 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE-CARE: An Efficient LLM-based Commonsense-Augmented Framework for E-Commerce
Nov 06, 2025Finding relevant products given a user query plays a pivotal role in an e-commerce platform, as it can spark shopping behaviors and result in revenue gains. The challenge lies in accurately predicting the correlation between queries and products. Recently, mining the cross-features between queries and products based on the commonsense reasoning capacity of Large Language Models (LLMs) has shown promising performance. However, such methods suffer from high costs due to intensive real-time LLM inference during serving, as well as human annotations and potential Supervised Fine Tuning (SFT). To boost efficiency while leveraging the commonsense reasoning capacity of LLMs for various e-commerce tasks, we propose the Efficient Commonsense-Augmented Recommendation Enhancer (E-CARE). During inference, models augmented with E-CARE can access commonsense reasoning with only a single LLM forward pass per query by utilizing a commonsense reasoning factor graph that encodes most of the reasoning schema from powerful LLMs. The experiments on 2 downstream tasks show an improvement of up to 12.1% on precision@5.
Mem2Ego: Empowering Vision-Language Models with Global-to-Ego Memory for Long-Horizon Embodied Navigation
Feb 20, 2025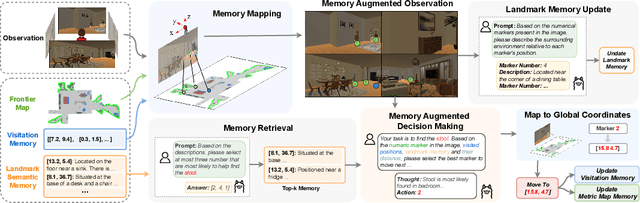
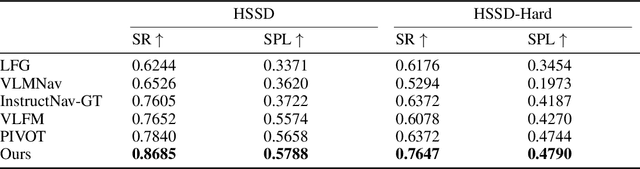
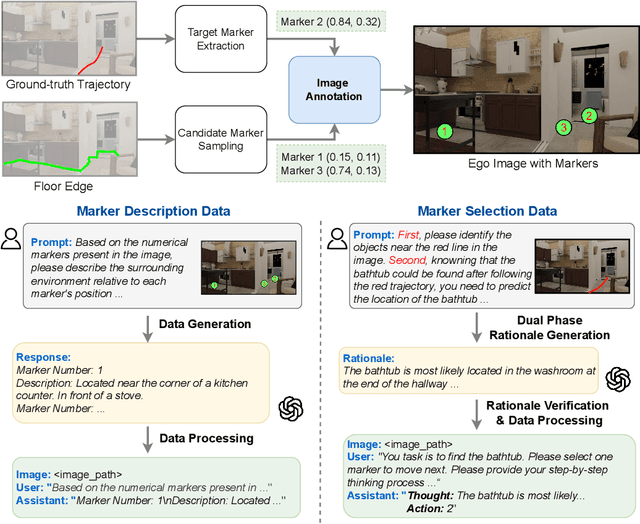

Recent advancements in Large Language Models (LLMs) and Vision-Language Models (VLMs) have made them powerful tools in embodied navigation, enabling agents to leverage commonsense and spatial reasoning for efficient exploration in unfamiliar environments. Existing LLM-based approaches convert global memory, such as semantic or topological maps, into language descriptions to guide navigation. While this improves efficiency and reduces redundant exploration, the loss of geometric information in language-based representations hinders spatial reasoning, especially in intricate environments. To address this, VLM-based approaches directly process ego-centric visual inputs to select optimal directions for exploration. However, relying solely on a first-person perspective makes navigation a partially observed decision-making problem, leading to suboptimal decisions in complex environments. In this paper, we present a novel vision-language model (VLM)-based navigation framework that addresses these challenges by adaptively retrieving task-relevant cues from a global memory module and integrating them with the agent's egocentric observations. By dynamically aligning global contextual information with local perception, our approach enhances spatial reasoning and decision-making in long-horizon tasks. Experimental results demonstrate that the proposed method surpasses previous state-of-the-art approaches in object navigation tasks, providing a more effective and scalable solution for embodied navigation.
Path-of-Thoughts: Extracting and Following Paths for Robust Relational Reasoning with Large Language Models
Dec 23, 2024



Large language models (LLMs) possess vast semantic knowledge but often struggle with complex reasoning tasks, particularly in relational reasoning problems such as kinship or spatial reasoning. In this paper, we present Path-of-Thoughts (PoT), a novel framework designed to tackle relation reasoning by decomposing the task into three key stages: graph extraction, path identification, and reasoning. Unlike previous approaches, PoT efficiently extracts a task-agnostic graph that identifies crucial entities, relations, and attributes within the problem context. Subsequently, PoT identifies relevant reasoning chains within the graph corresponding to the posed question, facilitating inference of potential answers. Experimental evaluations on four benchmark datasets, demanding long reasoning chains, demonstrate that PoT surpasses state-of-the-art baselines by a significant margin (maximum 21.3%) without necessitating fine-tuning or extensive LLM calls. Furthermore, as opposed to prior neuro-symbolic methods, PoT exhibits improved resilience against LLM errors by leveraging the compositional nature of graphs.