 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMorphSAM: Learning the Morphological Prompts from Atlases for Spine Image Segmentation
Jun 16, 2025Spine image segmentation is crucial for clinical diagnosis and treatment of spine diseases. The complex structure of the spine and the high morphological similarity between individual vertebrae and adjacent intervertebral discs make accurate spine segmentation a challenging task. Although the Segment Anything Model (SAM) has been developed, it still struggles to effectively capture and utilize morphological information, limiting its ability to enhance spine image segmentation performance. To address these challenges, in this paper, we propose a MorphSAM that explicitly learns morphological information from atlases, thereby strengthening the spine image segmentation performance of SAM. Specifically, the MorphSAM includes two fully automatic prompt learning networks, 1) an anatomical prompt learning network that directly learns morphological information from anatomical atlases, and 2) a semantic prompt learning network that derives morphological information from text descriptions converted from the atlases. Then, the two learned morphological prompts are fed into the SAM model to boost the segmentation performance. We validate our MorphSAM on two spine image segmentation tasks, including a spine anatomical structure segmentation task with CT images and a lumbosacral plexus segmentation task with MR images. Experimental results demonstrate that our MorphSAM achieves superior segmentation performance when compared to the state-of-the-art methods.
Mamba-based Deep Learning Approaches for Sleep Staging on a Wireless Multimodal Wearable System without Electroencephalography
Dec 20, 2024



Study Objectives: We investigate using Mamba-based deep learning approaches for sleep staging on signals from ANNE One (Sibel Health, Evanston, IL), a minimally intrusive dual-sensor wireless wearable system measuring chest electrocardiography (ECG), triaxial accelerometry, and temperature, as well as finger photoplethysmography (PPG) and temperature. Methods: We obtained wearable sensor recordings from 360 adults undergoing concurrent clinical polysomnography (PSG) at a tertiary care sleep lab. PSG recordings were scored according to AASM criteria. PSG and wearable sensor data were automatically aligned using their ECG channels with manual confirmation by visual inspection. We trained Mamba-based models with both convolutional-recurrent neural network (CRNN) and the recurrent neural network (RNN) architectures on these recordings. Ensembling of model variants with similar architectures was performed. Results: Our best approach, after ensembling, attains a 3-class (wake, NREM, REM) balanced accuracy of 83.50%, F1 score of 84.16%, Cohen's $\kappa$ of 72.68%, and a MCC score of 72.84%; a 4-class (wake, N1/N2, N3, REM) balanced accuracy of 74.64%, F1 score of 74.56%, Cohen's $\kappa$ of 61.63%, and MCC score of 62.04%; a 5-class (wake, N1, N2, N3, REM) balanced accuracy of 64.30%, F1 score of 66.97%, Cohen's $\kappa$ of 53.23%, MCC score of 54.38%. Conclusions: Deep learning models can infer major sleep stages from a wearable system without electroencephalography (EEG) and can be successfully applied to data from adults attending a tertiary care sleep clinic.
Learning Soft Driving Constraints from Vectorized Scene Embeddings while Imitating Expert Trajectories
Dec 07, 2024


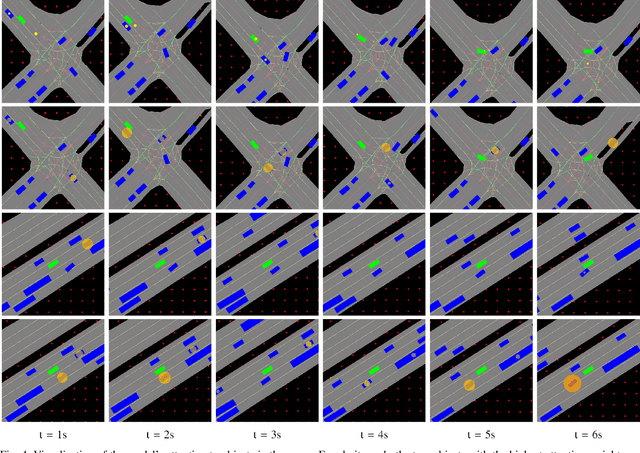
The primary goal of motion planning is to generate safe and efficient trajectories for vehicles. Traditionally, motion planning models are trained using imitation learning to mimic the behavior of human experts. However, these models often lack interpretability and fail to provide clear justifications for their decisions. We propose a method that integrates constraint learning into imitation learning by extracting driving constraints from expert trajectories. Our approach utilizes vectorized scene embeddings that capture critical spatial and temporal features, enabling the model to identify and generalize constraints across various driving scenarios. We formulate the constraint learning problem using a maximum entropy model, which scores the motion planner's trajectories based on their similarity to the expert trajectory. By separating the scoring process into distinct reward and constraint streams, we improve both the interpretability of the planner's behavior and its attention to relevant scene components. Unlike existing constraint learning methods that rely on simulators and are typically embedded in reinforcement learning (RL) or inverse reinforcement learning (IRL) frameworks, our method operates without simulators, making it applicable to a wider range of datasets and real-world scenarios. Experimental results on the InD and TrafficJams datasets demonstrate that incorporating driving constraints enhances model interpretability and improves closed-loop performance.
Leveraging Black-box Models to Assess Feature Importance in Unconditional Distribution
Dec 07, 2024



Understanding how changes in explanatory features affect the unconditional distribution of the outcome is important in many applications. However, existing black-box predictive models are not readily suited for analyzing such questions. In this work, we develop an approximation method to compute the feature importance curves relevant to the unconditional distribution of outcomes, while leveraging the power of pre-trained black-box predictive models. The feature importance curves measure the changes across quantiles of outcome distribution given an external impact of change in the explanatory features. Through extensive numerical experiments and real data examples, we demonstrate that our approximation method produces sparse and faithful results, and is computationally efficient.
DISORF: A Distributed Online NeRF Training and Rendering Framework for Mobile Robots
Mar 01, 2024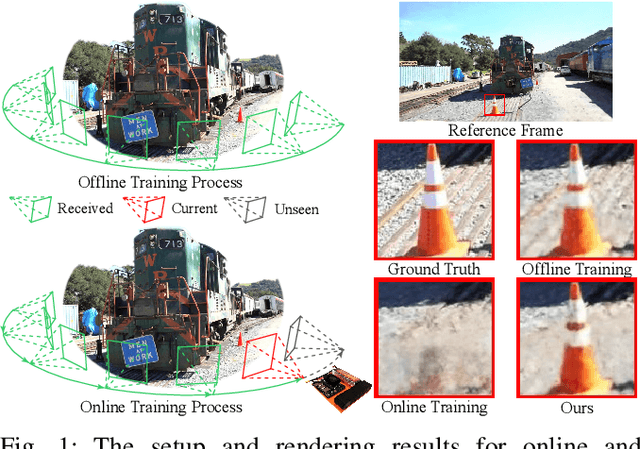
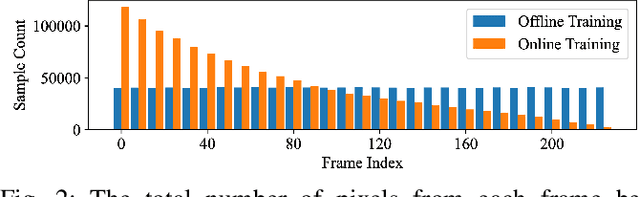
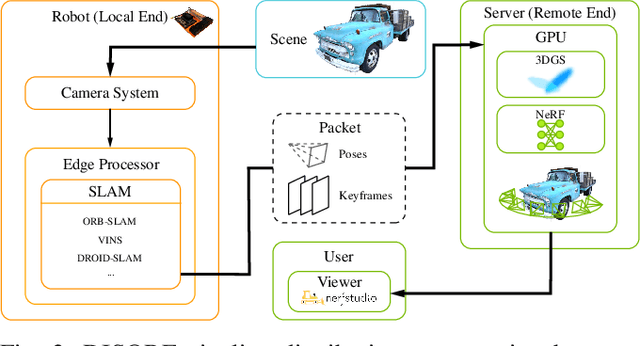

We present a framework, DISORF, to enable online 3D reconstruction and visualization of scenes captured by resource-constrained mobile robots and edge devices. To address the limited compute capabilities of edge devices and potentially limited network availability, we design a framework that efficiently distributes computation between the edge device and remote server. We leverage on-device SLAM systems to generate posed keyframes and transmit them to remote servers that can perform high quality 3D reconstruction and visualization at runtime by leveraging NeRF models. We identify a key challenge with online NeRF training where naive image sampling strategies can lead to significant degradation in rendering quality. We propose a novel shifted exponential frame sampling method that addresses this challenge for online NeRF training. We demonstrate the effectiveness of our framework in enabling high-quality real-time reconstruction and visualization of unknown scenes as they are captured and streamed from cameras in mobile robots and edge devices.
Evaluating Large Language Models for Radiology Natural Language Processing
Jul 27, 2023
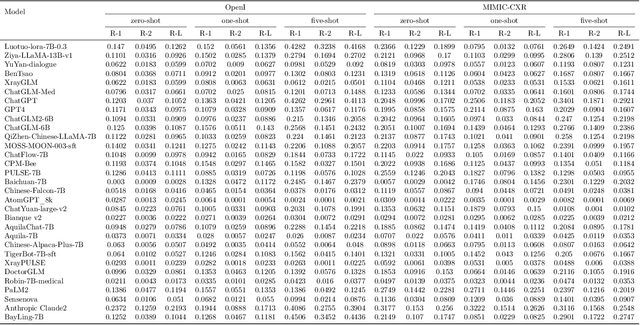
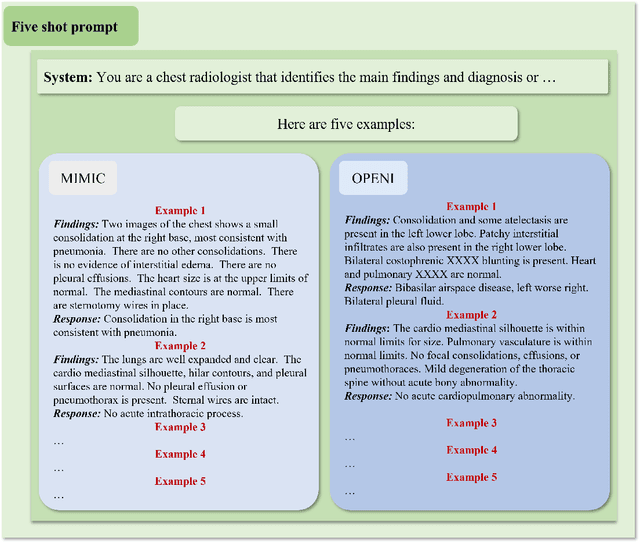
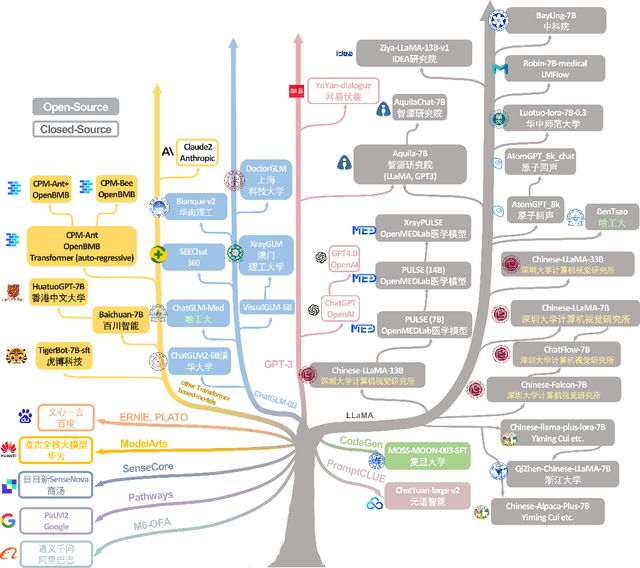
The rise of large language models (LLMs) has marked a pivotal shift in the field of natural language processing (NLP). LLMs have revolutionized a multitude of domains, and they have made a significant impact in the medical field. Large language models are now more abundant than ever, and many of these models exhibit bilingual capabilities, proficient in both English and Chinese. However, a comprehensive evaluation of these models remains to be conducted. This lack of assessment is especially apparent within the context of radiology NLP. This study seeks to bridge this gap by critically evaluating thirty two LLMs in interpreting radiology reports, a crucial component of radiology NLP. Specifically, the ability to derive impressions from radiologic findings is assessed. The outcomes of this evaluation provide key insights into the performance, strengths, and weaknesses of these LLMs, informing their practical applications within the medical domain.
ENVIDR: Implicit Differentiable Renderer with Neural Environment Lighting
Mar 23, 2023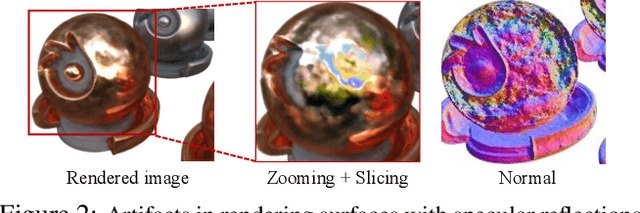
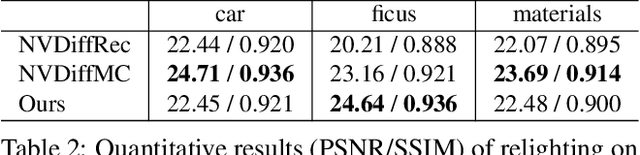
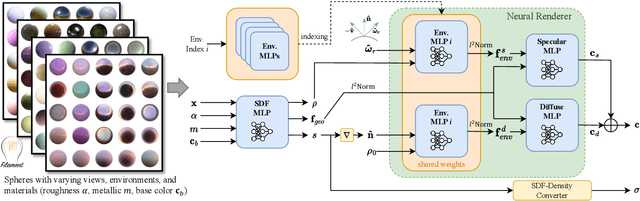

Recent advances in neural rendering have shown great potential for reconstructing scenes from multiview images. However, accurately representing objects with glossy surfaces remains a challenge for existing methods. In this work, we introduce ENVIDR, a rendering and modeling framework for high-quality rendering and reconstruction of surfaces with challenging specular reflections. To achieve this, we first propose a novel neural renderer with decomposed rendering components to learn the interaction between surface and environment lighting. This renderer is trained using existing physically based renderers and is decoupled from actual scene representations. We then propose an SDF-based neural surface model that leverages this learned neural renderer to represent general scenes. Our model additionally synthesizes indirect illuminations caused by inter-reflections from shiny surfaces by marching surface-reflected rays. We demonstrate that our method outperforms state-of-art methods on challenging shiny scenes, providing high-quality rendering of specular reflections while also enabling material editing and scene relighting.
Data-Adaptive Discriminative Feature Localization with Statistically Guaranteed Interpretation
Nov 18, 2022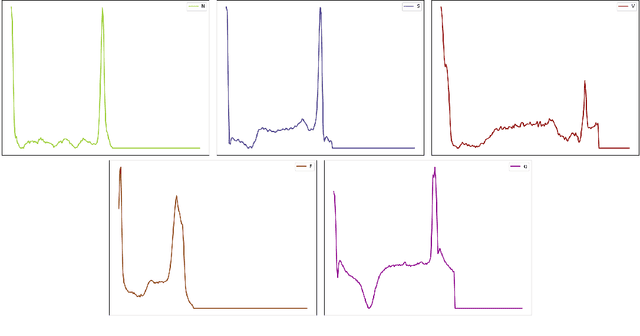

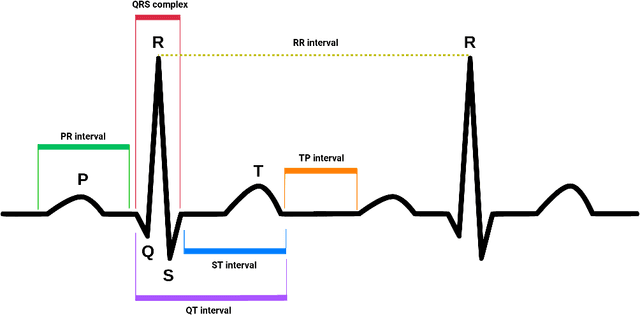

In explainable artificial intelligence, discriminative feature localization is critical to reveal a blackbox model's decision-making process from raw data to prediction. In this article, we use two real datasets, the MNIST handwritten digits and MIT-BIH Electrocardiogram (ECG) signals, to motivate key characteristics of discriminative features, namely adaptiveness, predictive importance and effectiveness. Then, we develop a localization framework based on adversarial attacks to effectively localize discriminative features. In contrast to existing heuristic methods, we also provide a statistically guaranteed interpretability of the localized features by measuring a generalized partial $R^2$. We apply the proposed method to the MNIST dataset and the MIT-BIH dataset with a convolutional auto-encoder. In the first, the compact image regions localized by the proposed method are visually appealing. Similarly, in the second, the identified ECG features are biologically plausible and consistent with cardiac electrophysiological principles while locating subtle anomalies in a QRS complex that may not be discernible by the naked eye. Overall, the proposed method compares favorably with state-of-the-art competitors. Accompanying this paper is a Python library dnn-locate (https://dnn-locate.readthedocs.io/en/latest/) that implements the proposed approach.
* 27 pages, 11 figures
RankSEG: A Consistent Ranking-based Framework for Segmentation
Jun 27, 2022
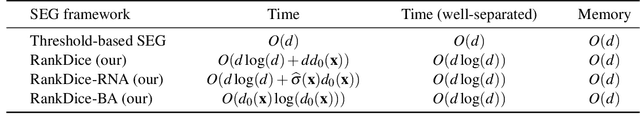
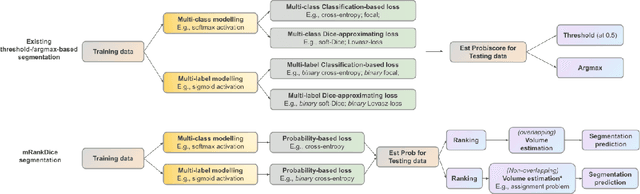
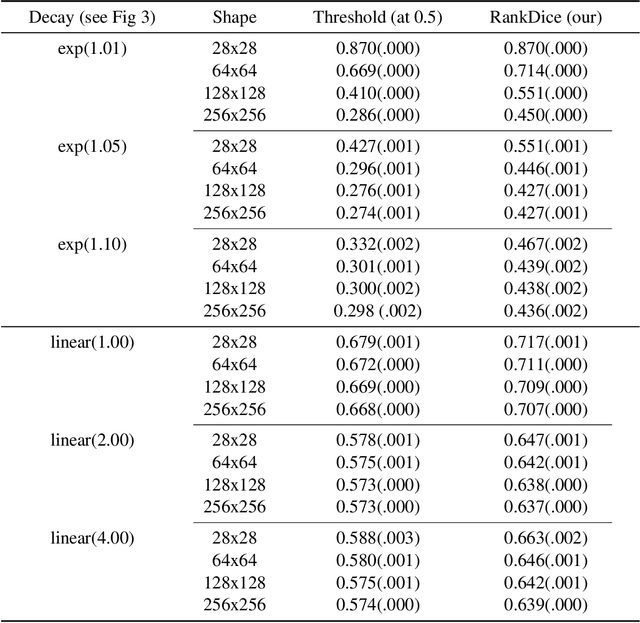
Segmentation has emerged as a fundamental field of computer vision and natural language processing, which assigns a label to every pixel/feature to extract regions of interest from an image/text. To evaluate the performance of segmentation, the Dice and IoU metrics are used to measure the degree of overlap between the ground truth and the predicted segmentation. In this paper, we establish a theoretical foundation of segmentation with respect to the Dice/IoU metrics, including the Bayes rule and Dice/IoU-calibration, analogous to classification-calibration or Fisher consistency in classification. We prove that the existing thresholding-based framework with most operating losses are not consistent with respect to the Dice/IoU metrics, and thus may lead to a suboptimal solution. To address this pitfall, we propose a novel consistent ranking-based framework, namely RankDice/RankIoU, inspired by plug-in rules of the Bayes segmentation rule. Three numerical algorithms with GPU parallel execution are developed to implement the proposed framework in large-scale and high-dimensional segmentation. We study statistical properties of the proposed framework. We show it is Dice-/IoU-calibrated, and its excess risk bounds and the rate of convergence are also provided. The numerical effectiveness of RankDice/mRankDice is demonstrated in various simulated examples and Fine-annotated CityScapes and Pascal VOC datasets with state-of-the-art deep learning architectures.