 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Score Inference for Multimodal Data
Mar 27, 2026Accurate uncertainty quantification is crucial for making reliable decisions in various supervised learning scenarios, particularly when dealing with complex, multimodal data such as images and text. Current approaches often face notable limitations, including rigid assumptions and limited generalizability, constraining their effectiveness across diverse supervised learning tasks. To overcome these limitations, we introduce Generative Score Inference (GSI), a flexible inference framework capable of constructing statistically valid and informative prediction and confidence sets across a wide range of multimodal learning problems. GSI utilizes synthetic samples generated by deep generative models to approximate conditional score distributions, facilitating precise uncertainty quantification without imposing restrictive assumptions about the data or tasks. We empirically validate GSI's capabilities through two representative scenarios: hallucination detection in large language models and uncertainty estimation in image captioning. Our method achieves state-of-the-art performance in hallucination detection and robust predictive uncertainty in image captioning, and its performance is positively influenced by the quality of the underlying generative model. These findings underscore the potential of GSI as a versatile inference framework, significantly enhancing uncertainty quantification and trustworthiness in multimodal learning.
Manifold-Aligned Generative Transport
Feb 23, 2026High-dimensional generative modeling is fundamentally a manifold-learning problem: real data concentrate near a low-dimensional structure embedded in the ambient space. Effective generators must therefore balance support fidelity -- placing probability mass near the data manifold -- with sampling efficiency. Diffusion models often capture near-manifold structure but require many iterative denoising steps and can leak off-support; normalizing flows sample in one pass but are limited by invertibility and dimension preservation. We propose MAGT (Manifold-Aligned Generative Transport), a flow-like generator that learns a one-shot, manifold-aligned transport from a low-dimensional base distribution to the data space. Training is performed at a fixed Gaussian smoothing level, where the score is well-defined and numerically stable. We approximate this fixed-level score using a finite set of latent anchor points with self-normalized importance sampling, yielding a tractable objective. MAGT samples in a single forward pass, concentrates probability near the learned support, and induces an intrinsic density with respect to the manifold volume measure, enabling principled likelihood evaluation for generated samples. We establish finite-sample Wasserstein bounds linking smoothing level and score-approximation accuracy to generative fidelity, and empirically improve fidelity and manifold concentration across synthetic and benchmark datasets while sampling substantially faster than diffusion models.
Ice Cream Doesn't Cause Drowning: Benchmarking LLMs Against Statistical Pitfalls in Causal Inference
May 19, 2025Reliable causal inference is essential for making decisions in high-stakes areas like medicine, economics, and public policy. However, it remains unclear whether large language models (LLMs) can handle rigorous and trustworthy statistical causal inference. Current benchmarks usually involve simplified tasks. For example, these tasks might only ask LLMs to identify semantic causal relationships or draw conclusions directly from raw data. As a result, models may overlook important statistical pitfalls, such as Simpson's paradox or selection bias. This oversight limits the applicability of LLMs in the real world. To address these limitations, we propose CausalPitfalls, a comprehensive benchmark designed to rigorously evaluate the capability of LLMs in overcoming common causal inference pitfalls. Our benchmark features structured challenges across multiple difficulty levels, each paired with grading rubrics. This approach allows us to quantitatively measure both causal reasoning capabilities and the reliability of LLMs' responses. We evaluate models using two protocols: (1) direct prompting, which assesses intrinsic causal reasoning, and (2) code-assisted prompting, where models generate executable code for explicit statistical analysis. Additionally, we validate the effectiveness of this judge by comparing its scoring with assessments from human experts. Our results reveal significant limitations in current LLMs when performing statistical causal inference. The CausalPitfalls benchmark provides essential guidance and quantitative metrics to advance the development of trustworthy causal reasoning systems.
Conditional Data Synthesis Augmentation
Apr 10, 2025Reliable machine learning and statistical analysis rely on diverse, well-distributed training data. However, real-world datasets are often limited in size and exhibit underrepresentation across key subpopulations, leading to biased predictions and reduced performance, particularly in supervised tasks such as classification. To address these challenges, we propose Conditional Data Synthesis Augmentation (CoDSA), a novel framework that leverages generative models, such as diffusion models, to synthesize high-fidelity data for improving model performance across multimodal domains including tabular, textual, and image data. CoDSA generates synthetic samples that faithfully capture the conditional distributions of the original data, with a focus on under-sampled or high-interest regions. Through transfer learning, CoDSA fine-tunes pre-trained generative models to enhance the realism of synthetic data and increase sample density in sparse areas. This process preserves inter-modal relationships, mitigates data imbalance, improves domain adaptation, and boosts generalization. We also introduce a theoretical framework that quantifies the statistical accuracy improvements enabled by CoDSA as a function of synthetic sample volume and targeted region allocation, providing formal guarantees of its effectiveness. Extensive experiments demonstrate that CoDSA consistently outperforms non-adaptive augmentation strategies and state-of-the-art baselines in both supervised and unsupervised settings.
Generative Distribution Prediction: A Unified Approach to Multimodal Learning
Feb 10, 2025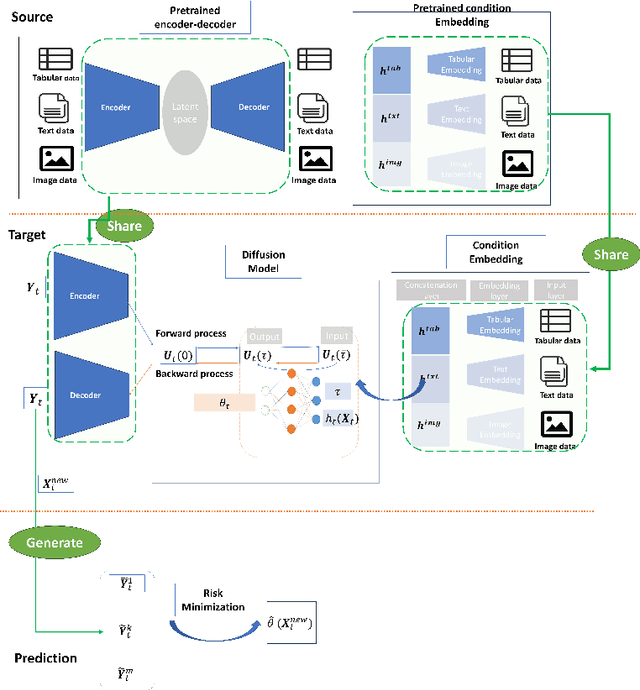
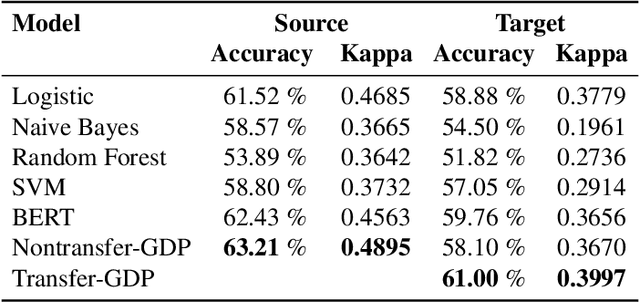
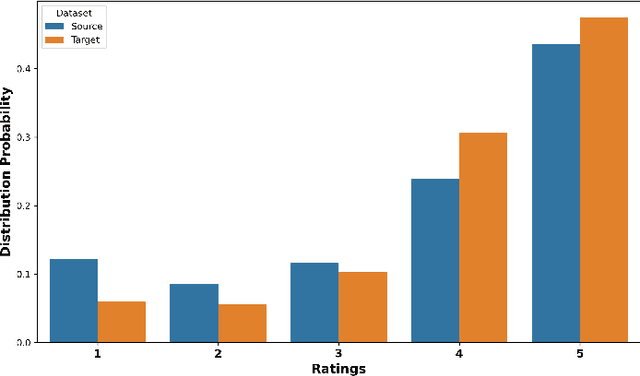
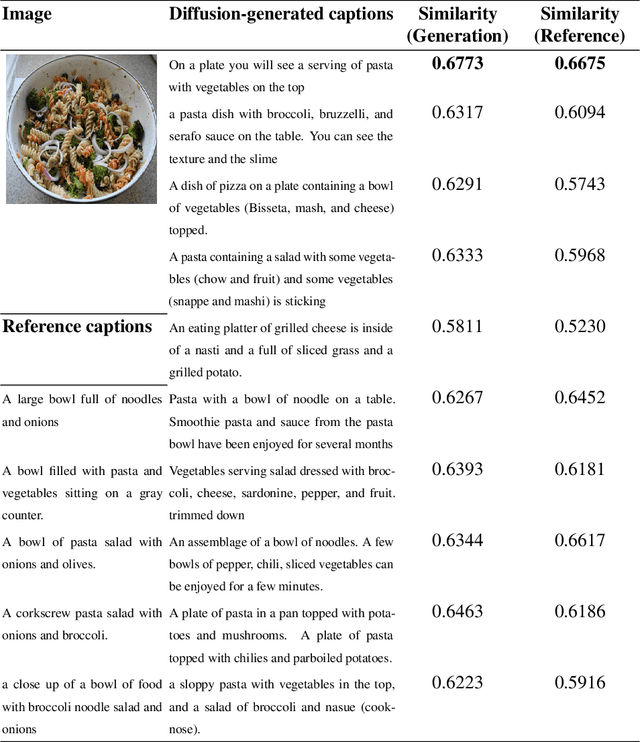
Accurate prediction with multimodal data-encompassing tabular, textual, and visual inputs or outputs-is fundamental to advancing analytics in diverse application domains. Traditional approaches often struggle to integrate heterogeneous data types while maintaining high predictive accuracy. We introduce Generative Distribution Prediction (GDP), a novel framework that leverages multimodal synthetic data generation-such as conditional diffusion models-to enhance predictive performance across structured and unstructured modalities. GDP is model-agnostic, compatible with any high-fidelity generative model, and supports transfer learning for domain adaptation. We establish a rigorous theoretical foundation for GDP, providing statistical guarantees on its predictive accuracy when using diffusion models as the generative backbone. By estimating the data-generating distribution and adapting to various loss functions for risk minimization, GDP enables accurate point predictions across multimodal settings. We empirically validate GDP on four supervised learning tasks-tabular data prediction, question answering, image captioning, and adaptive quantile regression-demonstrating its versatility and effectiveness across diverse domains.
Enhancing Accuracy in Generative Models via Knowledge Transfer
May 27, 2024This paper investigates the accuracy of generative models and the impact of knowledge transfer on their generation precision. Specifically, we examine a generative model for a target task, fine-tuned using a pre-trained model from a source task. Building on the "Shared Embedding" concept, which bridges the source and target tasks, we introduce a novel framework for transfer learning under distribution metrics such as the Kullback-Leibler divergence. This framework underscores the importance of leveraging inherent similarities between diverse tasks despite their distinct data distributions. Our theory suggests that the shared structures can augment the generation accuracy for a target task, reliant on the capability of a source model to identify shared structures and effective knowledge transfer from source to target learning. To demonstrate the practical utility of this framework, we explore the theoretical implications for two specific generative models: diffusion and normalizing flows. The results show enhanced performance in both models over their non-transfer counterparts, indicating advancements for diffusion models and providing fresh insights into normalizing flows in transfer and non-transfer settings. These results highlight the significant contribution of knowledge transfer in boosting the generation capabilities of these models.
Boosting Summarization with Normalizing Flows and Aggressive Training
Nov 01, 2023This paper presents FlowSUM, a normalizing flows-based variational encoder-decoder framework for Transformer-based summarization. Our approach tackles two primary challenges in variational summarization: insufficient semantic information in latent representations and posterior collapse during training. To address these challenges, we employ normalizing flows to enable flexible latent posterior modeling, and we propose a controlled alternate aggressive training (CAAT) strategy with an improved gate mechanism. Experimental results show that FlowSUM significantly enhances the quality of generated summaries and unleashes the potential for knowledge distillation with minimal impact on inference time. Furthermore, we investigate the issue of posterior collapse in normalizing flows and analyze how the summary quality is affected by the training strategy, gate initialization, and the type and number of normalizing flows used, offering valuable insights for future research.
Boosting Data Analytics With Synthetic Volume Expansion
Oct 27, 2023



Synthetic data generation, a cornerstone of Generative Artificial Intelligence, signifies a paradigm shift in data science by addressing data scarcity and privacy while enabling unprecedented performance. As synthetic data gains prominence, questions arise concerning the accuracy of statistical methods when applied to synthetic data compared to raw data. In this article, we introduce the Synthetic Data Generation for Analytics framework. This framework employs statistical methods on high-fidelity synthetic data generated by advanced models such as tabular diffusion and Generative Pre-trained Transformer models. These models, trained on raw data, are further enhanced with insights from pertinent studies. A significant discovery within this framework is the generational effect: the error of a statistical method on synthetic data initially diminishes with added synthetic data but may eventually increase or plateau. This phenomenon, rooted in the complexities of replicating raw data distributions, highlights a "reflection point"--an optimal threshold in the size of synthetic data determined by specific error metrics. Through three illustrative case studies-sentiment analysis of texts, predictive modeling of structured data, and inference in tabular data--we demonstrate the effectiveness of this framework over traditional ones. We underline its potential to amplify various statistical methods, including gradient boosting for prediction and hypothesis testing, thereby underscoring the transformative potential of synthetic data generation in data science.
Causal Discovery with Generalized Linear Models through Peeling Algorithms
Oct 25, 2023



This article presents a novel method for causal discovery with generalized structural equation models suited for analyzing diverse types of outcomes, including discrete, continuous, and mixed data. Causal discovery often faces challenges due to unmeasured confounders that hinder the identification of causal relationships. The proposed approach addresses this issue by developing two peeling algorithms (bottom-up and top-down) to ascertain causal relationships and valid instruments. This approach first reconstructs a super-graph to represent ancestral relationships between variables, using a peeling algorithm based on nodewise GLM regressions that exploit relationships between primary and instrumental variables. Then, it estimates parent-child effects from the ancestral relationships using another peeling algorithm while deconfounding a child's model with information borrowed from its parents' models. The article offers a theoretical analysis of the proposed approach, which establishes conditions for model identifiability and provides statistical guarantees for accurately discovering parent-child relationships via the peeling algorithms. Furthermore, the article presents numerical experiments showcasing the effectiveness of our approach in comparison to state-of-the-art structure learning methods without confounders. Lastly, it demonstrates an application to Alzheimer's disease (AD), highlighting the utility of the method in constructing gene-to-gene and gene-to-disease regulatory networks involving Single Nucleotide Polymorphisms (SNPs) for healthy and AD subjects.
Perturbation-Assisted Sample Synthesis: A Novel Approach for Uncertainty Quantification
May 30, 2023



This paper introduces a novel generator called Perturbation-Assisted Sample Synthesis (PASS), designed for drawing reliable conclusions from complex data, especially when using advanced modeling techniques like deep neural networks. PASS utilizes perturbation to generate synthetic data that closely mirrors the distribution of raw data, encompassing numerical and unstructured data types such as gene expression, images, and text. By estimating the data-generating distribution and leveraging large pre-trained generative models, PASS enhances estimation accuracy, providing an estimated distribution of any statistic through Monte Carlo experiments. Building on PASS, we propose a generative inference framework called Perturbation-Assisted Inference (PAI), which offers a statistical guarantee of validity. In pivotal inference, PAI enables accurate conclusions without knowing a pivotal's distribution as in simulations, even with limited data. In non-pivotal situations, we train PASS using an independent holdout sample, resulting in credible conclusions. To showcase PAI's capability in tackling complex problems, we highlight its applications in three domains: image synthesis inference, sentiment word inference, and multimodal inference via stable diffusion.