 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogic Synthesis Optimization with Predictive Self-Supervision via Causal Transformers
Sep 16, 2024



Contemporary hardware design benefits from the abstraction provided by high-level logic gates, streamlining the implementation of logic circuits. Logic Synthesis Optimization (LSO) operates at one level of abstraction within the Electronic Design Automation (EDA) workflow, targeting improvements in logic circuits with respect to performance metrics such as size and speed in the final layout. Recent trends in the field show a growing interest in leveraging Machine Learning (ML) for EDA, notably through ML-guided logic synthesis utilizing policy-based Reinforcement Learning (RL) methods.Despite these advancements, existing models face challenges such as overfitting and limited generalization, attributed to constrained public circuits and the expressiveness limitations of graph encoders. To address these hurdles, and tackle data scarcity issues, we introduce LSOformer, a novel approach harnessing Autoregressive transformer models and predictive SSL to predict the trajectory of Quality of Results (QoR). LSOformer integrates cross-attention modules to merge insights from circuit graphs and optimization sequences, thereby enhancing prediction accuracy for QoR metrics. Experimental studies validate the effectiveness of LSOformer, showcasing its superior performance over baseline architectures in QoR prediction tasks, where it achieves improvements of 5.74%, 4.35%, and 17.06% on the EPFL, OABCD, and proprietary circuits datasets, respectively, in inductive setup.
MTLSO: A Multi-Task Learning Approach for Logic Synthesis Optimization
Sep 09, 2024



Electronic Design Automation (EDA) is essential for IC design and has recently benefited from AI-based techniques to improve efficiency. Logic synthesis, a key EDA stage, transforms high-level hardware descriptions into optimized netlists. Recent research has employed machine learning to predict Quality of Results (QoR) for pairs of And-Inverter Graphs (AIGs) and synthesis recipes. However, the severe scarcity of data due to a very limited number of available AIGs results in overfitting, significantly hindering performance. Additionally, the complexity and large number of nodes in AIGs make plain GNNs less effective for learning expressive graph-level representations. To tackle these challenges, we propose MTLSO - a Multi-Task Learning approach for Logic Synthesis Optimization. On one hand, it maximizes the use of limited data by training the model across different tasks. This includes introducing an auxiliary task of binary multi-label graph classification alongside the primary regression task, allowing the model to benefit from diverse supervision sources. On the other hand, we employ a hierarchical graph representation learning strategy to improve the model's capacity for learning expressive graph-level representations of large AIGs, surpassing traditional plain GNNs. Extensive experiments across multiple datasets and against state-of-the-art baselines demonstrate the superiority of our method, achieving an average performance gain of 8.22\% for delay and 5.95\% for area.
EWEK-QA: Enhanced Web and Efficient Knowledge Graph Retrieval for Citation-based Question Answering Systems
Jun 14, 2024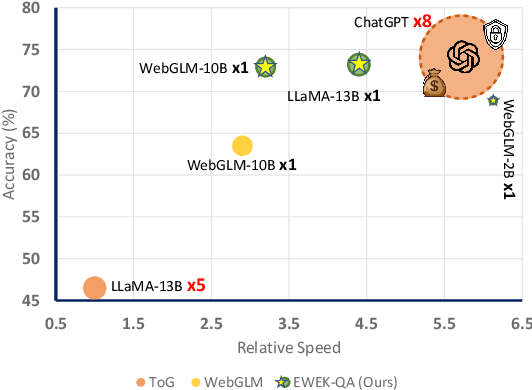
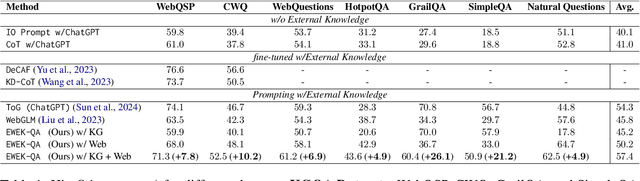
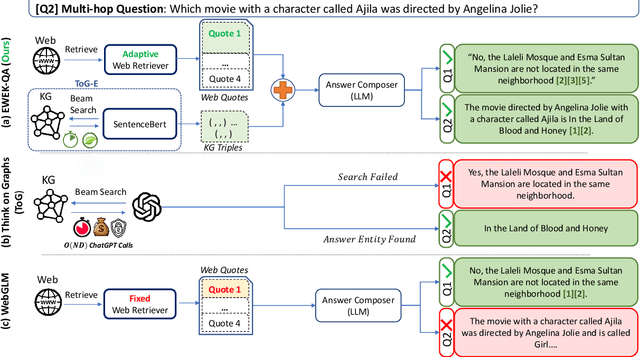
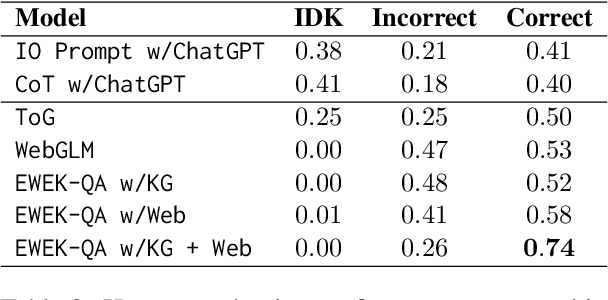
The emerging citation-based QA systems are gaining more attention especially in generative AI search applications. The importance of extracted knowledge provided to these systems is vital from both accuracy (completeness of information) and efficiency (extracting the information in a timely manner). In this regard, citation-based QA systems are suffering from two shortcomings. First, they usually rely only on web as a source of extracted knowledge and adding other external knowledge sources can hamper the efficiency of the system. Second, web-retrieved contents are usually obtained by some simple heuristics such as fixed length or breakpoints which might lead to splitting information into pieces. To mitigate these issues, we propose our enhanced web and efficient knowledge graph (KG) retrieval solution (EWEK-QA) to enrich the content of the extracted knowledge fed to the system. This has been done through designing an adaptive web retriever and incorporating KGs triples in an efficient manner. We demonstrate the effectiveness of EWEK-QA over the open-source state-of-the-art (SoTA) web-based and KG baseline models using a comprehensive set of quantitative and human evaluation experiments. Our model is able to: first, improve the web-retriever baseline in terms of extracting more relevant passages (>20\%), the coverage of answer span (>25\%) and self containment (>35\%); second, obtain and integrate KG triples into its pipeline very efficiently (by avoiding any LLM calls) to outperform the web-only and KG-only SoTA baselines significantly in 7 quantitative QA tasks and our human evaluation.
WERank: Towards Rank Degradation Prevention for Self-Supervised Learning Using Weight Regularization
Feb 14, 2024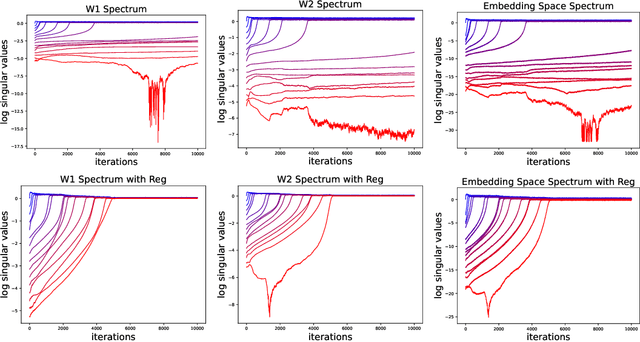
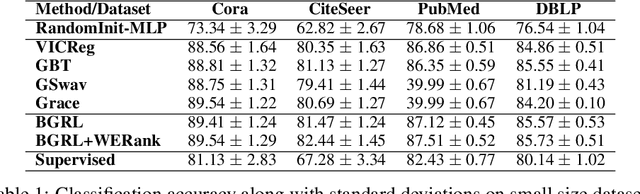
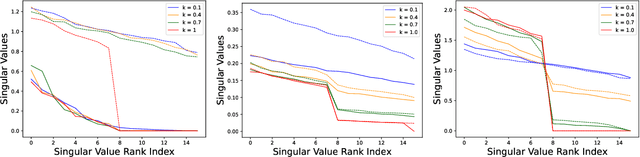
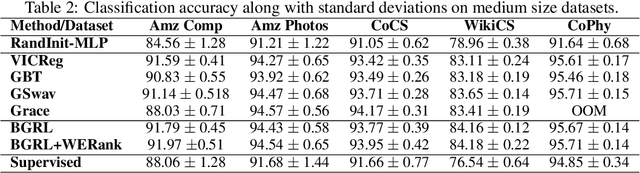
A common phenomena confining the representation quality in Self-Supervised Learning (SSL) is dimensional collapse (also known as rank degeneration), where the learned representations are mapped to a low dimensional subspace of the representation space. The State-of-the-Art SSL methods have shown to suffer from dimensional collapse and fall behind maintaining full rank. Recent approaches to prevent this problem have proposed using contrastive losses, regularization techniques, or architectural tricks. We propose WERank, a new regularizer on the weight parameters of the network to prevent rank degeneration at different layers of the network. We provide empirical evidence and mathematical justification to demonstrate the effectiveness of the proposed regularization method in preventing dimensional collapse. We verify the impact of WERank on graph SSL where dimensional collapse is more pronounced due to the lack of proper data augmentation. We empirically demonstrate that WERank is effective in helping BYOL to achieve higher rank during SSL pre-training and consequently downstream accuracy during evaluation probing. Ablation studies and experimental analysis shed lights on the underlying factors behind the performance gains of the proposed approach.
Scalable Graph Self-Supervised Learning
Feb 14, 2024



In regularization Self-Supervised Learning (SSL) methods for graphs, computational complexity increases with the number of nodes in graphs and embedding dimensions. To mitigate the scalability of non-contrastive graph SSL, we propose a novel approach to reduce the cost of computing the covariance matrix for the pre-training loss function with volume-maximization terms. Our work focuses on reducing the cost associated with the loss computation via graph node or dimension sampling. We provide theoretical insight into why dimension sampling would result in accurate loss computations and support it with mathematical derivation of the novel approach. We develop our experimental setup on the node-level graph prediction tasks, where SSL pre-training has shown to be difficult due to the large size of real world graphs. Our experiments demonstrate that the cost associated with the loss computation can be reduced via node or dimension sampling without lowering the downstream performance. Our results demonstrate that sampling mostly results in improved downstream performance. Ablation studies and experimental analysis are provided to untangle the role of the different factors in the experimental setup.
ExGRG: Explicitly-Generated Relation Graph for Self-Supervised Representation Learning
Feb 09, 2024



Self-supervised Learning (SSL) has emerged as a powerful technique in pre-training deep learning models without relying on expensive annotated labels, instead leveraging embedded signals in unlabeled data. While SSL has shown remarkable success in computer vision tasks through intuitive data augmentation, its application to graph-structured data poses challenges due to the semantic-altering and counter-intuitive nature of graph augmentations. Addressing this limitation, this paper introduces a novel non-contrastive SSL approach to Explicitly Generate a compositional Relation Graph (ExGRG) instead of relying solely on the conventional augmentation-based implicit relation graph. ExGRG offers a framework for incorporating prior domain knowledge and online extracted information into the SSL invariance objective, drawing inspiration from the Laplacian Eigenmap and Expectation-Maximization (EM). Employing an EM perspective on SSL, our E-step involves relation graph generation to identify candidates to guide the SSL invariance objective, and M-step updates the model parameters by integrating the derived relational information. Extensive experimentation on diverse node classification datasets demonstrates the superiority of our method over state-of-the-art techniques, affirming ExGRG as an effective adoption of SSL for graph representation learning.
Todyformer: Towards Holistic Dynamic Graph Transformers with Structure-Aware Tokenization
Feb 02, 2024



Temporal Graph Neural Networks have garnered substantial attention for their capacity to model evolving structural and temporal patterns while exhibiting impressive performance. However, it is known that these architectures are encumbered by issues that constrain their performance, such as over-squashing and over-smoothing. Meanwhile, Transformers have demonstrated exceptional computational capacity to effectively address challenges related to long-range dependencies. Consequently, we introduce Todyformer-a novel Transformer-based neural network tailored for dynamic graphs. It unifies the local encoding capacity of Message-Passing Neural Networks (MPNNs) with the global encoding of Transformers through i) a novel patchifying paradigm for dynamic graphs to improve over-squashing, ii) a structure-aware parametric tokenization strategy leveraging MPNNs, iii) a Transformer with temporal positional-encoding to capture long-range dependencies, and iv) an encoding architecture that alternates between local and global contextualization, mitigating over-smoothing in MPNNs. Experimental evaluations on public benchmark datasets demonstrate that Todyformer consistently outperforms the state-of-the-art methods for downstream tasks. Furthermore, we illustrate the underlying aspects of the proposed model in effectively capturing extensive temporal dependencies in dynamic graphs.
DyG2Vec: Representation Learning for Dynamic Graphs with Self-Supervision
Oct 30, 2022



The challenge in learning from dynamic graphs for predictive tasks lies in extracting fine-grained temporal motifs from an ever-evolving graph. Moreover, task labels are often scarce, costly to obtain, and highly imbalanced for large dynamic graphs. Recent advances in self-supervised learning on graphs demonstrate great potential, but focus on static graphs. State-of-the-art (SoTA) models for dynamic graphs are not only incompatible with the self-supervised learning (SSL) paradigm but also fail to forecast interactions beyond the very near future. To address these limitations, we present DyG2Vec, an SSL-compatible, efficient model for representation learning on dynamic graphs. DyG2Vec uses a window-based mechanism to generate task-agnostic node embeddings that can be used to forecast future interactions. DyG2Vec significantly outperforms SoTA baselines on benchmark datasets for downstream tasks while only requiring a fraction of the training/inference time. We adapt two SSL evaluation mechanisms to make them applicable to dynamic graphs and thus show that SSL pre-training helps learn more robust temporal node representations, especially for scenarios with few labels.
ROOD-MRI: Benchmarking the robustness of deep learning segmentation models to out-of-distribution and corrupted data in MRI
Mar 11, 2022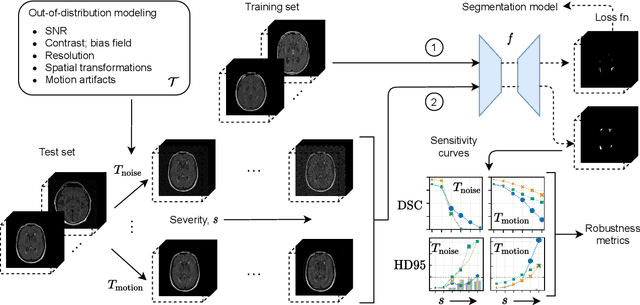
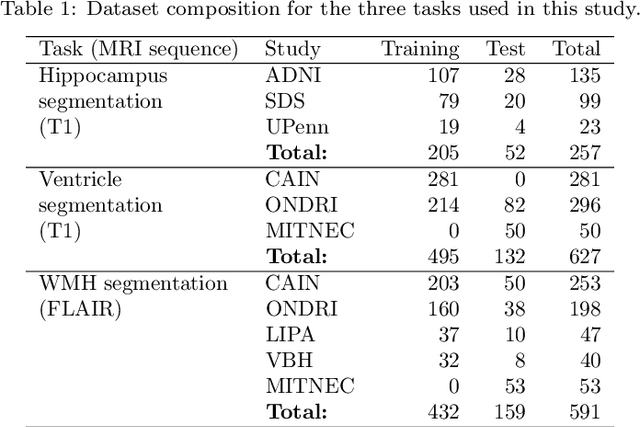
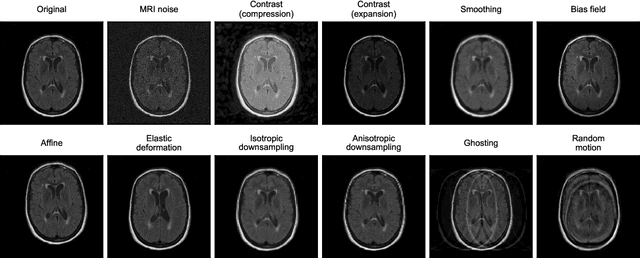
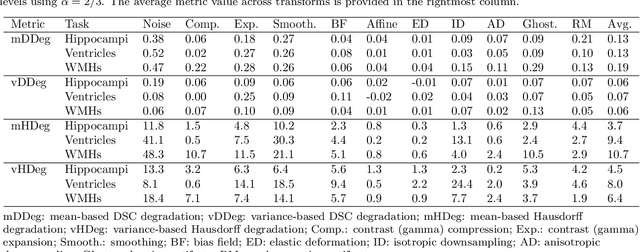
Deep artificial neural networks (DNNs) have moved to the forefront of medical image analysis due to their success in classification, segmentation, and detection challenges. A principal challenge in large-scale deployment of DNNs in neuroimage analysis is the potential for shifts in signal-to-noise ratio, contrast, resolution, and presence of artifacts from site to site due to variances in scanners and acquisition protocols. DNNs are famously susceptible to these distribution shifts in computer vision. Currently, there are no benchmarking platforms or frameworks to assess the robustness of new and existing models to specific distribution shifts in MRI, and accessible multi-site benchmarking datasets are still scarce or task-specific. To address these limitations, we propose ROOD-MRI: a platform for benchmarking the Robustness of DNNs to Out-Of-Distribution (OOD) data, corruptions, and artifacts in MRI. The platform provides modules for generating benchmarking datasets using transforms that model distribution shifts in MRI, implementations of newly derived benchmarking metrics for image segmentation, and examples for using the methodology with new models and tasks. We apply our methodology to hippocampus, ventricle, and white matter hyperintensity segmentation in several large studies, providing the hippocampus dataset as a publicly available benchmark. By evaluating modern DNNs on these datasets, we demonstrate that they are highly susceptible to distribution shifts and corruptions in MRI. We show that while data augmentation strategies can substantially improve robustness to OOD data for anatomical segmentation tasks, modern DNNs using augmentation still lack robustness in more challenging lesion-based segmentation tasks. We finally benchmark U-Nets and transformer-based models, finding consistent differences in robustness to particular classes of transforms across architectures.
Video action recognition for lane-change classification and prediction of surrounding vehicles
Jan 13, 2021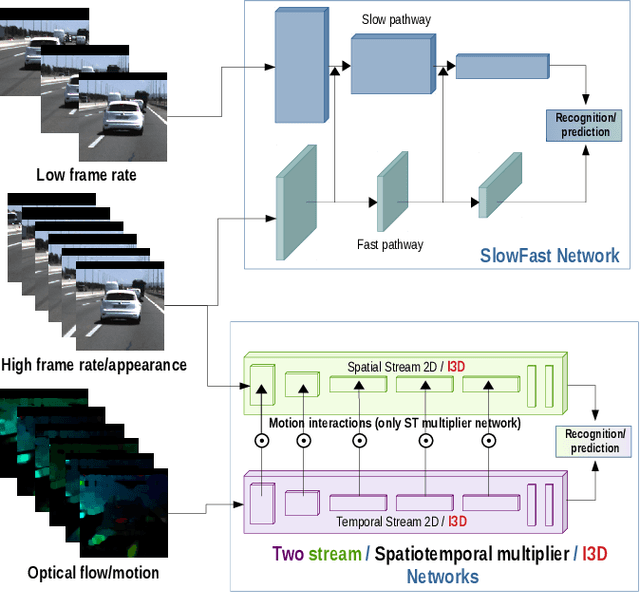
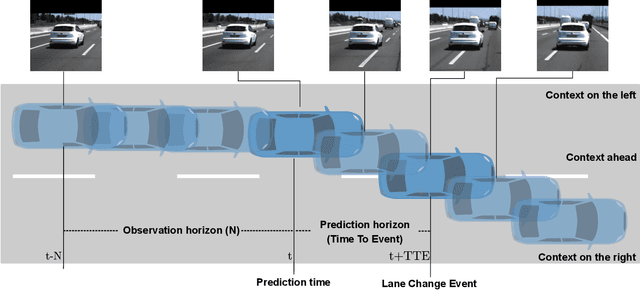


In highway scenarios, an alert human driver will typically anticipate early cut-in/cut-out maneuvers of surrounding vehicles using visual cues mainly. Autonomous vehicles must anticipate these situations at an early stage too, to increase their safety and efficiency. In this work, lane-change recognition and prediction tasks are posed as video action recognition problems. Up to four different two-stream-based approaches, that have been successfully applied to address human action recognition, are adapted here by stacking visual cues from forward-looking video cameras to recognize and anticipate lane-changes of target vehicles. We study the influence of context and observation horizons on performance, and different prediction horizons are analyzed. The different models are trained and evaluated using the PREVENTION dataset. The obtained results clearly demonstrate the potential of these methodologies to serve as robust predictors of future lane-changes of surrounding vehicles proving an accuracy higher than 90% in time horizons of between 1-2 seconds.