 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Liver Tumor Segmentation Benchmark (LiTS)
Jan 13, 2019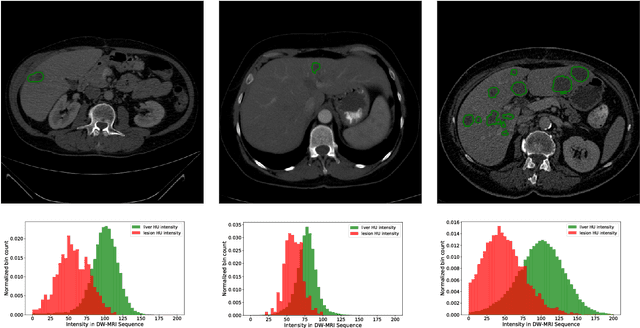

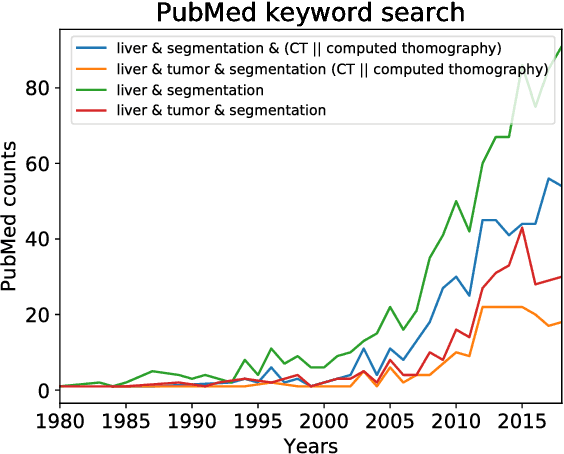

In this work, we report the set-up and results of the Liver Tumor Segmentation Benchmark (LITS) organized in conjunction with the IEEE International Symposium on Biomedical Imaging (ISBI) 2016 and International Conference On Medical Image Computing Computer Assisted Intervention (MICCAI) 2017. Twenty four valid state-of-the-art liver and liver tumor segmentation algorithms were applied to a set of 131 computed tomography (CT) volumes with different types of tumor contrast levels (hyper-/hypo-intense), abnormalities in tissues (metastasectomie) size and varying amount of lesions. The submitted algorithms have been tested on 70 undisclosed volumes. The dataset is created in collaboration with seven hospitals and research institutions and manually reviewed by independent three radiologists. We found that not a single algorithm performed best for liver and tumors. The best liver segmentation algorithm achieved a Dice score of 0.96(MICCAI) whereas for tumor segmentation the best algorithm evaluated at 0.67(ISBI) and 0.70(MICCAI). The LITS image data and manual annotations continue to be publicly available through an online evaluation system as an ongoing benchmarking resource.
On the Importance of Attention in Meta-Learning for Few-Shot Text Classification
Jun 03, 2018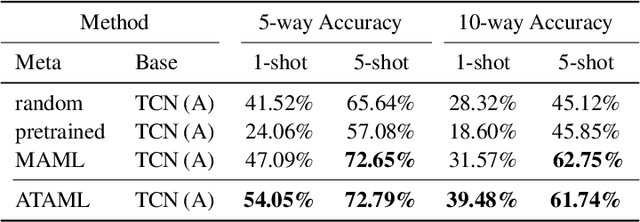
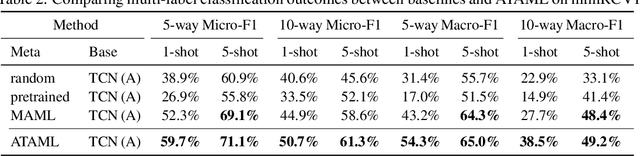
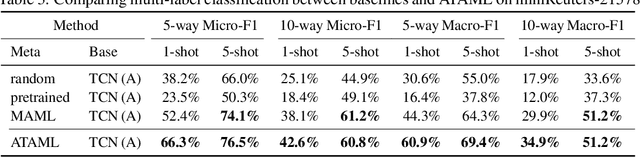
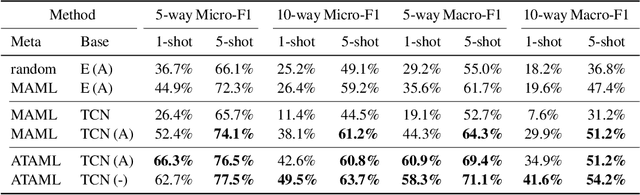
Current deep learning based text classification methods are limited by their ability to achieve fast learning and generalization when the data is scarce. We address this problem by integrating a meta-learning procedure that uses the knowledge learned across many tasks as an inductive bias towards better natural language understanding. Based on the Model-Agnostic Meta-Learning framework (MAML), we introduce the Attentive Task-Agnostic Meta-Learning (ATAML) algorithm for text classification. The essential difference between MAML and ATAML is in the separation of task-agnostic representation learning and task-specific attentive adaptation. The proposed ATAML is designed to encourage task-agnostic representation learning by way of task-agnostic parameterization and facilitate task-specific adaptation via attention mechanisms. We provide evidence to show that the attention mechanism in ATAML has a synergistic effect on learning performance. In comparisons with models trained from random initialization, pretrained models and meta trained MAML, our proposed ATAML method generalizes better on single-label and multi-label classification tasks in miniRCV1 and miniReuters-21578 datasets.
Learning Normalized Inputs for Iterative Estimation in Medical Image Segmentation
Feb 16, 2017
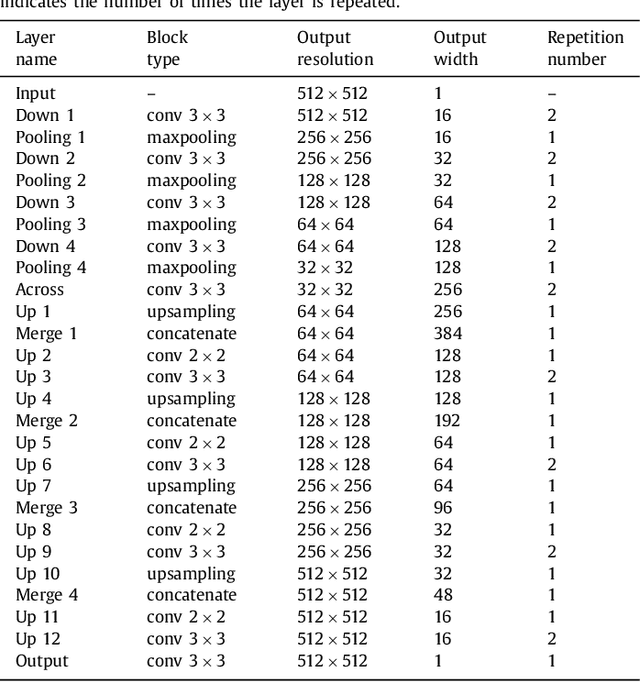
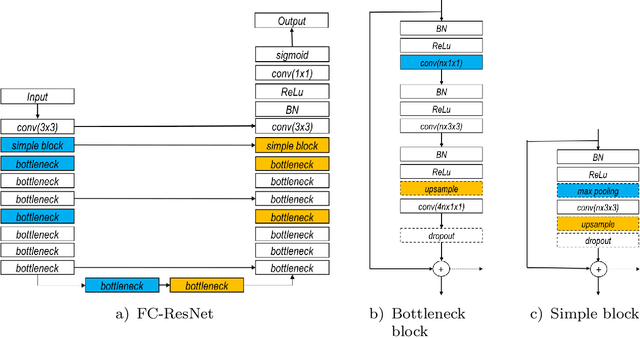

In this paper, we introduce a simple, yet powerful pipeline for medical image segmentation that combines Fully Convolutional Networks (FCNs) with Fully Convolutional Residual Networks (FC-ResNets). We propose and examine a design that takes particular advantage of recent advances in the understanding of both Convolutional Neural Networks as well as ResNets. Our approach focuses upon the importance of a trainable pre-processing when using FC-ResNets and we show that a low-capacity FCN model can serve as a pre-processor to normalize medical input data. In our image segmentation pipeline, we use FCNs to obtain normalized images, which are then iteratively refined by means of a FC-ResNet to generate a segmentation prediction. As in other fully convolutional approaches, our pipeline can be used off-the-shelf on different image modalities. We show that using this pipeline, we exhibit state-of-the-art performance on the challenging Electron Microscopy benchmark, when compared to other 2D methods. We improve segmentation results on CT images of liver lesions, when contrasting with standard FCN methods. Moreover, when applying our 2D pipeline on a challenging 3D MRI prostate segmentation challenge we reach results that are competitive even when compared to 3D methods. The obtained results illustrate the strong potential and versatility of the pipeline by achieving highly accurate results on multi-modality images from different anatomical regions and organs.
The Importance of Skip Connections in Biomedical Image Segmentation
Sep 22, 2016


In this paper, we study the influence of both long and short skip connections on Fully Convolutional Networks (FCN) for biomedical image segmentation. In standard FCNs, only long skip connections are used to skip features from the contracting path to the expanding path in order to recover spatial information lost during downsampling. We extend FCNs by adding short skip connections, that are similar to the ones introduced in residual networks, in order to build very deep FCNs (of hundreds of layers). A review of the gradient flow confirms that for a very deep FCN it is beneficial to have both long and short skip connections. Finally, we show that a very deep FCN can achieve near-to-state-of-the-art results on the EM dataset without any further post-processing.