturbation. Also, we develop their combined versions by aggregating the order statistics of the $p$-values based on repeated sample splitting. To estimate the splitting ratio and the perturbation size, we develop adaptive splitting schemes for suitably controlling the Type \rom{1} error subject to computational constraints. By deflating the \textit{bias-sd-ratio}, we establish asymptotic null distributions of the test statistics and their consistency in terms of statistical power. Our theoretical power analysis and simulations indicate that the one-split test is more powerful than the two-split test, though the latter is easier to apply for large datasets. Moreover, the combined tests are more stable while compensating for a power loss by repeated sample splitting. Numerically, we demonstrate the utility of the proposed tests on two benchmark examples. Accompanying this paper is our Python library {\tt dnn-inference} https://dnn-inference.readthedocs.io/en/latest/ that implements the proposed tests.