 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning on a Budget: A Survey of Adaptive and Controllable Test-Time Compute in LLMs
Jul 02, 2025Large language models (LLMs) have rapidly progressed into general-purpose agents capable of solving a broad spectrum of tasks. However, current models remain inefficient at reasoning: they apply fixed inference-time compute regardless of task complexity, often overthinking simple problems while underthinking hard ones. This survey presents a comprehensive review of efficient test-time compute (TTC) strategies, which aim to improve the computational efficiency of LLM reasoning. We introduce a two-tiered taxonomy that distinguishes between L1-controllability, methods that operate under fixed compute budgets, and L2-adaptiveness, methods that dynamically scale inference based on input difficulty or model confidence. We benchmark leading proprietary LLMs across diverse datasets, highlighting critical trade-offs between reasoning performance and token usage. Compared to prior surveys on efficient reasoning, our review emphasizes the practical control, adaptability, and scalability of TTC methods. Finally, we discuss emerging trends such as hybrid thinking models and identify key challenges for future work towards making LLMs more computationally efficient, robust, and responsive to user constraints.
Mem2Ego: Empowering Vision-Language Models with Global-to-Ego Memory for Long-Horizon Embodied Navigation
Feb 20, 2025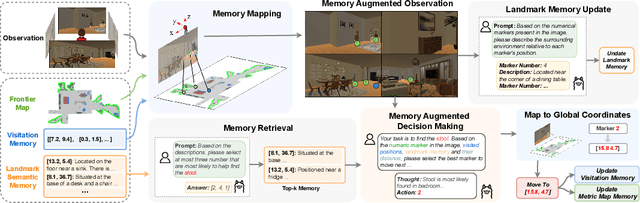
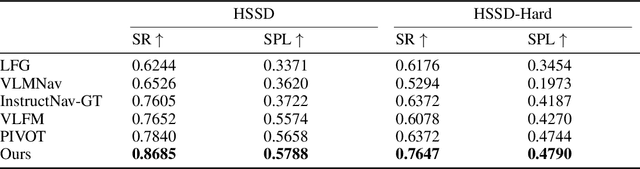
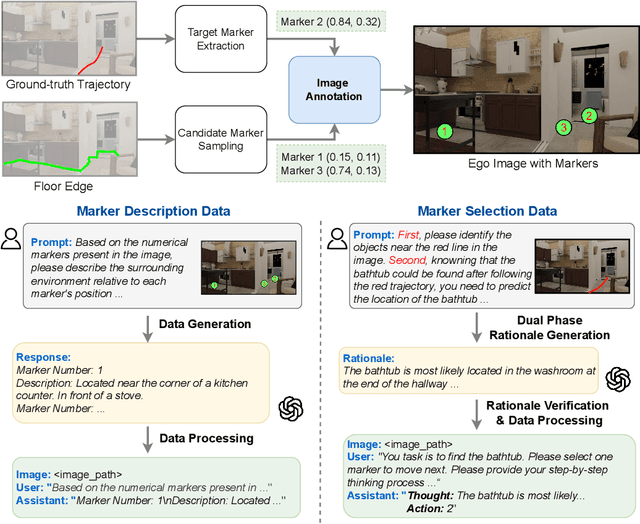

Recent advancements in Large Language Models (LLMs) and Vision-Language Models (VLMs) have made them powerful tools in embodied navigation, enabling agents to leverage commonsense and spatial reasoning for efficient exploration in unfamiliar environments. Existing LLM-based approaches convert global memory, such as semantic or topological maps, into language descriptions to guide navigation. While this improves efficiency and reduces redundant exploration, the loss of geometric information in language-based representations hinders spatial reasoning, especially in intricate environments. To address this, VLM-based approaches directly process ego-centric visual inputs to select optimal directions for exploration. However, relying solely on a first-person perspective makes navigation a partially observed decision-making problem, leading to suboptimal decisions in complex environments. In this paper, we present a novel vision-language model (VLM)-based navigation framework that addresses these challenges by adaptively retrieving task-relevant cues from a global memory module and integrating them with the agent's egocentric observations. By dynamically aligning global contextual information with local perception, our approach enhances spatial reasoning and decision-making in long-horizon tasks. Experimental results demonstrate that the proposed method surpasses previous state-of-the-art approaches in object navigation tasks, providing a more effective and scalable solution for embodied navigation.
Path-of-Thoughts: Extracting and Following Paths for Robust Relational Reasoning with Large Language Models
Dec 23, 2024



Large language models (LLMs) possess vast semantic knowledge but often struggle with complex reasoning tasks, particularly in relational reasoning problems such as kinship or spatial reasoning. In this paper, we present Path-of-Thoughts (PoT), a novel framework designed to tackle relation reasoning by decomposing the task into three key stages: graph extraction, path identification, and reasoning. Unlike previous approaches, PoT efficiently extracts a task-agnostic graph that identifies crucial entities, relations, and attributes within the problem context. Subsequently, PoT identifies relevant reasoning chains within the graph corresponding to the posed question, facilitating inference of potential answers. Experimental evaluations on four benchmark datasets, demanding long reasoning chains, demonstrate that PoT surpasses state-of-the-art baselines by a significant margin (maximum 21.3%) without necessitating fine-tuning or extensive LLM calls. Furthermore, as opposed to prior neuro-symbolic methods, PoT exhibits improved resilience against LLM errors by leveraging the compositional nature of graphs.
EWEK-QA: Enhanced Web and Efficient Knowledge Graph Retrieval for Citation-based Question Answering Systems
Jun 14, 2024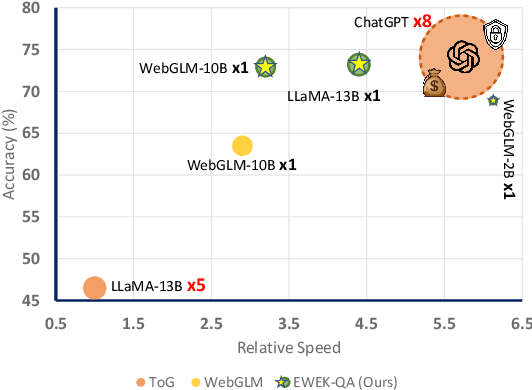
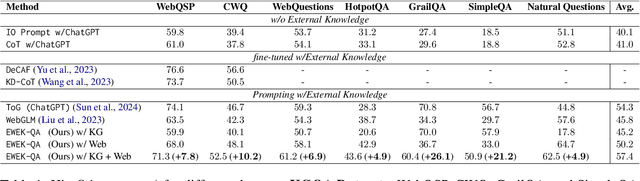
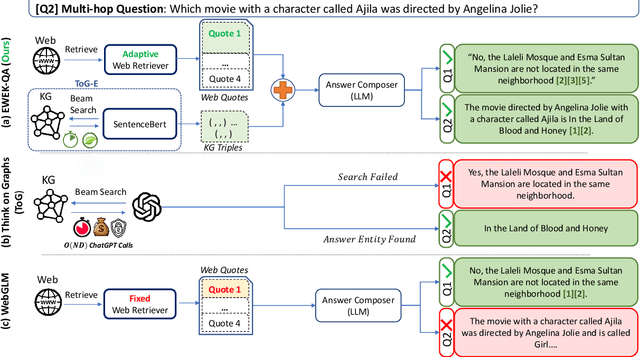
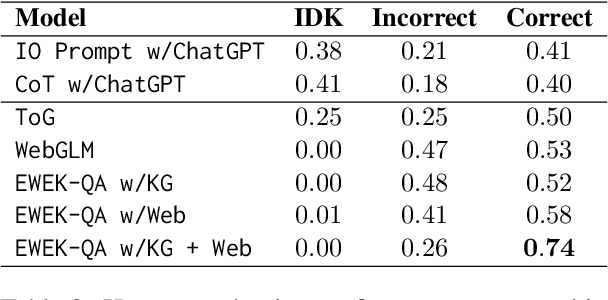
The emerging citation-based QA systems are gaining more attention especially in generative AI search applications. The importance of extracted knowledge provided to these systems is vital from both accuracy (completeness of information) and efficiency (extracting the information in a timely manner). In this regard, citation-based QA systems are suffering from two shortcomings. First, they usually rely only on web as a source of extracted knowledge and adding other external knowledge sources can hamper the efficiency of the system. Second, web-retrieved contents are usually obtained by some simple heuristics such as fixed length or breakpoints which might lead to splitting information into pieces. To mitigate these issues, we propose our enhanced web and efficient knowledge graph (KG) retrieval solution (EWEK-QA) to enrich the content of the extracted knowledge fed to the system. This has been done through designing an adaptive web retriever and incorporating KGs triples in an efficient manner. We demonstrate the effectiveness of EWEK-QA over the open-source state-of-the-art (SoTA) web-based and KG baseline models using a comprehensive set of quantitative and human evaluation experiments. Our model is able to: first, improve the web-retriever baseline in terms of extracting more relevant passages (>20\%), the coverage of answer span (>25\%) and self containment (>35\%); second, obtain and integrate KG triples into its pipeline very efficiently (by avoiding any LLM calls) to outperform the web-only and KG-only SoTA baselines significantly in 7 quantitative QA tasks and our human evaluation.
DyG2Vec: Representation Learning for Dynamic Graphs with Self-Supervision
Oct 30, 2022



The challenge in learning from dynamic graphs for predictive tasks lies in extracting fine-grained temporal motifs from an ever-evolving graph. Moreover, task labels are often scarce, costly to obtain, and highly imbalanced for large dynamic graphs. Recent advances in self-supervised learning on graphs demonstrate great potential, but focus on static graphs. State-of-the-art (SoTA) models for dynamic graphs are not only incompatible with the self-supervised learning (SSL) paradigm but also fail to forecast interactions beyond the very near future. To address these limitations, we present DyG2Vec, an SSL-compatible, efficient model for representation learning on dynamic graphs. DyG2Vec uses a window-based mechanism to generate task-agnostic node embeddings that can be used to forecast future interactions. DyG2Vec significantly outperforms SoTA baselines on benchmark datasets for downstream tasks while only requiring a fraction of the training/inference time. We adapt two SSL evaluation mechanisms to make them applicable to dynamic graphs and thus show that SSL pre-training helps learn more robust temporal node representations, especially for scenarios with few labels.
Deep Policies for Online Bipartite Matching: A Reinforcement Learning Approach
Sep 21, 2021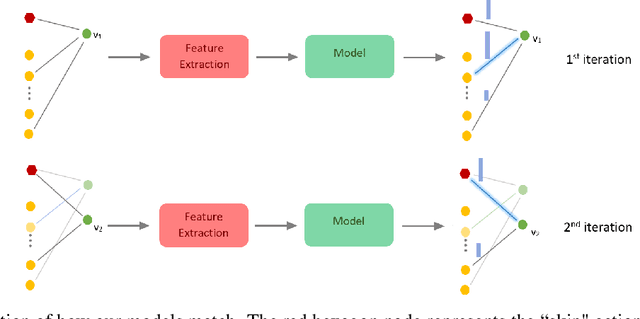
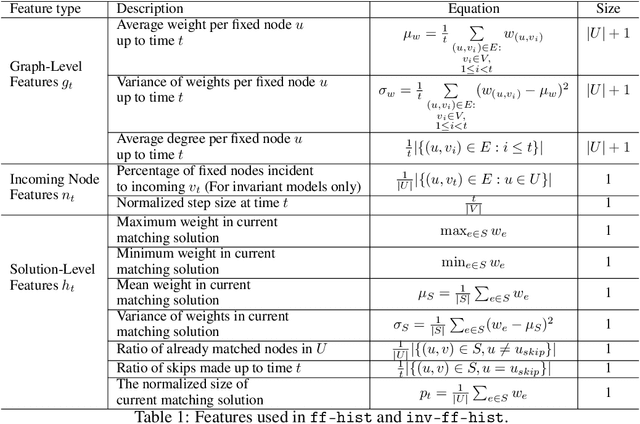
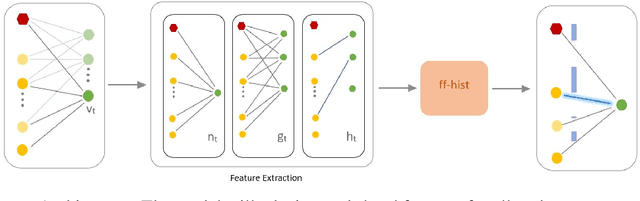
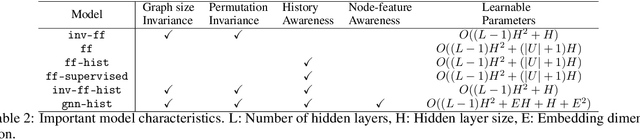
From assigning computing tasks to servers and advertisements to users, sequential online matching problems arise in a wide variety of domains. The challenge in online matching lies in making irrevocable assignments while there is uncertainty about future inputs. In the theoretical computer science literature, most policies are myopic or greedy in nature. In real-world applications where the matching process is repeated on a regular basis, the underlying data distribution can be leveraged for better decision-making. We present an end-to-end Reinforcement Learning framework for deriving better matching policies based on trial-and-error on historical data. We devise a set of neural network architectures, design feature representations, and empirically evaluate them across two online matching problems: Edge-Weighted Online Bipartite Matching and Online Submodular Bipartite Matching. We show that most of the learning approaches perform significantly better than classical greedy algorithms on four synthetic and real-world datasets. Our code is publicly available at https://github.com/lyeskhalil/CORL.git.
A Critical Review of Information Bottleneck Theory and its Applications to Deep Learning
May 11, 2021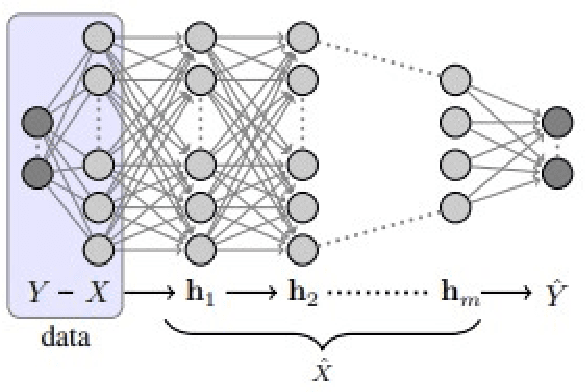


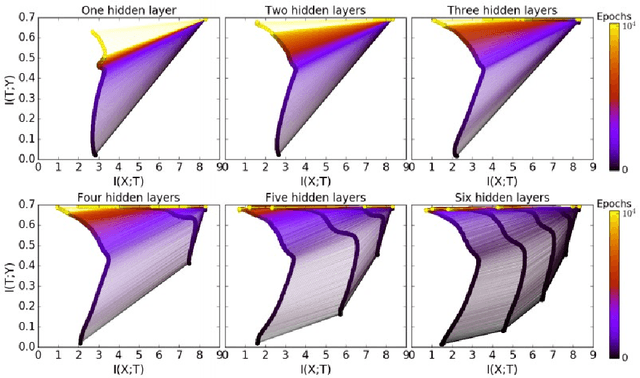
In the past decade, deep neural networks have seen unparalleled improvements that continue to impact every aspect of today's society. With the development of high performance GPUs and the availability of vast amounts of data, learning capabilities of ML systems have skyrocketed, going from classifying digits in a picture to beating world-champions in games with super-human performance. However, even as ML models continue to achieve new frontiers, their practical success has been hindered by the lack of a deep theoretical understanding of their inner workings. Fortunately, a known information-theoretic method called the information bottleneck theory has emerged as a promising approach to better understand the learning dynamics of neural networks. In principle, IB theory models learning as a trade-off between the compression of the data and the retainment of information. The goal of this survey is to provide a comprehensive review of IB theory covering it's information theoretic roots and the recently proposed applications to understand deep learning models.