 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning on a Budget: A Survey of Adaptive and Controllable Test-Time Compute in LLMs
Jul 02, 2025Large language models (LLMs) have rapidly progressed into general-purpose agents capable of solving a broad spectrum of tasks. However, current models remain inefficient at reasoning: they apply fixed inference-time compute regardless of task complexity, often overthinking simple problems while underthinking hard ones. This survey presents a comprehensive review of efficient test-time compute (TTC) strategies, which aim to improve the computational efficiency of LLM reasoning. We introduce a two-tiered taxonomy that distinguishes between L1-controllability, methods that operate under fixed compute budgets, and L2-adaptiveness, methods that dynamically scale inference based on input difficulty or model confidence. We benchmark leading proprietary LLMs across diverse datasets, highlighting critical trade-offs between reasoning performance and token usage. Compared to prior surveys on efficient reasoning, our review emphasizes the practical control, adaptability, and scalability of TTC methods. Finally, we discuss emerging trends such as hybrid thinking models and identify key challenges for future work towards making LLMs more computationally efficient, robust, and responsive to user constraints.
Mem2Ego: Empowering Vision-Language Models with Global-to-Ego Memory for Long-Horizon Embodied Navigation
Feb 20, 2025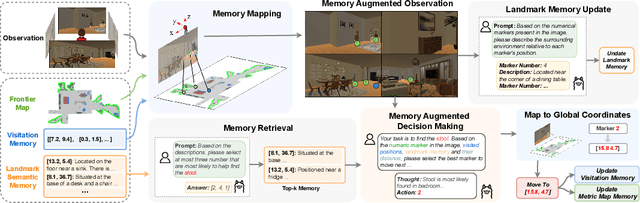
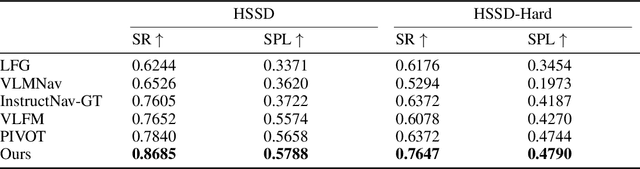
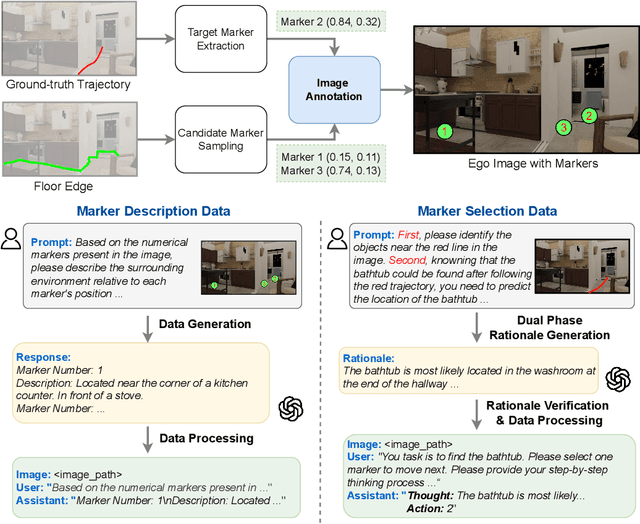

Recent advancements in Large Language Models (LLMs) and Vision-Language Models (VLMs) have made them powerful tools in embodied navigation, enabling agents to leverage commonsense and spatial reasoning for efficient exploration in unfamiliar environments. Existing LLM-based approaches convert global memory, such as semantic or topological maps, into language descriptions to guide navigation. While this improves efficiency and reduces redundant exploration, the loss of geometric information in language-based representations hinders spatial reasoning, especially in intricate environments. To address this, VLM-based approaches directly process ego-centric visual inputs to select optimal directions for exploration. However, relying solely on a first-person perspective makes navigation a partially observed decision-making problem, leading to suboptimal decisions in complex environments. In this paper, we present a novel vision-language model (VLM)-based navigation framework that addresses these challenges by adaptively retrieving task-relevant cues from a global memory module and integrating them with the agent's egocentric observations. By dynamically aligning global contextual information with local perception, our approach enhances spatial reasoning and decision-making in long-horizon tasks. Experimental results demonstrate that the proposed method surpasses previous state-of-the-art approaches in object navigation tasks, providing a more effective and scalable solution for embodied navigation.
Logic Synthesis Optimization with Predictive Self-Supervision via Causal Transformers
Sep 16, 2024



Contemporary hardware design benefits from the abstraction provided by high-level logic gates, streamlining the implementation of logic circuits. Logic Synthesis Optimization (LSO) operates at one level of abstraction within the Electronic Design Automation (EDA) workflow, targeting improvements in logic circuits with respect to performance metrics such as size and speed in the final layout. Recent trends in the field show a growing interest in leveraging Machine Learning (ML) for EDA, notably through ML-guided logic synthesis utilizing policy-based Reinforcement Learning (RL) methods.Despite these advancements, existing models face challenges such as overfitting and limited generalization, attributed to constrained public circuits and the expressiveness limitations of graph encoders. To address these hurdles, and tackle data scarcity issues, we introduce LSOformer, a novel approach harnessing Autoregressive transformer models and predictive SSL to predict the trajectory of Quality of Results (QoR). LSOformer integrates cross-attention modules to merge insights from circuit graphs and optimization sequences, thereby enhancing prediction accuracy for QoR metrics. Experimental studies validate the effectiveness of LSOformer, showcasing its superior performance over baseline architectures in QoR prediction tasks, where it achieves improvements of 5.74%, 4.35%, and 17.06% on the EPFL, OABCD, and proprietary circuits datasets, respectively, in inductive setup.
MTLSO: A Multi-Task Learning Approach for Logic Synthesis Optimization
Sep 09, 2024



Electronic Design Automation (EDA) is essential for IC design and has recently benefited from AI-based techniques to improve efficiency. Logic synthesis, a key EDA stage, transforms high-level hardware descriptions into optimized netlists. Recent research has employed machine learning to predict Quality of Results (QoR) for pairs of And-Inverter Graphs (AIGs) and synthesis recipes. However, the severe scarcity of data due to a very limited number of available AIGs results in overfitting, significantly hindering performance. Additionally, the complexity and large number of nodes in AIGs make plain GNNs less effective for learning expressive graph-level representations. To tackle these challenges, we propose MTLSO - a Multi-Task Learning approach for Logic Synthesis Optimization. On one hand, it maximizes the use of limited data by training the model across different tasks. This includes introducing an auxiliary task of binary multi-label graph classification alongside the primary regression task, allowing the model to benefit from diverse supervision sources. On the other hand, we employ a hierarchical graph representation learning strategy to improve the model's capacity for learning expressive graph-level representations of large AIGs, surpassing traditional plain GNNs. Extensive experiments across multiple datasets and against state-of-the-art baselines demonstrate the superiority of our method, achieving an average performance gain of 8.22\% for delay and 5.95\% for area.
Scalable Graph Self-Supervised Learning
Feb 14, 2024



In regularization Self-Supervised Learning (SSL) methods for graphs, computational complexity increases with the number of nodes in graphs and embedding dimensions. To mitigate the scalability of non-contrastive graph SSL, we propose a novel approach to reduce the cost of computing the covariance matrix for the pre-training loss function with volume-maximization terms. Our work focuses on reducing the cost associated with the loss computation via graph node or dimension sampling. We provide theoretical insight into why dimension sampling would result in accurate loss computations and support it with mathematical derivation of the novel approach. We develop our experimental setup on the node-level graph prediction tasks, where SSL pre-training has shown to be difficult due to the large size of real world graphs. Our experiments demonstrate that the cost associated with the loss computation can be reduced via node or dimension sampling without lowering the downstream performance. Our results demonstrate that sampling mostly results in improved downstream performance. Ablation studies and experimental analysis are provided to untangle the role of the different factors in the experimental setup.
Todyformer: Towards Holistic Dynamic Graph Transformers with Structure-Aware Tokenization
Feb 02, 2024



Temporal Graph Neural Networks have garnered substantial attention for their capacity to model evolving structural and temporal patterns while exhibiting impressive performance. However, it is known that these architectures are encumbered by issues that constrain their performance, such as over-squashing and over-smoothing. Meanwhile, Transformers have demonstrated exceptional computational capacity to effectively address challenges related to long-range dependencies. Consequently, we introduce Todyformer-a novel Transformer-based neural network tailored for dynamic graphs. It unifies the local encoding capacity of Message-Passing Neural Networks (MPNNs) with the global encoding of Transformers through i) a novel patchifying paradigm for dynamic graphs to improve over-squashing, ii) a structure-aware parametric tokenization strategy leveraging MPNNs, iii) a Transformer with temporal positional-encoding to capture long-range dependencies, and iv) an encoding architecture that alternates between local and global contextualization, mitigating over-smoothing in MPNNs. Experimental evaluations on public benchmark datasets demonstrate that Todyformer consistently outperforms the state-of-the-art methods for downstream tasks. Furthermore, we illustrate the underlying aspects of the proposed model in effectively capturing extensive temporal dependencies in dynamic graphs.
DF-SSmVEP: Dual Frequency Aggregated Steady-State Motion Visual Evoked Potential Design with Bifold Canonical Correlation Analysis
Jan 02, 2022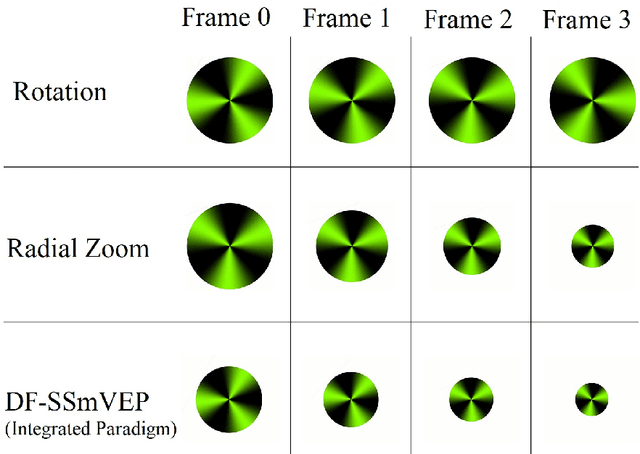
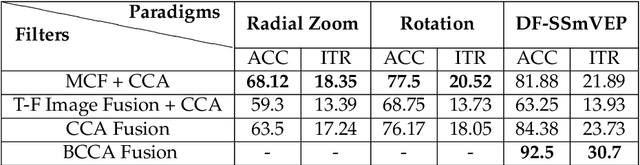
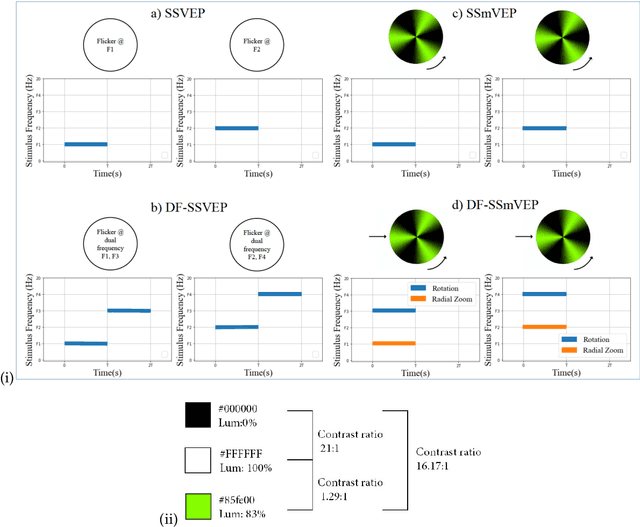
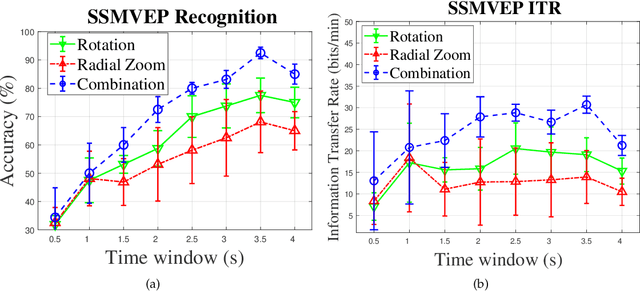
Recent advancements in Electroencephalography (EEG) sensor technologies and signal processing algorithms have paved the way for further evolution of Brain Computer Interfaces (BCI). When it comes to Signal Processing (SP) for BCI, there has been a surge of interest on Steady-State motion-Visual Evoked Potentials (SSmVEP), where motion stimulation is utilized to address key issues associated with conventional light-flashing/flickering. Such benefits, however, come with the price of having less accuracy and less Information Transfer Rate (ITR). In this regard, the paper focuses on the design of a novel SSmVEP paradigm without using resources such as trial time, phase, and/or number of targets to enhance the ITR. The proposed design is based on the intuitively pleasing idea of integrating more than one motion within a single SSmVEP target stimuli, simultaneously. To elicit SSmVEP, we designed a novel and innovative dual frequency aggregated modulation paradigm, referred to as the Dual Frequency Aggregated steady-state motion Visual Evoked Potential (DF-SSmVEP), by concurrently integrating "Radial Zoom" and "Rotation" motions in a single target without increasing the trial length. Compared to conventional SSmVEPs, the proposed DF-SSmVEP framework consists of two motion modes integrated and shown simultaneously each modulated by a specific target frequency. The paper also develops a specific unsupervised classification model, referred to as the Bifold Canonical Correlation Analysis (BCCA), based on two motion frequencies per target. The proposed DF-SSmVEP is evaluated based on a real EEG dataset and the results corroborate its superiority. The proposed DF-SSmVEP outperforms its counterparts and achieved an average ITR of 30.7 +/- 1.97 and an average accuracy of 92.5 +/- 2.04.