 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEWEK-QA: Enhanced Web and Efficient Knowledge Graph Retrieval for Citation-based Question Answering Systems
Jun 14, 2024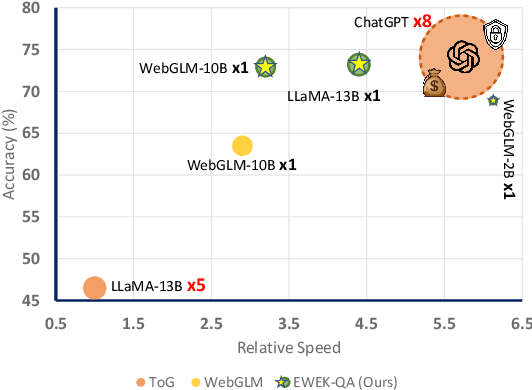
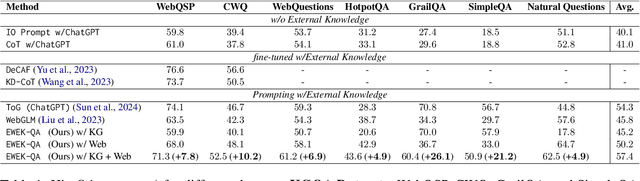
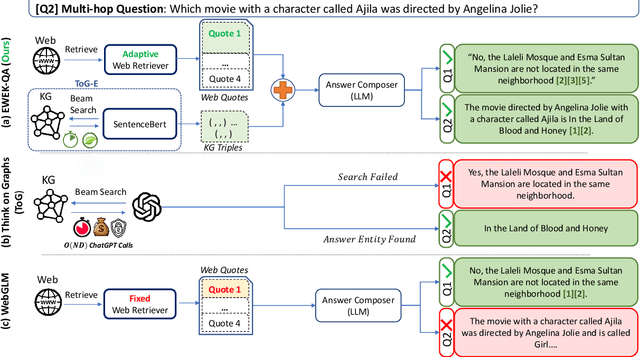
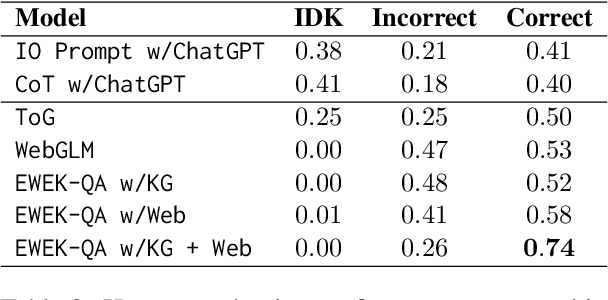
The emerging citation-based QA systems are gaining more attention especially in generative AI search applications. The importance of extracted knowledge provided to these systems is vital from both accuracy (completeness of information) and efficiency (extracting the information in a timely manner). In this regard, citation-based QA systems are suffering from two shortcomings. First, they usually rely only on web as a source of extracted knowledge and adding other external knowledge sources can hamper the efficiency of the system. Second, web-retrieved contents are usually obtained by some simple heuristics such as fixed length or breakpoints which might lead to splitting information into pieces. To mitigate these issues, we propose our enhanced web and efficient knowledge graph (KG) retrieval solution (EWEK-QA) to enrich the content of the extracted knowledge fed to the system. This has been done through designing an adaptive web retriever and incorporating KGs triples in an efficient manner. We demonstrate the effectiveness of EWEK-QA over the open-source state-of-the-art (SoTA) web-based and KG baseline models using a comprehensive set of quantitative and human evaluation experiments. Our model is able to: first, improve the web-retriever baseline in terms of extracting more relevant passages (>20\%), the coverage of answer span (>25\%) and self containment (>35\%); second, obtain and integrate KG triples into its pipeline very efficiently (by avoiding any LLM calls) to outperform the web-only and KG-only SoTA baselines significantly in 7 quantitative QA tasks and our human evaluation.
CHIQ: Contextual History Enhancement for Improving Query Rewriting in Conversational Search
Jun 07, 2024In this paper, we study how open-source large language models (LLMs) can be effectively deployed for improving query rewriting in conversational search, especially for ambiguous queries. We introduce CHIQ, a two-step method that leverages the capabilities of LLMs to resolve ambiguities in the conversation history before query rewriting. This approach contrasts with prior studies that predominantly use closed-source LLMs to directly generate search queries from conversation history. We demonstrate on five well-established benchmarks that CHIQ leads to state-of-the-art results across most settings, showing highly competitive performances with systems leveraging closed-source LLMs. Our study provides a first step towards leveraging open-source LLMs in conversational search, as a competitive alternative to the prevailing reliance on commercial LLMs. Data, models, and source code will be publicly available upon acceptance at https://github.com/fengranMark/CHIQ.
OTTAWA: Optimal TransporT Adaptive Word Aligner for Hallucination and Omission Translation Errors Detection
Jun 04, 2024Recently, there has been considerable attention on detecting hallucinations and omissions in Machine Translation (MT) systems. The two dominant approaches to tackle this task involve analyzing the MT system's internal states or relying on the output of external tools, such as sentence similarity or MT quality estimators. In this work, we introduce OTTAWA, a novel Optimal Transport (OT)-based word aligner specifically designed to enhance the detection of hallucinations and omissions in MT systems. Our approach explicitly models the missing alignments by introducing a "null" vector, for which we propose a novel one-side constrained OT setting to allow an adaptive null alignment. Our approach yields competitive results compared to state-of-the-art methods across 18 language pairs on the HalOmi benchmark. In addition, it shows promising features, such as the ability to distinguish between both error types and perform word-level detection without accessing the MT system's internal states.
CHARP: Conversation History AwaReness Probing for Knowledge-grounded Dialogue Systems
May 24, 2024



In this work, we dive deep into one of the popular knowledge-grounded dialogue benchmarks that focus on faithfulness, FaithDial. We show that a significant portion of the FaithDial data contains annotation artifacts, which may bias models towards completely ignoring the conversation history. We therefore introduce CHARP, a diagnostic test set, designed for an improved evaluation of hallucinations in conversational model. CHARP not only measures hallucination but also the compliance of the models to the conversation task. Our extensive analysis reveals that models primarily exhibit poor performance on CHARP due to their inability to effectively attend to and reason over the conversation history. Furthermore, the evaluation methods of FaithDial fail to capture these shortcomings, neglecting the conversational history. Our findings indicate that there is substantial room for contribution in both dataset creation and hallucination evaluation for knowledge-grounded dialogue, and that CHARP can serve as a tool for monitoring the progress in this particular research area. CHARP is publicly available at https://huggingface.co/datasets/huawei-noah/CHARP
On the importance of Data Scale in Pretraining Arabic Language Models
Jan 15, 2024



Pretraining monolingual language models have been proven to be vital for performance in Arabic Natural Language Processing (NLP) tasks. In this paper, we conduct a comprehensive study on the role of data in Arabic Pretrained Language Models (PLMs). More precisely, we reassess the performance of a suite of state-of-the-art Arabic PLMs by retraining them on massive-scale, high-quality Arabic corpora. We have significantly improved the performance of the leading Arabic encoder-only BERT-base and encoder-decoder T5-base models on the ALUE and ORCA leaderboards, thereby reporting state-of-the-art results in their respective model categories. In addition, our analysis strongly suggests that pretraining data by far is the primary contributor to performance, surpassing other factors. Our models and source code are publicly available at https://github.com/huawei-noah/Pretrained-Language-Model/tree/master/JABER-PyTorch.
AraMUS: Pushing the Limits of Data and Model Scale for Arabic Natural Language Processing
Jun 11, 2023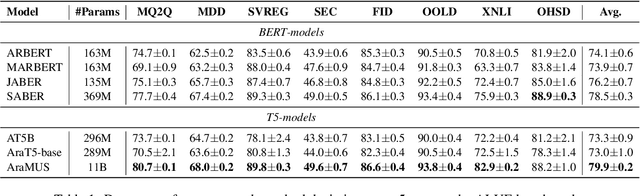



Developing monolingual large Pre-trained Language Models (PLMs) is shown to be very successful in handling different tasks in Natural Language Processing (NLP). In this work, we present AraMUS, the largest Arabic PLM with 11B parameters trained on 529GB of high-quality Arabic textual data. AraMUS achieves state-of-the-art performances on a diverse set of Arabic classification and generative tasks. Moreover, AraMUS shows impressive few-shot learning abilities compared with the best existing Arabic PLMs.
Revisiting Pre-trained Language Models and their Evaluation for Arabic Natural Language Understanding
May 21, 2022
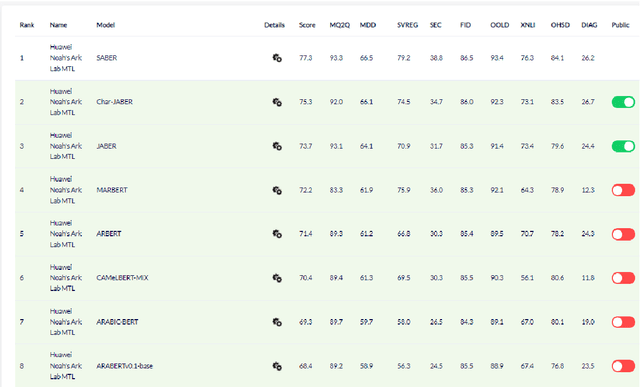

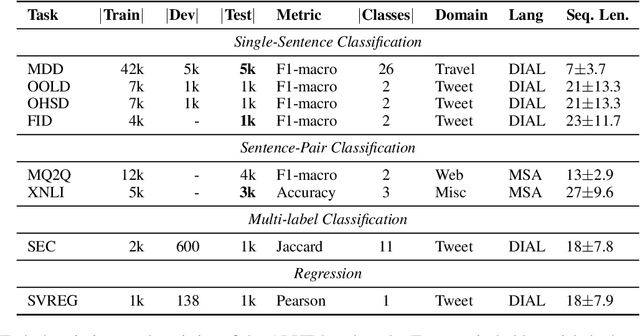
There is a growing body of work in recent years to develop pre-trained language models (PLMs) for the Arabic language. This work concerns addressing two major problems in existing Arabic PLMs which constraint progress of the Arabic NLU and NLG fields.First, existing Arabic PLMs are not well-explored and their pre-trainig can be improved significantly using a more methodical approach. Second, there is a lack of systematic and reproducible evaluation of these models in the literature. In this work, we revisit both the pre-training and evaluation of Arabic PLMs. In terms of pre-training, we explore improving Arabic LMs from three perspectives: quality of the pre-training data, size of the model, and incorporating character-level information. As a result, we release three new Arabic BERT-style models ( JABER, Char-JABER, and SABER), and two T5-style models (AT5S and AT5B). In terms of evaluation, we conduct a comprehensive empirical study to systematically evaluate the performance of existing state-of-the-art models on ALUE that is a leaderboard-powered benchmark for Arabic NLU tasks, and on a subset of the ARGEN benchmark for Arabic NLG tasks. We show that our models significantly outperform existing Arabic PLMs and achieve a new state-of-the-art performance on discriminative and generative Arabic NLU and NLG tasks. Our models and source code to reproduce of results will be made available shortly.
CILDA: Contrastive Data Augmentation using Intermediate Layer Knowledge Distillation
Apr 15, 2022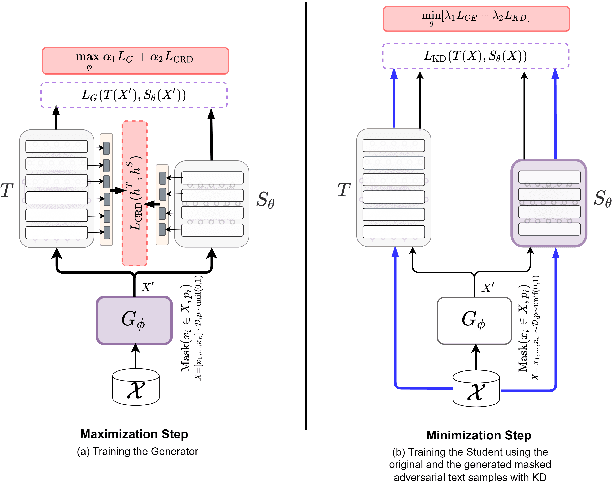
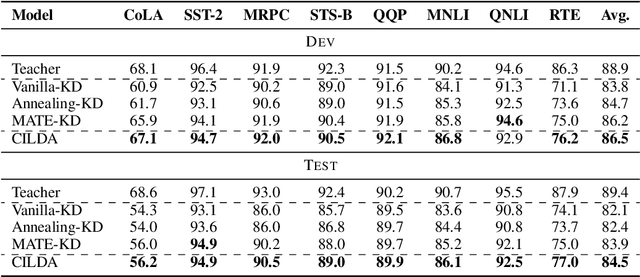
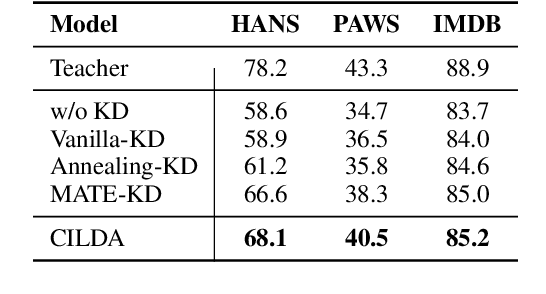
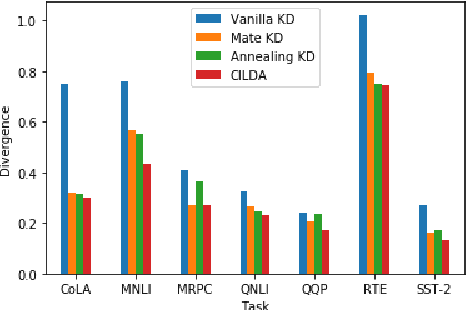
Knowledge distillation (KD) is an efficient framework for compressing large-scale pre-trained language models. Recent years have seen a surge of research aiming to improve KD by leveraging Contrastive Learning, Intermediate Layer Distillation, Data Augmentation, and Adversarial Training. In this work, we propose a learning based data augmentation technique tailored for knowledge distillation, called CILDA. To the best of our knowledge, this is the first time that intermediate layer representations of the main task are used in improving the quality of augmented samples. More precisely, we introduce an augmentation technique for KD based on intermediate layer matching using contrastive loss to improve masked adversarial data augmentation. CILDA outperforms existing state-of-the-art KD approaches on the GLUE benchmark, as well as in an out-of-domain evaluation.
JABER and SABER: Junior and Senior Arabic BERt
Jan 09, 2022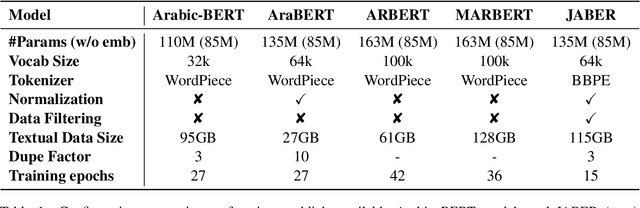
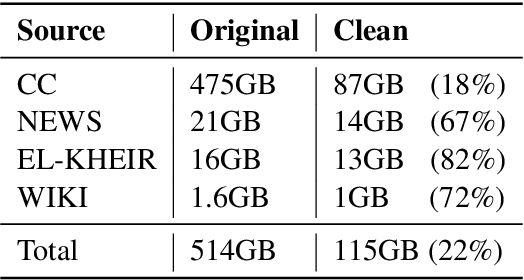
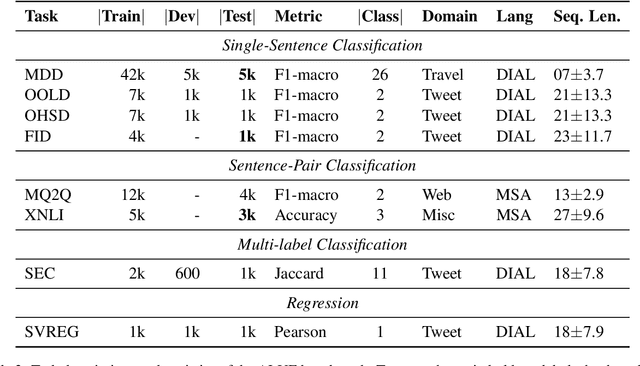
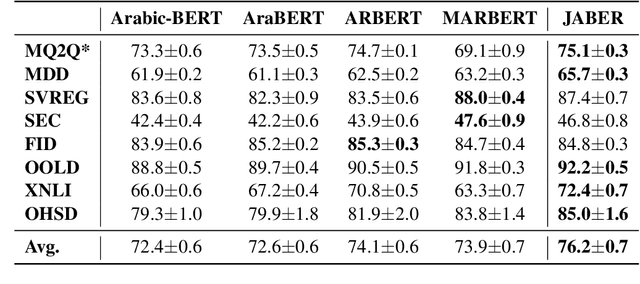
Language-specific pre-trained models have proven to be more accurate than multilingual ones in a monolingual evaluation setting, Arabic is no exception. However, we found that previously released Arabic BERT models were significantly under-trained. In this technical report, we present JABER and SABER, Junior and Senior Arabic BERt respectively, our pre-trained language model prototypes dedicated for Arabic. We conduct an empirical study to systematically evaluate the performance of models across a diverse set of existing Arabic NLU tasks. Experimental results show that JABER and SABER achieve state-of-the-art performances on ALUE, a new benchmark for Arabic Language Understanding Evaluation, as well as on a well-established NER benchmark.
NATURE: Natural Auxiliary Text Utterances for Realistic Spoken Language Evaluation
Nov 09, 2021
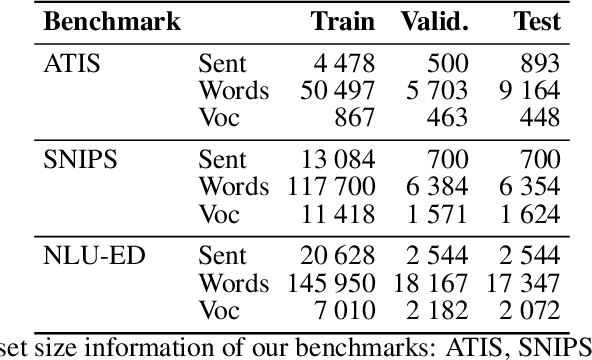
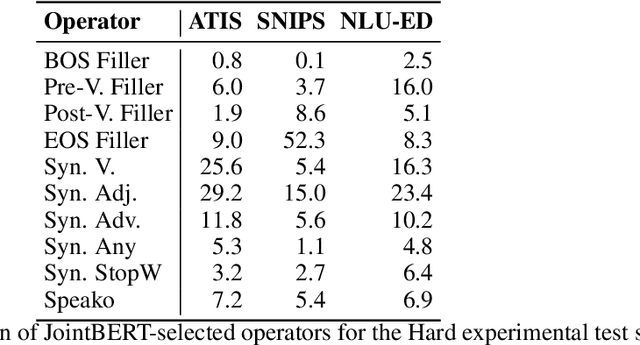
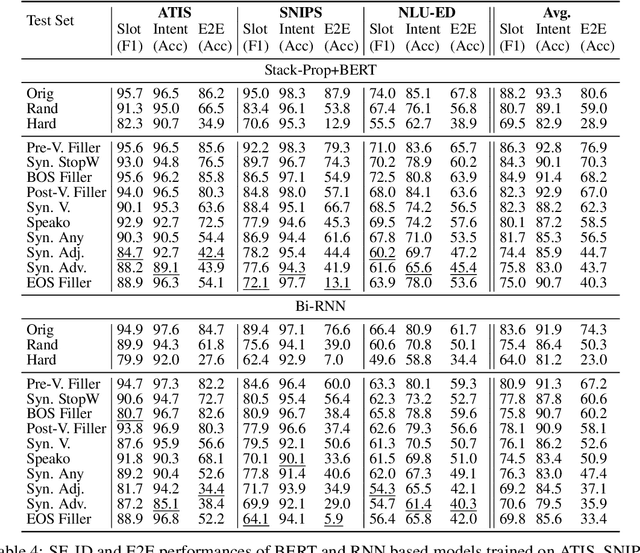
Slot-filling and intent detection are the backbone of conversational agents such as voice assistants, and are active areas of research. Even though state-of-the-art techniques on publicly available benchmarks show impressive performance, their ability to generalize to realistic scenarios is yet to be demonstrated. In this work, we present NATURE, a set of simple spoken-language oriented transformations, applied to the evaluation set of datasets, to introduce human spoken language variations while preserving the semantics of an utterance. We apply NATURE to common slot-filling and intent detection benchmarks and demonstrate that simple perturbations from the standard evaluation set by NATURE can deteriorate model performance significantly. Through our experiments we demonstrate that when NATURE operators are applied to evaluation set of popular benchmarks the model accuracy can drop by up to 40%.