 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSKILL.nb: Selective Formalization and Gated Execution for Durable Agent Workflows
Jun 06, 2026AI agents increasingly turn past experience into reusable artifacts such as code, workflows, and procedural memories. Reuse can improve efficiency, but it also creates a lifecycle reliability problem: artifacts that succeed once may fail under environment drift, underspecified tasks, or changing task distributions, especially in web automation. We introduce SKILL.nb, a framework for governing reusable agent workflows with evidence-calibrated lifecycle policies. SKILL.nb uses selective formalization: execution evidence decides which workflow steps should become executable code, which should remain natural-language guided, and when those choices should be revised. Workflows are stored as auditable, versioned notebooks that interleave natural-language guidance, multi-language executable cells, validation gates, fallback paths, and multimodal evidence such as outputs, screenshots, and error traces. At runtime, gate-conditioned execution lets each step run code when its gates validate, or fall back locally when drift invalidates the executable realization. On WebArena-Verified, SKILL.nb achieves 53.7% single-round success, improving over the strongest baseline by 3.9 percentage points. Across three re-executions, it retains 91.7% of initially successful tasks, 15.5 points above the next best method. Under bounded repair, it recovers 72.9% of subsequent failures while limiting post-repair regressions to 4.2%, compared with 15.0% to 17.0% for persistent baselines. It also leads on Mind2Web cross-website and cross-domain splits. In a GitLab migration test, SKILL.nb preserves performance when reusing frozen state learned on GitLab 15.7, with frozen-versus-fresh target-version gaps of -1.7 points on GitLab 16.11 and +0.6 points on GitLab 18.9. These results identify lifecycle governance and gate-conditioned execution as reliability axes beyond one-shot task success.
LLM2Vec-Gen: Generative Embeddings from Large Language Models
Mar 11, 2026LLM-based text embedders typically encode the semantic content of their input. However, embedding tasks require mapping diverse inputs to similar outputs. Typically, this input-output is addressed by training embedding models with paired data using contrastive learning. In this work, we propose a novel self-supervised approach, LLM2Vec-Gen, which adopts a different paradigm: rather than encoding the input, we learn to represent the model's potential response. Specifically, we add trainable special tokens to the LLM's vocabulary, append them to input, and optimize them to represent the LLM's response in a fixed-length sequence. Training is guided by the LLM's own completion for the query, along with an unsupervised embedding teacher that provides distillation targets. This formulation helps to bridge the input-output gap and transfers LLM capabilities such as safety alignment and reasoning to embedding tasks. Crucially, the LLM backbone remains frozen and training requires only unlabeled queries. LLM2Vec-Gen achieves state-of-the-art self-supervised performance on the Massive Text Embedding Benchmark (MTEB), improving by 9.3% over the best unsupervised embedding teacher. We also observe up to 43.2% reduction in harmful content retrieval and 29.3% improvement in reasoning capabilities for embedding tasks. Finally, the learned embeddings are interpretable and can be decoded into text to reveal their semantic content.
Grounding Computer Use Agents on Human Demonstrations
Nov 10, 2025



Building reliable computer-use agents requires grounding: accurately connecting natural language instructions to the correct on-screen elements. While large datasets exist for web and mobile interactions, high-quality resources for desktop environments are limited. To address this gap, we introduce GroundCUA, a large-scale desktop grounding dataset built from expert human demonstrations. It covers 87 applications across 12 categories and includes 56K screenshots, with every on-screen element carefully annotated for a total of over 3.56M human-verified annotations. From these demonstrations, we generate diverse instructions that capture a wide range of real-world tasks, providing high-quality data for model training. Using GroundCUA, we develop the GroundNext family of models that map instructions to their target UI elements. At both 3B and 7B scales, GroundNext achieves state-of-the-art results across five benchmarks using supervised fine-tuning, while requiring less than one-tenth the training data of prior work. Reinforcement learning post-training further improves performance, and when evaluated in an agentic setting on the OSWorld benchmark using o3 as planner, GroundNext attains comparable or superior results to models trained with substantially more data,. These results demonstrate the critical role of high-quality, expert-driven datasets in advancing general-purpose computer-use agents.
Beyond Naïve Prompting: Strategies for Improved Zero-shot Context-aided Forecasting with LLMs
Aug 13, 2025Forecasting in real-world settings requires models to integrate not only historical data but also relevant contextual information, often available in textual form. While recent work has shown that large language models (LLMs) can be effective context-aided forecasters via na\"ive direct prompting, their full potential remains underexplored. We address this gap with 4 strategies, providing new insights into the zero-shot capabilities of LLMs in this setting. ReDP improves interpretability by eliciting explicit reasoning traces, allowing us to assess the model's reasoning over the context independently from its forecast accuracy. CorDP leverages LLMs solely to refine existing forecasts with context, enhancing their applicability in real-world forecasting pipelines. IC-DP proposes embedding historical examples of context-aided forecasting tasks in the prompt, substantially improving accuracy even for the largest models. Finally, RouteDP optimizes resource efficiency by using LLMs to estimate task difficulty, and routing the most challenging tasks to larger models. Evaluated on different kinds of context-aided forecasting tasks from the CiK benchmark, our strategies demonstrate distinct benefits over na\"ive prompting across LLMs of different sizes and families. These results open the door to further simple yet effective improvements in LLM-based context-aided forecasting.
UI-Vision: A Desktop-centric GUI Benchmark for Visual Perception and Interaction
Mar 19, 2025Autonomous agents that navigate Graphical User Interfaces (GUIs) to automate tasks like document editing and file management can greatly enhance computer workflows. While existing research focuses on online settings, desktop environments, critical for many professional and everyday tasks, remain underexplored due to data collection challenges and licensing issues. We introduce UI-Vision, the first comprehensive, license-permissive benchmark for offline, fine-grained evaluation of computer use agents in real-world desktop environments. Unlike online benchmarks, UI-Vision provides: (i) dense, high-quality annotations of human demonstrations, including bounding boxes, UI labels, and action trajectories (clicks, drags, and keyboard inputs) across 83 software applications, and (ii) three fine-to-coarse grained tasks-Element Grounding, Layout Grounding, and Action Prediction-with well-defined metrics to rigorously evaluate agents' performance in desktop environments. Our evaluation reveals critical limitations in state-of-the-art models like UI-TARS-72B, including issues with understanding professional software, spatial reasoning, and complex actions like drag-and-drop. These findings highlight the challenges in developing fully autonomous computer use agents. By releasing UI-Vision as open-source, we aim to advance the development of more capable agents for real-world desktop tasks.
AlignVLM: Bridging Vision and Language Latent Spaces for Multimodal Understanding
Feb 03, 2025



Aligning visual features with language embeddings is a key challenge in vision-language models (VLMs). The performance of such models hinges on having a good connector that maps visual features generated by a vision encoder to a shared embedding space with the LLM while preserving semantic similarity. Existing connectors, such as multilayer perceptrons (MLPs), often produce out-of-distribution or noisy inputs, leading to misalignment between the modalities. In this work, we propose a novel vision-text alignment method, AlignVLM, that maps visual features to a weighted average of LLM text embeddings. Our approach leverages the linguistic priors encoded by the LLM to ensure that visual features are mapped to regions of the space that the LLM can effectively interpret. AlignVLM is particularly effective for document understanding tasks, where scanned document images must be accurately mapped to their textual content. Our extensive experiments show that AlignVLM achieves state-of-the-art performance compared to prior alignment methods. We provide further analysis demonstrating improved vision-text feature alignment and robustness to noise.
The BrowserGym Ecosystem for Web Agent Research
Dec 10, 2024



The BrowserGym ecosystem addresses the growing need for efficient evaluation and benchmarking of web agents, particularly those leveraging automation and Large Language Models (LLMs) for web interaction tasks. Many existing benchmarks suffer from fragmentation and inconsistent evaluation methodologies, making it challenging to achieve reliable comparisons and reproducible results. BrowserGym aims to solve this by providing a unified, gym-like environment with well-defined observation and action spaces, facilitating standardized evaluation across diverse benchmarks. Combined with AgentLab, a complementary framework that aids in agent creation, testing, and analysis, BrowserGym offers flexibility for integrating new benchmarks while ensuring consistent evaluation and comprehensive experiment management. This standardized approach seeks to reduce the time and complexity of developing web agents, supporting more reliable comparisons and facilitating in-depth analysis of agent behaviors, and could result in more adaptable, capable agents, ultimately accelerating innovation in LLM-driven automation. As a supporting evidence, we conduct the first large-scale, multi-benchmark web agent experiment and compare the performance of 6 state-of-the-art LLMs across all benchmarks currently available in BrowserGym. Among other findings, our results highlight a large discrepancy between OpenAI and Anthropic's latests models, with Claude-3.5-Sonnet leading the way on almost all benchmarks, except on vision-related tasks where GPT-4o is superior. Despite these advancements, our results emphasize that building robust and efficient web agents remains a significant challenge, due to the inherent complexity of real-world web environments and the limitations of current models.
BigDocs: An Open and Permissively-Licensed Dataset for Training Multimodal Models on Document and Code Tasks
Dec 05, 2024



Multimodal AI has the potential to significantly enhance document-understanding tasks, such as processing receipts, understanding workflows, extracting data from documents, and summarizing reports. Code generation tasks that require long-structured outputs can also be enhanced by multimodality. Despite this, their use in commercial applications is often limited due to limited access to training data and restrictive licensing, which hinders open access. To address these limitations, we introduce BigDocs-7.5M, a high-quality, open-access dataset comprising 7.5 million multimodal documents across 30 tasks. We use an efficient data curation process to ensure our data is high-quality and license-permissive. Our process emphasizes accountability, responsibility, and transparency through filtering rules, traceable metadata, and careful content analysis. Additionally, we introduce BigDocs-Bench, a benchmark suite with 10 novel tasks where we create datasets that reflect real-world use cases involving reasoning over Graphical User Interfaces (GUI) and code generation from images. Our experiments show that training with BigDocs-Bench improves average performance up to 25.8% over closed-source GPT-4o in document reasoning and structured output tasks such as Screenshot2HTML or Image2Latex generation. Finally, human evaluations showed a preference for outputs from models trained on BigDocs over GPT-4o. This suggests that BigDocs can help both academics and the open-source community utilize and improve AI tools to enhance multimodal capabilities and document reasoning. The project is hosted at https://bigdocs.github.io .
Context is Key: A Benchmark for Forecasting with Essential Textual Information
Oct 24, 2024



Forecasting is a critical task in decision making across various domains. While numerical data provides a foundation, it often lacks crucial context necessary for accurate predictions. Human forecasters frequently rely on additional information, such as background knowledge or constraints, which can be efficiently communicated through natural language. However, the ability of existing forecasting models to effectively integrate this textual information remains an open question. To address this, we introduce "Context is Key" (CiK), a time series forecasting benchmark that pairs numerical data with diverse types of carefully crafted textual context, requiring models to integrate both modalities. We evaluate a range of approaches, including statistical models, time series foundation models, and LLM-based forecasters, and propose a simple yet effective LLM prompting method that outperforms all other tested methods on our benchmark. Our experiments highlight the importance of incorporating contextual information, demonstrate surprising performance when using LLM-based forecasting models, and also reveal some of their critical shortcomings. By presenting this benchmark, we aim to advance multimodal forecasting, promoting models that are both accurate and accessible to decision-makers with varied technical expertise. The benchmark can be visualized at https://servicenow.github.io/context-is-key-forecasting/v0/ .
InsightBench: Evaluating Business Analytics Agents Through Multi-Step Insight Generation
Jul 08, 2024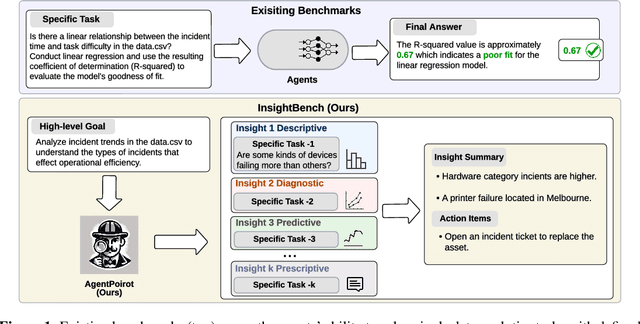
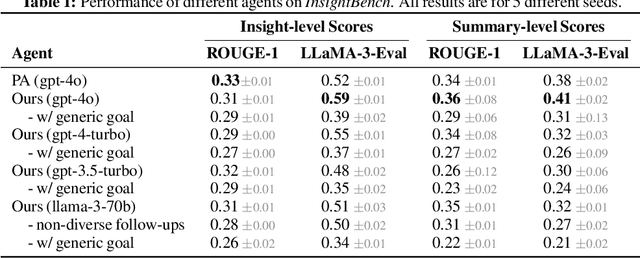
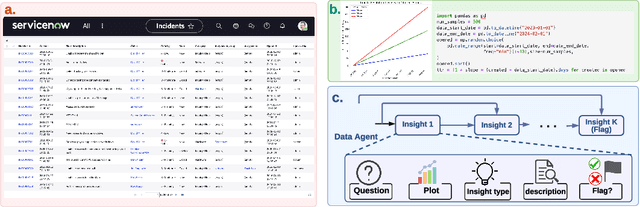
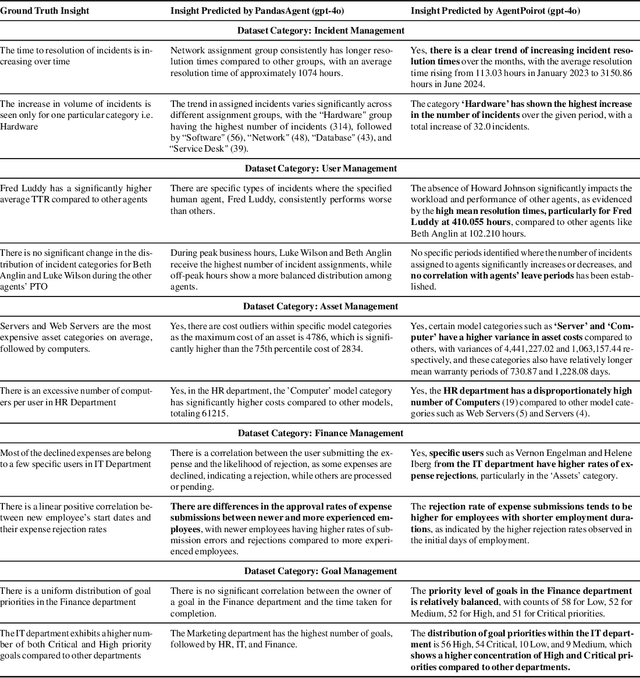
Data analytics is essential for extracting valuable insights from data that can assist organizations in making effective decisions. We introduce InsightBench, a benchmark dataset with three key features. First, it consists of 31 datasets representing diverse business use cases such as finance and incident management, each accompanied by a carefully curated set of insights planted in the datasets. Second, unlike existing benchmarks focusing on answering single queries, InsightBench evaluates agents based on their ability to perform end-to-end data analytics, including formulating questions, interpreting answers, and generating a summary of insights and actionable steps. Third, we conducted comprehensive quality assurance to ensure that each dataset in the benchmark had clear goals and included relevant and meaningful questions and analysis. Furthermore, we implement a two-way evaluation mechanism using LLaMA-3-Eval as an effective, open-source evaluator method to assess agents' ability to extract insights. We also propose AgentPoirot, our baseline data analysis agent capable of performing end-to-end data analytics. Our evaluation on InsightBench shows that AgentPoirot outperforms existing approaches (such as Pandas Agent) that focus on resolving single queries. We also compare the performance of open- and closed-source LLMs and various evaluation strategies. Overall, this benchmark serves as a testbed to motivate further development in comprehensive data analytics and can be accessed here: https://github.com/ServiceNow/insight-bench.