 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA generalizable 3D framework and model for self-supervised learning in medical imaging
Jan 20, 2025



Current self-supervised learning methods for 3D medical imaging rely on simple pretext formulations and organ- or modality-specific datasets, limiting their generalizability and scalability. We present 3DINO, a cutting-edge SSL method adapted to 3D datasets, and use it to pretrain 3DINO-ViT: a general-purpose medical imaging model, on an exceptionally large, multimodal, and multi-organ dataset of ~100,000 3D medical imaging scans from over 10 organs. We validate 3DINO-ViT using extensive experiments on numerous medical imaging segmentation and classification tasks. Our results demonstrate that 3DINO-ViT generalizes across modalities and organs, including out-of-distribution tasks and datasets, outperforming state-of-the-art methods on the majority of evaluation metrics and labeled dataset sizes. Our 3DINO framework and 3DINO-ViT will be made available to enable research on 3D foundation models or further finetuning for a wide range of medical imaging applications.
SELMA3D challenge: Self-supervised learning for 3D light-sheet microscopy image segmentation
Jan 07, 2025Recent innovations in light sheet microscopy, paired with developments in tissue clearing techniques, enable the 3D imaging of large mammalian tissues with cellular resolution. Combined with the progress in large-scale data analysis, driven by deep learning, these innovations empower researchers to rapidly investigate the morphological and functional properties of diverse biological samples. Segmentation, a crucial preliminary step in the analysis process, can be automated using domain-specific deep learning models with expert-level performance. However, these models exhibit high sensitivity to domain shifts, leading to a significant drop in accuracy when applied to data outside their training distribution. To address this limitation, and inspired by the recent success of self-supervised learning in training generalizable models, we organized the SELMA3D Challenge during the MICCAI 2024 conference. SELMA3D provides a vast collection of light-sheet images from cleared mice and human brains, comprising 35 large 3D images-each with over 1000^3 voxels-and 315 annotated small patches for finetuning, preliminary testing and final testing. The dataset encompasses diverse biological structures, including vessel-like and spot-like structures. Five teams participated in all phases of the challenge, and their proposed methods are reviewed in this paper. Quantitative and qualitative results from most participating teams demonstrate that self-supervised learning on large datasets improves segmentation model performance and generalization. We will continue to support and extend SELMA3D as an inaugural MICCAI challenge focused on self-supervised learning for 3D microscopy image segmentation.
Mamba-based Deep Learning Approaches for Sleep Staging on a Wireless Multimodal Wearable System without Electroencephalography
Dec 20, 2024



Study Objectives: We investigate using Mamba-based deep learning approaches for sleep staging on signals from ANNE One (Sibel Health, Evanston, IL), a minimally intrusive dual-sensor wireless wearable system measuring chest electrocardiography (ECG), triaxial accelerometry, and temperature, as well as finger photoplethysmography (PPG) and temperature. Methods: We obtained wearable sensor recordings from 360 adults undergoing concurrent clinical polysomnography (PSG) at a tertiary care sleep lab. PSG recordings were scored according to AASM criteria. PSG and wearable sensor data were automatically aligned using their ECG channels with manual confirmation by visual inspection. We trained Mamba-based models with both convolutional-recurrent neural network (CRNN) and the recurrent neural network (RNN) architectures on these recordings. Ensembling of model variants with similar architectures was performed. Results: Our best approach, after ensembling, attains a 3-class (wake, NREM, REM) balanced accuracy of 83.50%, F1 score of 84.16%, Cohen's $\kappa$ of 72.68%, and a MCC score of 72.84%; a 4-class (wake, N1/N2, N3, REM) balanced accuracy of 74.64%, F1 score of 74.56%, Cohen's $\kappa$ of 61.63%, and MCC score of 62.04%; a 5-class (wake, N1, N2, N3, REM) balanced accuracy of 64.30%, F1 score of 66.97%, Cohen's $\kappa$ of 53.23%, MCC score of 54.38%. Conclusions: Deep learning models can infer major sleep stages from a wearable system without electroencephalography (EEG) and can be successfully applied to data from adults attending a tertiary care sleep clinic.
A Robust Ensemble Algorithm for Ischemic Stroke Lesion Segmentation: Generalizability and Clinical Utility Beyond the ISLES Challenge
Apr 03, 2024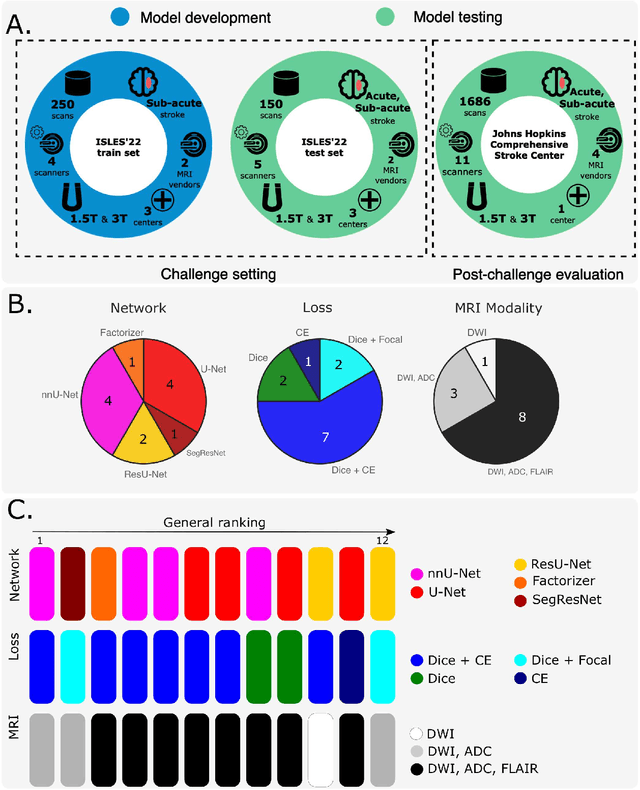
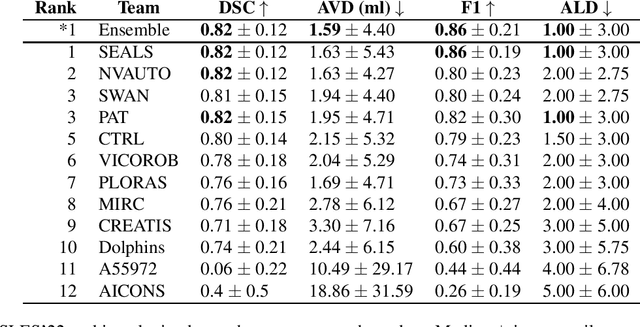
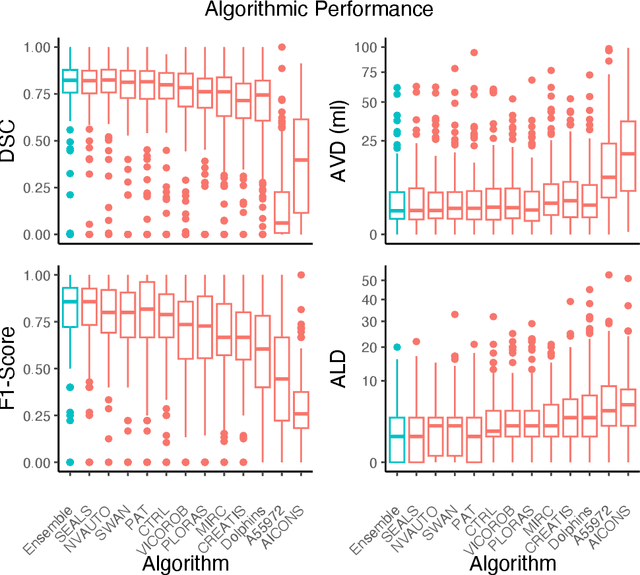
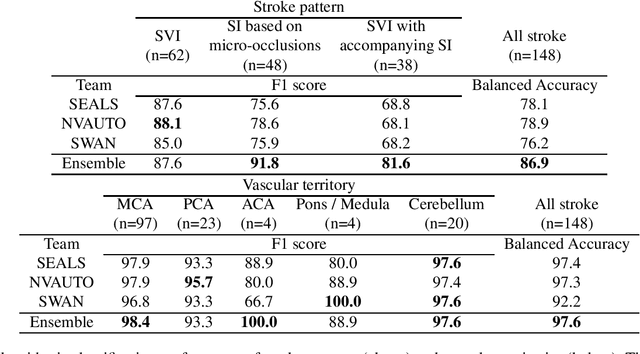
Diffusion-weighted MRI (DWI) is essential for stroke diagnosis, treatment decisions, and prognosis. However, image and disease variability hinder the development of generalizable AI algorithms with clinical value. We address this gap by presenting a novel ensemble algorithm derived from the 2022 Ischemic Stroke Lesion Segmentation (ISLES) challenge. ISLES'22 provided 400 patient scans with ischemic stroke from various medical centers, facilitating the development of a wide range of cutting-edge segmentation algorithms by the research community. Through collaboration with leading teams, we combined top-performing algorithms into an ensemble model that overcomes the limitations of individual solutions. Our ensemble model achieved superior ischemic lesion detection and segmentation accuracy on our internal test set compared to individual algorithms. This accuracy generalized well across diverse image and disease variables. Furthermore, the model excelled in extracting clinical biomarkers. Notably, in a Turing-like test, neuroradiologists consistently preferred the algorithm's segmentations over manual expert efforts, highlighting increased comprehensiveness and precision. Validation using a real-world external dataset (N=1686) confirmed the model's generalizability. The algorithm's outputs also demonstrated strong correlations with clinical scores (admission NIHSS and 90-day mRS) on par with or exceeding expert-derived results, underlining its clinical relevance. This study offers two key findings. First, we present an ensemble algorithm (https://github.com/Tabrisrei/ISLES22_Ensemble) that detects and segments ischemic stroke lesions on DWI across diverse scenarios on par with expert (neuro)radiologists. Second, we show the potential for biomedical challenge outputs to extend beyond the challenge's initial objectives, demonstrating their real-world clinical applicability.
ROOD-MRI: Benchmarking the robustness of deep learning segmentation models to out-of-distribution and corrupted data in MRI
Mar 11, 2022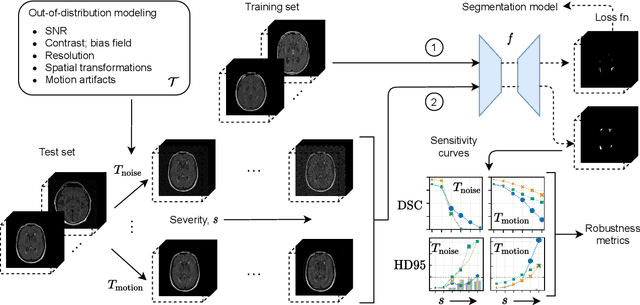
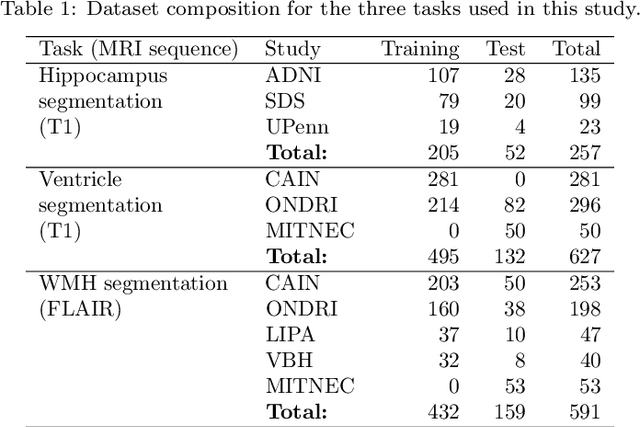
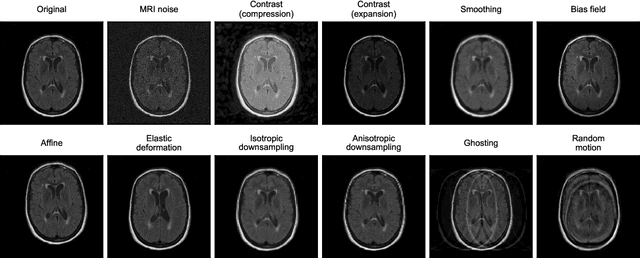
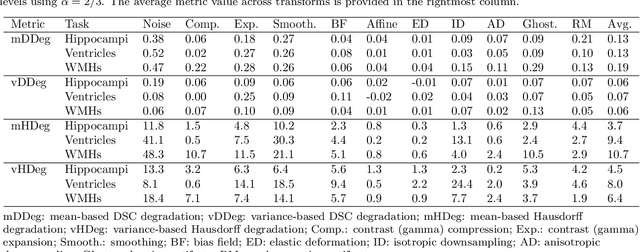
Deep artificial neural networks (DNNs) have moved to the forefront of medical image analysis due to their success in classification, segmentation, and detection challenges. A principal challenge in large-scale deployment of DNNs in neuroimage analysis is the potential for shifts in signal-to-noise ratio, contrast, resolution, and presence of artifacts from site to site due to variances in scanners and acquisition protocols. DNNs are famously susceptible to these distribution shifts in computer vision. Currently, there are no benchmarking platforms or frameworks to assess the robustness of new and existing models to specific distribution shifts in MRI, and accessible multi-site benchmarking datasets are still scarce or task-specific. To address these limitations, we propose ROOD-MRI: a platform for benchmarking the Robustness of DNNs to Out-Of-Distribution (OOD) data, corruptions, and artifacts in MRI. The platform provides modules for generating benchmarking datasets using transforms that model distribution shifts in MRI, implementations of newly derived benchmarking metrics for image segmentation, and examples for using the methodology with new models and tasks. We apply our methodology to hippocampus, ventricle, and white matter hyperintensity segmentation in several large studies, providing the hippocampus dataset as a publicly available benchmark. By evaluating modern DNNs on these datasets, we demonstrate that they are highly susceptible to distribution shifts and corruptions in MRI. We show that while data augmentation strategies can substantially improve robustness to OOD data for anatomical segmentation tasks, modern DNNs using augmentation still lack robustness in more challenging lesion-based segmentation tasks. We finally benchmark U-Nets and transformer-based models, finding consistent differences in robustness to particular classes of transforms across architectures.