 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrequency-Space Prediction Filtering for Phase Aberration Correction in Plane-Wave Ultrasound
Aug 22, 2023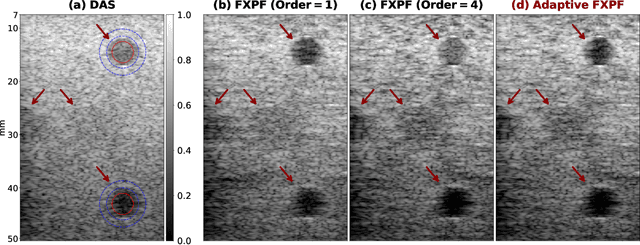
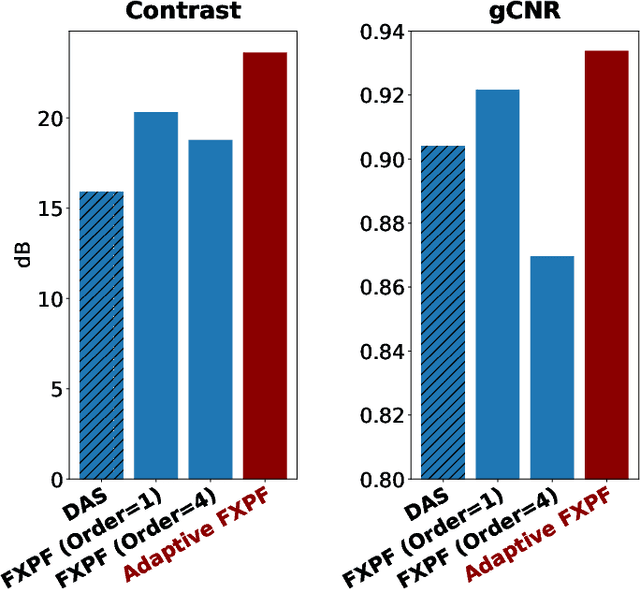
Ultrasound imaging often suffers from image degradation stemming from phase aberration, which represents a significant contributing factor to the overall image degradation in ultrasound imaging. Frequency-space prediction filtering or FXPF is a technique that has been applied within focused ultrasound imaging to alleviate the phase aberration effect. It presupposes the existence of an autoregressive (AR) model across the signals received at the transducer elements and removes any components that do not conform to the established model. In this study, we illustrate the challenge of applying this technique to plane-wave imaging, where, at shallower depths, signals from more distant elements lose relevance, and a fewer number of elements contribute to image reconstruction. While the number of contributing signals varies, adopting a fixed-order AR model across all depths, results in suboptimal performance. To address this challenge, we propose an AR model with an adaptive order and quantify its effectiveness using contrast and generalized contrast-to-noise ratio metrics.
Phase Aberration Correction: A Deep Learning-Based Aberration to Aberration Approach
Aug 22, 2023



One of the primary sources of suboptimal image quality in ultrasound imaging is phase aberration. It is caused by spatial changes in sound speed over a heterogeneous medium, which disturbs the transmitted waves and prevents coherent summation of echo signals. Obtaining non-aberrated ground truths in real-world scenarios can be extremely challenging, if not impossible. This challenge hinders training of deep learning-based techniques' performance due to the presence of domain shift between simulated and experimental data. Here, for the first time, we propose a deep learning-based method that does not require ground truth to correct the phase aberration problem, and as such, can be directly trained on real data. We train a network wherein both the input and target output are randomly aberrated radio frequency (RF) data. Moreover, we demonstrate that a conventional loss function such as mean square error is inadequate for training such a network to achieve optimal performance. Instead, we propose an adaptive mixed loss function that employs both B-mode and RF data, resulting in more efficient convergence and enhanced performance. Finally, we publicly release our dataset, including 161,701 single plane-wave images (RF data). This dataset serves to mitigate the data scarcity problem in the development of deep learning-based techniques for phase aberration correction.
Robust RF Data Normalization for Deep Learning
Aug 22, 2023



Radio frequency (RF) data contain richer information compared to other data types, such as envelope or B-mode, and employing RF data for training deep neural networks has attracted growing interest in ultrasound image processing. However, RF data is highly fluctuating and additionally has a high dynamic range. Most previous studies in the literature have relied on conventional data normalization, which has been adopted within the computer vision community. We demonstrate the inadequacy of those techniques for normalizing RF data and propose that individual standardization of each image substantially enhances the performance of deep neural networks by utilizing the data more efficiently. We compare conventional and proposed normalizations in a phase aberration correction task and illustrate how the former enhances the generality of trained models.
Phase Aberration Correction without Reference Data: An Adaptive Mixed Loss Deep Learning Approach
Mar 10, 2023Phase aberration is one of the primary sources of image quality degradation in ultrasound, which is induced by spatial variations in sound speed across the heterogeneous medium. This effect disrupts transmitted waves and prevents coherent summation of echo signals, resulting in suboptimal image quality. In real experiments, obtaining non-aberrated ground truths can be extremely challenging, if not infeasible. It hinders the performance of deep learning-based phase aberration correction techniques due to sole reliance on simulated data and the presence of domain shift between simulated and experimental data. Here, for the first time, we propose a deep learning-based method that does not require reference data to compensate for the phase aberration effect. We train a network wherein both input and target output are randomly aberrated radio frequency (RF) data. Moreover, we demonstrate that a conventional loss function such as mean square error is inadequate for training the network to achieve optimal performance. Instead, we propose an adaptive mixed loss function that employs both B-mode and RF data, resulting in more efficient convergence and enhanced performance. Source code is available at \url{http://code.sonography.ai}.
DF-SSmVEP: Dual Frequency Aggregated Steady-State Motion Visual Evoked Potential Design with Bifold Canonical Correlation Analysis
Jan 02, 2022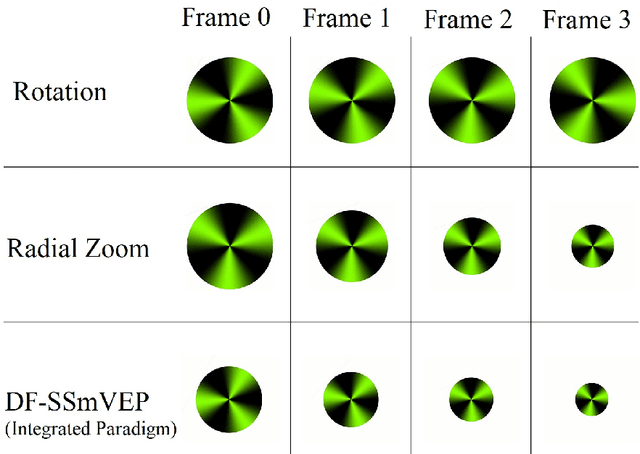
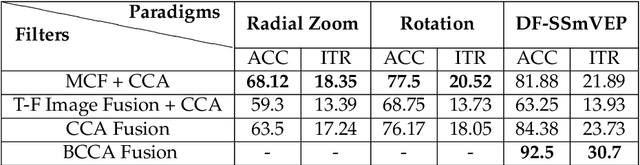
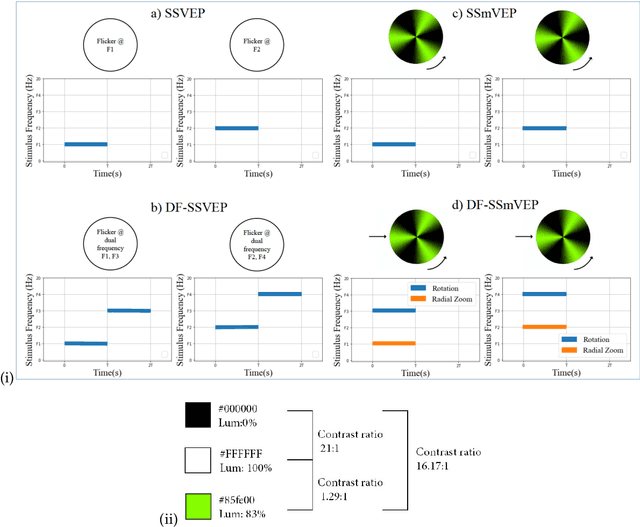
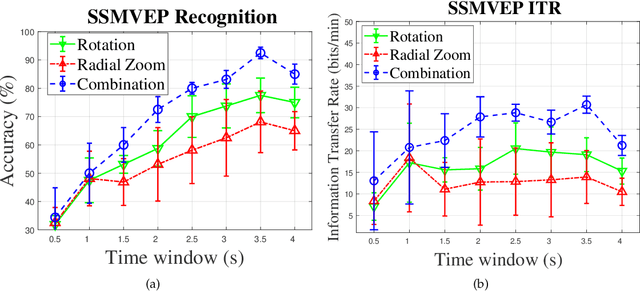
Recent advancements in Electroencephalography (EEG) sensor technologies and signal processing algorithms have paved the way for further evolution of Brain Computer Interfaces (BCI). When it comes to Signal Processing (SP) for BCI, there has been a surge of interest on Steady-State motion-Visual Evoked Potentials (SSmVEP), where motion stimulation is utilized to address key issues associated with conventional light-flashing/flickering. Such benefits, however, come with the price of having less accuracy and less Information Transfer Rate (ITR). In this regard, the paper focuses on the design of a novel SSmVEP paradigm without using resources such as trial time, phase, and/or number of targets to enhance the ITR. The proposed design is based on the intuitively pleasing idea of integrating more than one motion within a single SSmVEP target stimuli, simultaneously. To elicit SSmVEP, we designed a novel and innovative dual frequency aggregated modulation paradigm, referred to as the Dual Frequency Aggregated steady-state motion Visual Evoked Potential (DF-SSmVEP), by concurrently integrating "Radial Zoom" and "Rotation" motions in a single target without increasing the trial length. Compared to conventional SSmVEPs, the proposed DF-SSmVEP framework consists of two motion modes integrated and shown simultaneously each modulated by a specific target frequency. The paper also develops a specific unsupervised classification model, referred to as the Bifold Canonical Correlation Analysis (BCCA), based on two motion frequencies per target. The proposed DF-SSmVEP is evaluated based on a real EEG dataset and the results corroborate its superiority. The proposed DF-SSmVEP outperforms its counterparts and achieved an average ITR of 30.7 +/- 1.97 and an average accuracy of 92.5 +/- 2.04.
Ultrasound Domain Adaptation Using Frequency Domain Analysis
Sep 21, 2021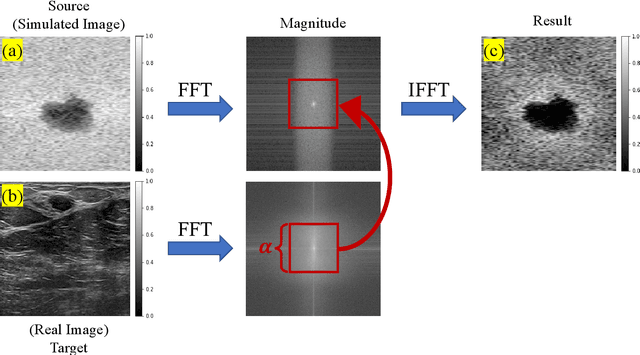
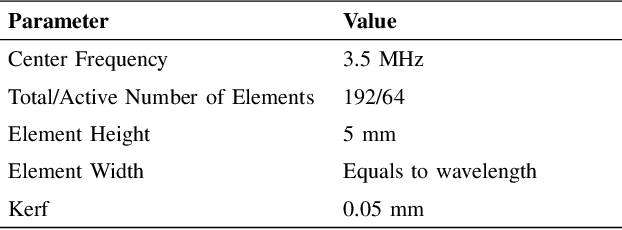
A common issue in exploiting simulated ultrasound data for training neural networks is the domain shift problem, where the trained models on synthetic data are not generalizable to clinical data. Recently, Fourier Domain Adaptation (FDA) has been proposed in the field of computer vision to tackle the domain shift problem by replacing the magnitude of the low-frequency spectrum of a synthetic sample (source) with a real sample (target). This method is attractive in ultrasound imaging given that two important differences between synthetic and real ultrasound data are caused by unknown values of attenuation and speed of sound (SOS) in real tissues. Attenuation leads to slow variations in the amplitude of the B-mode image, and SOS mismatch creates aberration and subsequent blurring. As such, both domain shifts cause differences in the low-frequency components of the envelope data, which are replaced in the proposed method. We demonstrate that applying the FDA method to the synthetic data, simulated by Field II, obtains an 3.5\% higher Dice similarity coefficient for a breast lesion segmentation task.
An Ultra-Fast Method for Simulation of Realistic Ultrasound Images
Sep 21, 2021

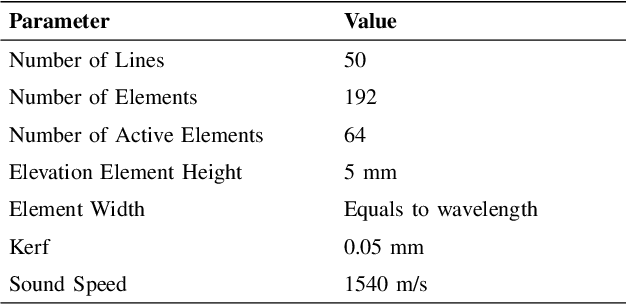
Convolutional neural networks (CNNs) have attracted a rapidly growing interest in a variety of different processing tasks in the medical ultrasound community. However, the performance of CNNs is highly reliant on both the amount and fidelity of the training data. Therefore, scarce data is almost always a concern, particularly in the medical field, where clinical data is not easily accessible. The utilization of synthetic data is a popular approach to address this challenge. However, but simulating a large number of images using packages such as Field II is time-consuming, and the distribution of simulated images is far from that of the real images. Herein, we introduce a novel ultra-fast ultrasound image simulation method based on the Fourier transform and evaluate its performance in a lesion segmentation task. We demonstrate that data augmentation using the images generated by the proposed method substantially outperforms Field II in terms of Dice similarity coefficient, while the simulation is almost 36000 times faster (both on CPU).
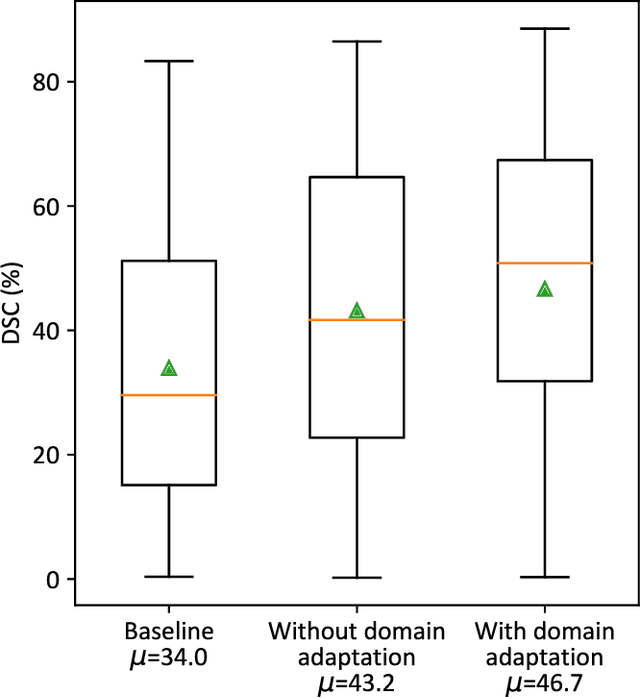
Investigating Shift-Variance of Convolutional Neural Networks in Ultrasound Image Segmentation
Jul 22, 2021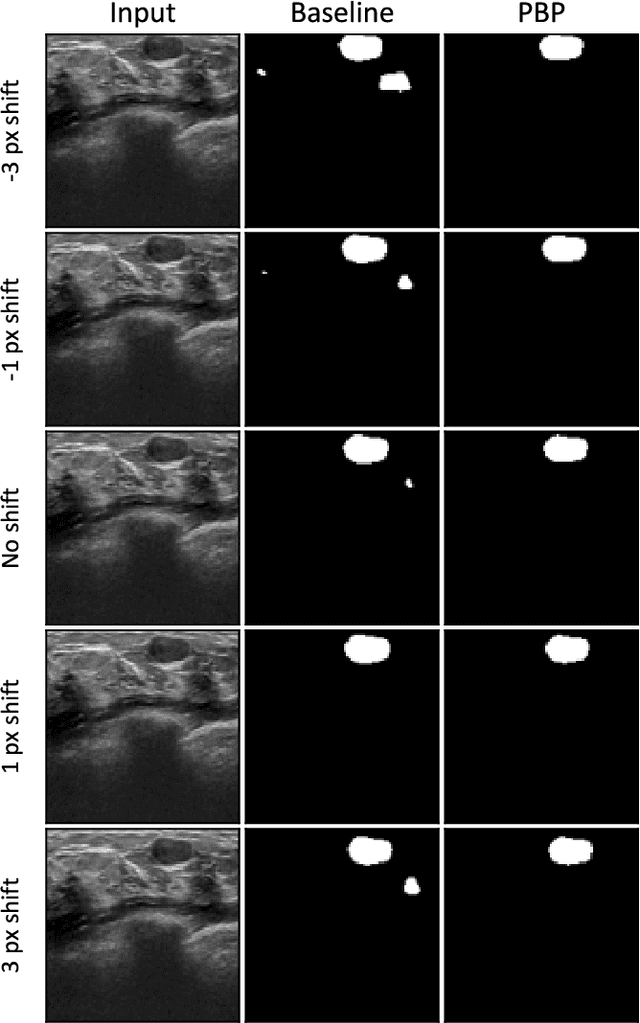
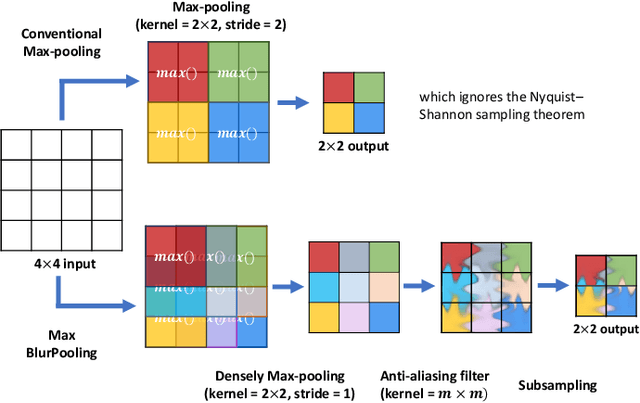
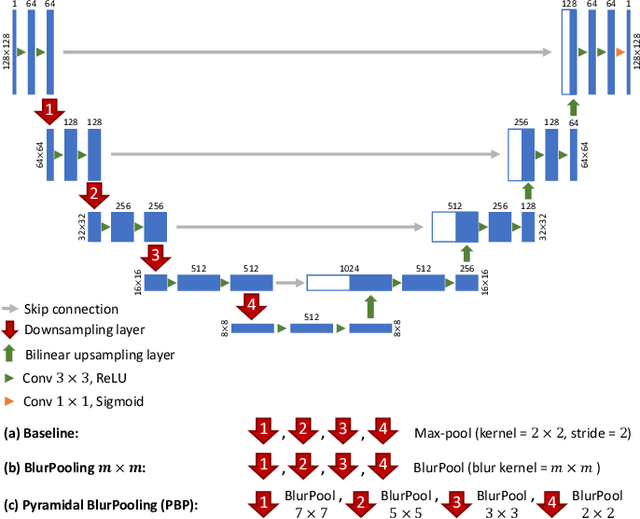
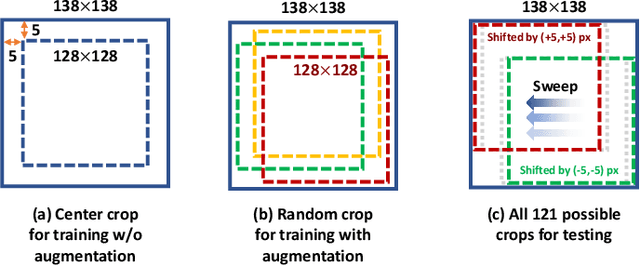
While accuracy is an evident criterion for ultrasound image segmentation, output consistency across different tests is equally crucial for tracking changes in regions of interest in applications such as monitoring the patients' response to treatment, measuring the progression or regression of the disease, reaching a diagnosis, or treatment planning. Convolutional neural networks (CNNs) have attracted rapidly growing interest in automatic ultrasound image segmentation recently. However, CNNs are not shift-equivariant, meaning that if the input translates, e.g., in the lateral direction by one pixel, the output segmentation may drastically change. To the best of our knowledge, this problem has not been studied in ultrasound image segmentation or even more broadly in ultrasound images. Herein, we investigate and quantify the shift-variance problem of CNNs in this application and further evaluate the performance of a recently published technique, called BlurPooling, for addressing the problem. In addition, we propose the Pyramidal BlurPooling method that outperforms BlurPooling in both output consistency and segmentation accuracy. Finally, we demonstrate that data augmentation is not a replacement for the proposed method. Source code is available at https://git.io/pbpunet and http://code.sonography.ai.
From Hand-Crafted to Deep Learning-based Cancer Radiomics: Challenges and Opportunities
Aug 27, 2018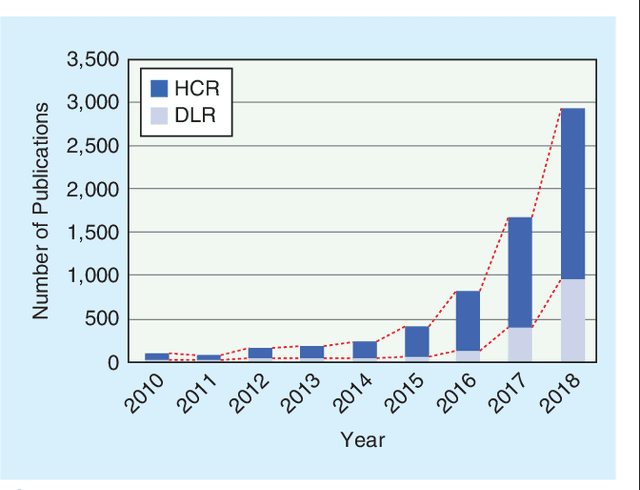
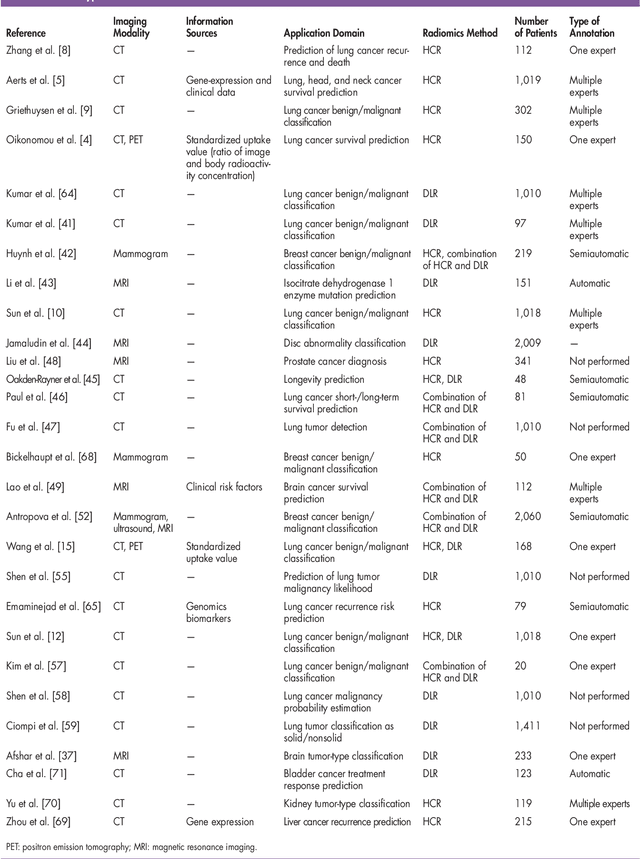

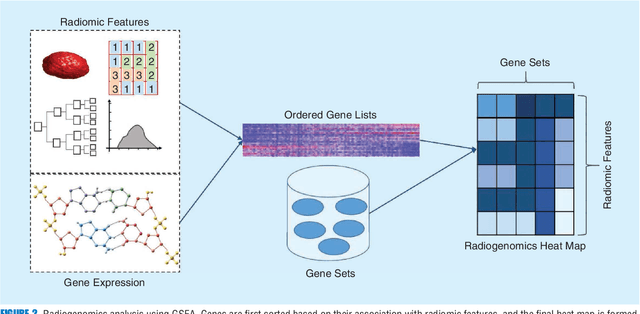
Recent advancements in signal processing and machine learning coupled with developments of electronic medical record keeping in hospitals and the availability of extensive set of medical images through internal/external communication systems, have resulted in a recent surge of significant interest in "Radiomics". Radiomics is an emerging and relatively new research field, which refers to extracting semi-quantitative and/or quantitative features from medical images with the goal of developing predictive and/or prognostic models, and is expected to become a critical component for integration of image-derived information for personalized treatment in the near future. The conventional Radiomics workflow is typically based on extracting pre-designed features (also referred to as hand-crafted or engineered features) from a segmented region of interest. Nevertheless, recent advancements in deep learning have caused trends towards deep learning-based Radiomics (also referred to as discovery Radiomics). Capitalizing on the advantageous of these two approaches, there are also hybrid solutions developed to exploit the potentials of multiple data sources. Considering the variety of approaches to Radiomics, further improvements require a comprehensive and integrated sketch, which is the goal of this article. This manuscript provides a unique interdisciplinary perspective on Radiomics by discussing state-of-the-art signal processing solutions in the context of cancer Radiomics.