 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-shot Adaptation of Medical Vision-Language Models
Sep 05, 2024Integrating image and text data through multi-modal learning has emerged as a new approach in medical imaging research, following its successful deployment in computer vision. While considerable efforts have been dedicated to establishing medical foundation models and their zero-shot transfer to downstream tasks, the popular few-shot setting remains relatively unexplored. Following on from the currently strong emergence of this setting in computer vision, we introduce the first structured benchmark for adapting medical vision-language models (VLMs) in a strict few-shot regime and investigate various adaptation strategies commonly used in the context of natural images. Furthermore, we evaluate a simple generalization of the linear-probe adaptation baseline, which seeks an optimal blending of the visual prototypes and text embeddings via learnable class-wise multipliers. Surprisingly, such a text-informed linear probe yields competitive performances in comparison to convoluted prompt-learning and adapter-based strategies, while running considerably faster and accommodating the black-box setting. Our extensive experiments span three different medical modalities and specialized foundation models, nine downstream tasks, and several state-of-the-art few-shot adaptation methods. We made our benchmark and code publicly available to trigger further developments in this emergent subject: \url{https://github.com/FereshteShakeri/few-shot-MedVLMs}.
Channel-Selective Normalization for Label-Shift Robust Test-Time Adaptation
Feb 07, 2024



Deep neural networks have useful applications in many different tasks, however their performance can be severely affected by changes in the data distribution. For example, in the biomedical field, their performance can be affected by changes in the data (different machines, populations) between training and test datasets. To ensure robustness and generalization to real-world scenarios, test-time adaptation has been recently studied as an approach to adjust models to a new data distribution during inference. Test-time batch normalization is a simple and popular method that achieved compelling performance on domain shift benchmarks. It is implemented by recalculating batch normalization statistics on test batches. Prior work has focused on analysis with test data that has the same label distribution as the training data. However, in many practical applications this technique is vulnerable to label distribution shifts, sometimes producing catastrophic failure. This presents a risk in applying test time adaptation methods in deployment. We propose to tackle this challenge by only selectively adapting channels in a deep network, minimizing drastic adaptation that is sensitive to label shifts. Our selection scheme is based on two principles that we empirically motivate: (1) later layers of networks are more sensitive to label shift (2) individual features can be sensitive to specific classes. We apply the proposed technique to three classification tasks, including CIFAR10-C, Imagenet-C, and diagnosis of fatty liver, where we explore both covariate and label distribution shifts. We find that our method allows to bring the benefits of TTA while significantly reducing the risk of failure common in other methods, while being robust to choice in hyperparameters.
Homodyned K-Distribution Parameter Estimation in Quantitative Ultrasound: Autoencoder and Bayesian Neural Network Approaches
Jan 19, 2024



Quantitative ultrasound (QUS) analyzes the ultrasound backscattered data to find the properties of scatterers that correlate with the tissue microstructure. Statistics of the envelope of the backscattered radiofrequency (RF) data can be utilized to estimate several QUS parameters. Different distributions have been proposed to model envelope data. The homodyned K-distribution (HK distribution) is one of the most comprehensive distributions that can model ultrasound backscattered envelope data under diverse scattering conditions (varying scatterer number density and coherent scattering). The scatterer clustering parameter (alpha) and the ratio of the coherent to diffuse scattering power (k) are the parameters of this distribution that have been used extensively for tissue characterization in diagnostic ultrasound. The estimation of these two parameters (which we refer to as HK parameters) is done using optimization algorithms in which statistical features such as the envelope point-wise signalto-noise ratio (SNR), skewness, kurtosis, and the log-based moments have been utilized as input to such algorithms. The optimization methods minimize the difference between features and their theoretical value from the HK model. We propose that the true value of these statistical features is a hyperplane that covers a small portion of the feature space. In this paper, we follow two approaches to reduce the effect of sample features' error. We propose a model projection neural network based on denoising autoencoders to project the noisy features into this space based on this assumption. We also investigate if the noise distribution can be learned by the deep estimators. We compare the proposed methods with conventional methods using simulations, an experimental phantom, and data from an in vivo animal model of hepatic steatosis. A demo code are available online at http://code.sonography.ai
Semi-supervised ViT knowledge distillation network with style transfer normalization for colorectal liver metastases survival prediction
Nov 17, 2023



Colorectal liver metastases (CLM) significantly impact colon cancer patients, influencing survival based on systemic chemotherapy response. Traditional methods like tumor grading scores (e.g., tumor regression grade - TRG) for prognosis suffer from subjectivity, time constraints, and expertise demands. Current machine learning approaches often focus on radiological data, yet the relevance of histological images for survival predictions, capturing intricate tumor microenvironment characteristics, is gaining recognition. To address these limitations, we propose an end-to-end approach for automated prognosis prediction using histology slides stained with H&E and HPS. We first employ a Generative Adversarial Network (GAN) for slide normalization to reduce staining variations and improve the overall quality of the images that are used as input to our prediction pipeline. We propose a semi-supervised model to perform tissue classification from sparse annotations, producing feature maps. We use an attention-based approach that weighs the importance of different slide regions in producing the final classification results. We exploit the extracted features for the metastatic nodules and surrounding tissue to train a prognosis model. In parallel, we train a vision Transformer (ViT) in a knowledge distillation framework to replicate and enhance the performance of the prognosis prediction. In our evaluation on a clinical dataset of 258 patients, our approach demonstrates superior performance with c-indexes of 0.804 (0.014) for OS and 0.733 (0.014) for TTR. Achieving 86.9% to 90.3% accuracy in predicting TRG dichotomization and 78.5% to 82.1% accuracy for the 3-class TRG classification task, our approach outperforms comparative methods. Our proposed pipeline can provide automated prognosis for pathologists and oncologists, and can greatly promote precision medicine progress in managing CLM patients.
Phase Aberration Correction: A Deep Learning-Based Aberration to Aberration Approach
Aug 22, 2023



One of the primary sources of suboptimal image quality in ultrasound imaging is phase aberration. It is caused by spatial changes in sound speed over a heterogeneous medium, which disturbs the transmitted waves and prevents coherent summation of echo signals. Obtaining non-aberrated ground truths in real-world scenarios can be extremely challenging, if not impossible. This challenge hinders training of deep learning-based techniques' performance due to the presence of domain shift between simulated and experimental data. Here, for the first time, we propose a deep learning-based method that does not require ground truth to correct the phase aberration problem, and as such, can be directly trained on real data. We train a network wherein both the input and target output are randomly aberrated radio frequency (RF) data. Moreover, we demonstrate that a conventional loss function such as mean square error is inadequate for training such a network to achieve optimal performance. Instead, we propose an adaptive mixed loss function that employs both B-mode and RF data, resulting in more efficient convergence and enhanced performance. Finally, we publicly release our dataset, including 161,701 single plane-wave images (RF data). This dataset serves to mitigate the data scarcity problem in the development of deep learning-based techniques for phase aberration correction.
End-to-End Discriminative Deep Network for Liver Lesion Classification
Jan 28, 2019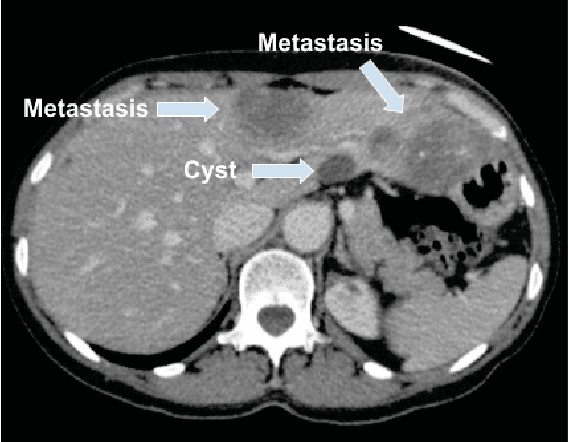
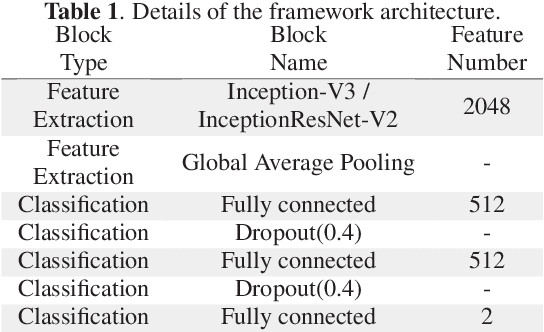
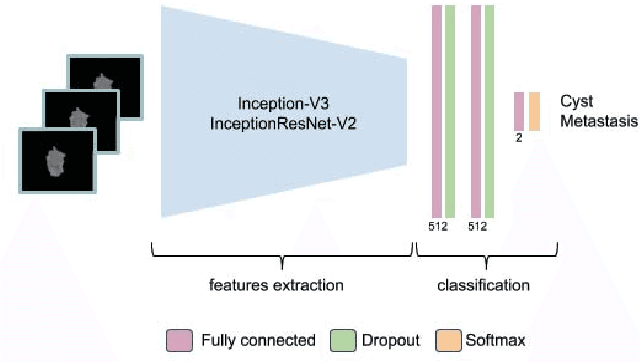

Colorectal liver metastasis is one of most aggressive liver malignancies. While the definition of lesion type based on CT images determines the diagnosis and therapeutic strategy, the discrimination between cancerous and non-cancerous lesions are critical and requires highly skilled expertise, experience and time. In the present work we introduce an end-to-end deep learning approach to assist in the discrimination between liver metastases from colorectal cancer and benign cysts in abdominal CT images of the liver. Our approach incorporates the efficient feature extraction of InceptionV3 combined with residual connections and pre-trained weights from ImageNet. The architecture also includes fully connected classification layers to generate a probabilistic output of lesion type. We use an in-house clinical biobank with 230 liver lesions originating from 63 patients. With an accuracy of 0.96 and a F1-score of 0.92, the results obtained with the proposed approach surpasses state of the art methods. Our work provides the basis for incorporating machine learning tools in specialized radiology software to assist physicians in the early detection and treatment of liver lesions.
The Liver Tumor Segmentation Benchmark (LiTS)
Jan 13, 2019

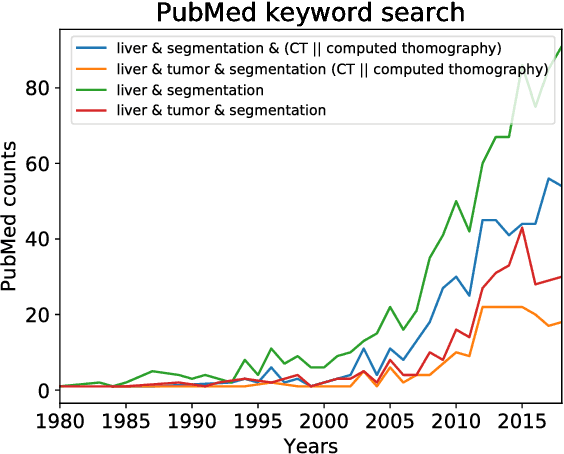

In this work, we report the set-up and results of the Liver Tumor Segmentation Benchmark (LITS) organized in conjunction with the IEEE International Symposium on Biomedical Imaging (ISBI) 2016 and International Conference On Medical Image Computing Computer Assisted Intervention (MICCAI) 2017. Twenty four valid state-of-the-art liver and liver tumor segmentation algorithms were applied to a set of 131 computed tomography (CT) volumes with different types of tumor contrast levels (hyper-/hypo-intense), abnormalities in tissues (metastasectomie) size and varying amount of lesions. The submitted algorithms have been tested on 70 undisclosed volumes. The dataset is created in collaboration with seven hospitals and research institutions and manually reviewed by independent three radiologists. We found that not a single algorithm performed best for liver and tumors. The best liver segmentation algorithm achieved a Dice score of 0.96(MICCAI) whereas for tumor segmentation the best algorithm evaluated at 0.67(ISBI) and 0.70(MICCAI). The LITS image data and manual annotations continue to be publicly available through an online evaluation system as an ongoing benchmarking resource.
Multi-Level Batch Normalization In Deep Networks For Invasive Ductal Carcinoma Cell Discrimination In Histopathology Images
Jan 11, 2019
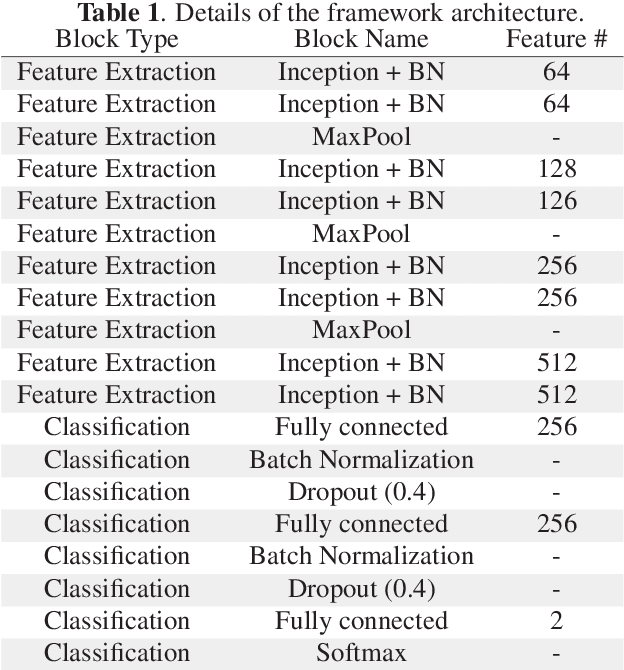
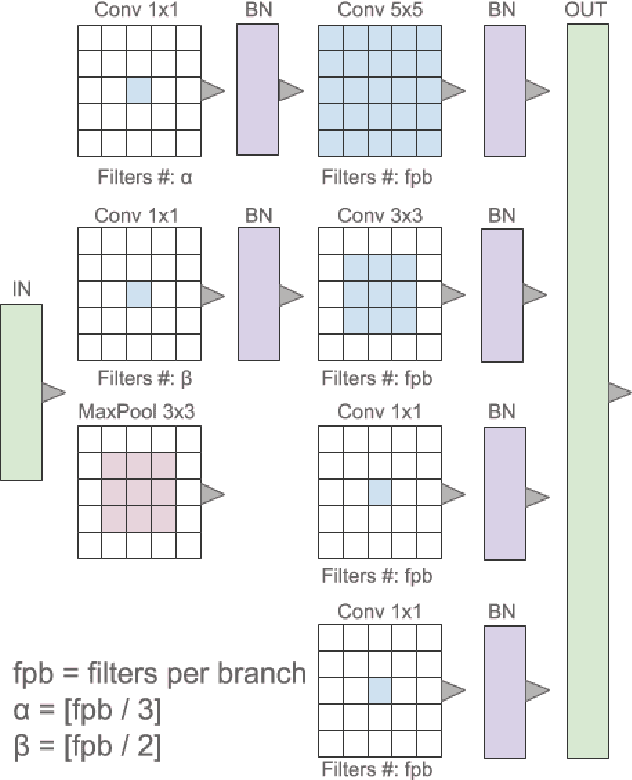
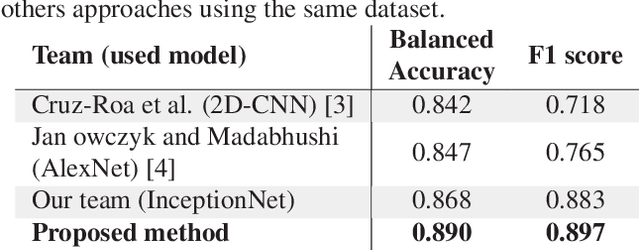
Breast cancer is the most diagnosed cancer and the most predominant cause of death in women worldwide. Imaging techniques such as the breast cancer pathology helps in the diagnosis and monitoring of the disease. However identification of malignant cells can be challenging given the high heterogeneity in tissue absorbotion from staining agents. In this work, we present a novel approach for Invasive Ductal Carcinoma (IDC) cells discrimination in histopathology slides. We propose a model derived from the Inception architecture, proposing a multi-level batch normalization module between each convolutional steps. This module was used as a base block for the feature extraction in a CNN architecture. We used the open IDC dataset in which we obtained a balanced accuracy of 0.89 and an F1 score of 0.90, thus surpassing recent state of the art classification algorithms tested on this public dataset.
Liver lesion segmentation informed by joint liver segmentation
Aug 11, 2018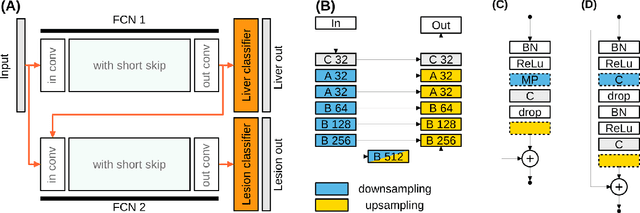
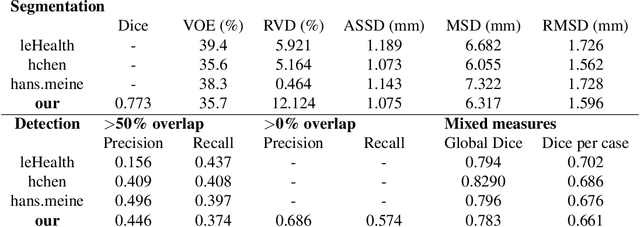
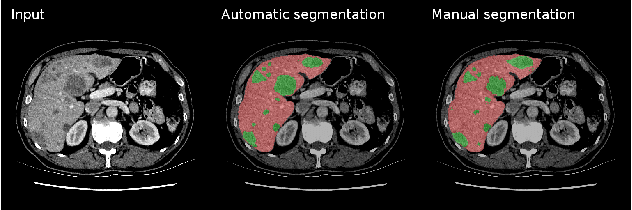
We propose a model for the joint segmentation of the liver and liver lesions in computed tomography (CT) volumes. We build the model from two fully convolutional networks, connected in tandem and trained together end-to-end. We evaluate our approach on the 2017 MICCAI Liver Tumour Segmentation Challenge, attaining competitive liver and liver lesion detection and segmentation scores across a wide range of metrics. Unlike other top performing methods, our model output post-processing is trivial, we do not use data external to the challenge, and we propose a simple single-stage model that is trained end-to-end. However, our method nearly matches the top lesion segmentation performance and achieves the second highest precision for lesion detection while maintaining high recall.
Learning Normalized Inputs for Iterative Estimation in Medical Image Segmentation
Feb 16, 2017
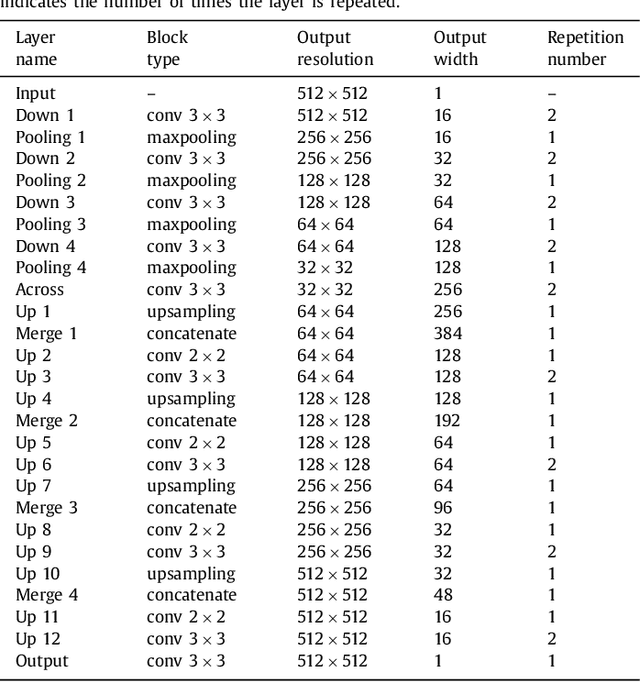
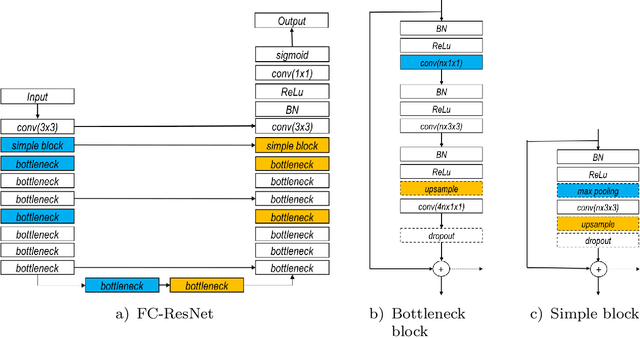

In this paper, we introduce a simple, yet powerful pipeline for medical image segmentation that combines Fully Convolutional Networks (FCNs) with Fully Convolutional Residual Networks (FC-ResNets). We propose and examine a design that takes particular advantage of recent advances in the understanding of both Convolutional Neural Networks as well as ResNets. Our approach focuses upon the importance of a trainable pre-processing when using FC-ResNets and we show that a low-capacity FCN model can serve as a pre-processor to normalize medical input data. In our image segmentation pipeline, we use FCNs to obtain normalized images, which are then iteratively refined by means of a FC-ResNet to generate a segmentation prediction. As in other fully convolutional approaches, our pipeline can be used off-the-shelf on different image modalities. We show that using this pipeline, we exhibit state-of-the-art performance on the challenging Electron Microscopy benchmark, when compared to other 2D methods. We improve segmentation results on CT images of liver lesions, when contrasting with standard FCN methods. Moreover, when applying our 2D pipeline on a challenging 3D MRI prostate segmentation challenge we reach results that are competitive even when compared to 3D methods. The obtained results illustrate the strong potential and versatility of the pipeline by achieving highly accurate results on multi-modality images from different anatomical regions and organs.