 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Importance of Attention in Meta-Learning for Few-Shot Text Classification
Jun 03, 2018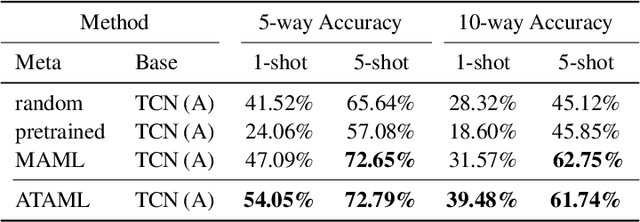
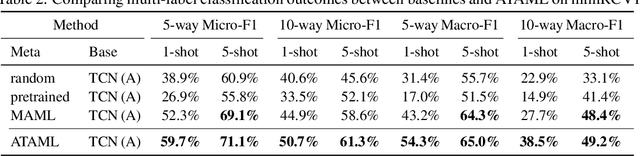
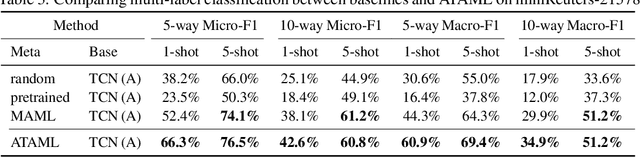
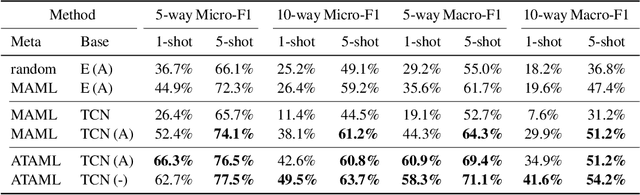
Current deep learning based text classification methods are limited by their ability to achieve fast learning and generalization when the data is scarce. We address this problem by integrating a meta-learning procedure that uses the knowledge learned across many tasks as an inductive bias towards better natural language understanding. Based on the Model-Agnostic Meta-Learning framework (MAML), we introduce the Attentive Task-Agnostic Meta-Learning (ATAML) algorithm for text classification. The essential difference between MAML and ATAML is in the separation of task-agnostic representation learning and task-specific attentive adaptation. The proposed ATAML is designed to encourage task-agnostic representation learning by way of task-agnostic parameterization and facilitate task-specific adaptation via attention mechanisms. We provide evidence to show that the attention mechanism in ATAML has a synergistic effect on learning performance. In comparisons with models trained from random initialization, pretrained models and meta trained MAML, our proposed ATAML method generalizes better on single-label and multi-label classification tasks in miniRCV1 and miniReuters-21578 datasets.