 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Design Space of Tri-Modal Masked Diffusion Models
Feb 25, 2026Discrete diffusion models have emerged as strong alternatives to autoregressive language models, with recent work initializing and fine-tuning a base unimodal model for bimodal generation. Diverging from previous approaches, we introduce the first tri-modal masked diffusion model pretrained from scratch on text, image-text, and audio-text data. We systematically analyze multimodal scaling laws, modality mixing ratios, noise schedules, and batch-size effects, and we provide optimized inference sampling defaults. Our batch-size analysis yields a novel stochastic differential equation (SDE)-based reparameterization that eliminates the need for tuning the optimal batch size as reported in recent work. This reparameterization decouples the physical batch size, often chosen based on compute constraints (GPU saturation, FLOP efficiency, wall-clock time), from the logical batch size, chosen to balance gradient variance during stochastic optimization. Finally, we pretrain a preliminary 3B-parameter tri-modal model on 6.4T tokens, demonstrating the capabilities of a unified design and achieving strong results in text generation, text-to-image tasks, and text-to-speech tasks. Our work represents the largest-scale systematic open study of multimodal discrete diffusion models conducted to date, providing insights into scaling behaviors across multiple modalities.
GraphOmni: A Comprehensive and Extendable Benchmark Framework for Large Language Models on Graph-theoretic Tasks
Apr 17, 2025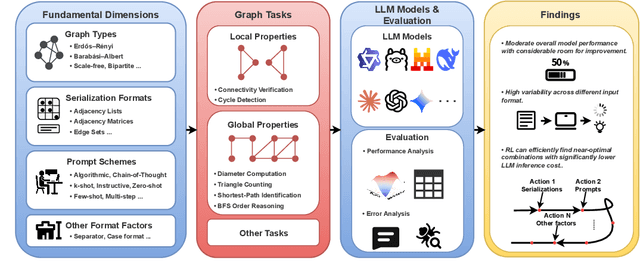

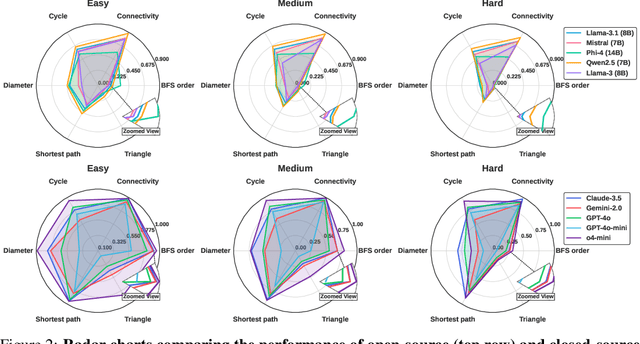
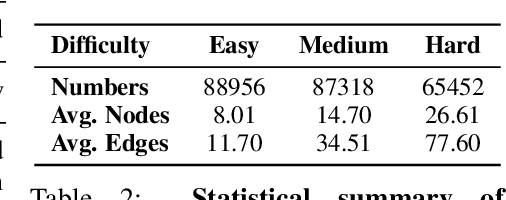
In this paper, we presented GraphOmni, a comprehensive benchmark framework for systematically evaluating the graph reasoning capabilities of LLMs. By analyzing critical dimensions, including graph types, serialization formats, and prompt schemes, we provided extensive insights into the strengths and limitations of current LLMs. Our empirical findings emphasize that no single serialization or prompting strategy consistently outperforms others. Motivated by these insights, we propose a reinforcement learning-based approach that dynamically selects the best serialization-prompt pairings, resulting in significant accuracy improvements. GraphOmni's modular and extensible design establishes a robust foundation for future research, facilitating advancements toward general-purpose graph reasoning models.
Explain-Query-Test: Self-Evaluating LLMs Via Explanation and Comprehension Discrepancy
Jan 20, 2025



Large language models (LLMs) have demonstrated remarkable proficiency in generating detailed and coherent explanations of complex concepts. However, the extent to which these models truly comprehend the concepts they articulate remains unclear. To assess the level of comprehension of a model relative to the content it generates, we implemented a self-evaluation pipeline where models: (i) given a topic generate an excerpt with information about the topic, (ii) given an excerpt generate question-answer pairs, and finally (iii) given a question generate an answer. We refer to this self-evaluation approach as Explain-Query-Test (EQT). Interestingly, the accuracy on generated questions resulting from running the EQT pipeline correlates strongly with the model performance as verified by typical benchmarks such as MMLU-Pro. In other words, EQT's performance is predictive of MMLU-Pro's, and EQT can be used to rank models without the need for any external source of evaluation data other than lists of topics of interest. Moreover, our results reveal a disparity between the models' ability to produce detailed explanations and their performance on questions related to those explanations. This gap highlights fundamental limitations in the internal knowledge representation and reasoning abilities of current LLMs. We release the code at https://github.com/asgsaeid/EQT.
Performance Control in Early Exiting to Deploy Large Models at the Same Cost of Smaller Ones
Dec 26, 2024Early Exiting (EE) is a promising technique for speeding up inference by adaptively allocating compute resources to data points based on their difficulty. The approach enables predictions to exit at earlier layers for simpler samples while reserving more computation for challenging ones. In this study, we first present a novel perspective on the EE approach, showing that larger models deployed with EE can achieve higher performance than smaller models while maintaining similar computational costs. As existing EE approaches rely on confidence estimation at each exit point, we further study the impact of overconfidence on the controllability of the compute-performance trade-off. We introduce Performance Control Early Exiting (PCEE), a method that enables accuracy thresholding by basing decisions not on a data point's confidence but on the average accuracy of samples with similar confidence levels from a held-out validation set. In our experiments, we show that PCEE offers a simple yet computationally efficient approach that provides better control over performance than standard confidence-based approaches, and allows us to scale up model sizes to yield performance gain while reducing the computational cost.
BigDocs: An Open and Permissively-Licensed Dataset for Training Multimodal Models on Document and Code Tasks
Dec 05, 2024



Multimodal AI has the potential to significantly enhance document-understanding tasks, such as processing receipts, understanding workflows, extracting data from documents, and summarizing reports. Code generation tasks that require long-structured outputs can also be enhanced by multimodality. Despite this, their use in commercial applications is often limited due to limited access to training data and restrictive licensing, which hinders open access. To address these limitations, we introduce BigDocs-7.5M, a high-quality, open-access dataset comprising 7.5 million multimodal documents across 30 tasks. We use an efficient data curation process to ensure our data is high-quality and license-permissive. Our process emphasizes accountability, responsibility, and transparency through filtering rules, traceable metadata, and careful content analysis. Additionally, we introduce BigDocs-Bench, a benchmark suite with 10 novel tasks where we create datasets that reflect real-world use cases involving reasoning over Graphical User Interfaces (GUI) and code generation from images. Our experiments show that training with BigDocs-Bench improves average performance up to 25.8% over closed-source GPT-4o in document reasoning and structured output tasks such as Screenshot2HTML or Image2Latex generation. Finally, human evaluations showed a preference for outputs from models trained on BigDocs over GPT-4o. This suggests that BigDocs can help both academics and the open-source community utilize and improve AI tools to enhance multimodal capabilities and document reasoning. The project is hosted at https://bigdocs.github.io .
RepLiQA: A Question-Answering Dataset for Benchmarking LLMs on Unseen Reference Content
Jun 17, 2024Large Language Models (LLMs) are trained on vast amounts of data, most of which is automatically scraped from the internet. This data includes encyclopedic documents that harbor a vast amount of general knowledge (e.g., Wikipedia) but also potentially overlap with benchmark datasets used for evaluating LLMs. Consequently, evaluating models on test splits that might have leaked into the training set is prone to misleading conclusions. To foster sound evaluation of language models, we introduce a new test dataset named RepLiQA, suited for question-answering and topic retrieval tasks. RepLiQA is a collection of five splits of test sets, four of which have not been released to the internet or exposed to LLM APIs prior to this publication. Each sample in RepLiQA comprises (1) a reference document crafted by a human annotator and depicting an imaginary scenario (e.g., a news article) absent from the internet; (2) a question about the document's topic; (3) a ground-truth answer derived directly from the information in the document; and (4) the paragraph extracted from the reference document containing the answer. As such, accurate answers can only be generated if a model can find relevant content within the provided document. We run a large-scale benchmark comprising several state-of-the-art LLMs to uncover differences in performance across models of various types and sizes in a context-conditional language modeling setting. Released splits of RepLiQA can be found here: https://huggingface.co/datasets/ServiceNow/repliqa.
Group Robust Classification Without Any Group Information
Oct 28, 2023



Empirical risk minimization (ERM) is sensitive to spurious correlations in the training data, which poses a significant risk when deploying systems trained under this paradigm in high-stake applications. While the existing literature focuses on maximizing group-balanced or worst-group accuracy, estimating these accuracies is hindered by costly bias annotations. This study contends that current bias-unsupervised approaches to group robustness continue to rely on group information to achieve optimal performance. Firstly, these methods implicitly assume that all group combinations are represented during training. To illustrate this, we introduce a systematic generalization task on the MPI3D dataset and discover that current algorithms fail to improve the ERM baseline when combinations of observed attribute values are missing. Secondly, bias labels are still crucial for effective model selection, restricting the practicality of these methods in real-world scenarios. To address these limitations, we propose a revised methodology for training and validating debiased models in an entirely bias-unsupervised manner. We achieve this by employing pretrained self-supervised models to reliably extract bias information, which enables the integration of a logit adjustment training loss with our validation criterion. Our empirical analysis on synthetic and real-world tasks provides evidence that our approach overcomes the identified challenges and consistently enhances robust accuracy, attaining performance which is competitive with or outperforms that of state-of-the-art methods, which, conversely, rely on bias labels for validation.
Expecting The Unexpected: Towards Broad Out-Of-Distribution Detection
Aug 22, 2023



Improving the reliability of deployed machine learning systems often involves developing methods to detect out-of-distribution (OOD) inputs. However, existing research often narrowly focuses on samples from classes that are absent from the training set, neglecting other types of plausible distribution shifts. This limitation reduces the applicability of these methods in real-world scenarios, where systems encounter a wide variety of anomalous inputs. In this study, we categorize five distinct types of distribution shifts and critically evaluate the performance of recent OOD detection methods on each of them. We publicly release our benchmark under the name BROAD (Benchmarking Resilience Over Anomaly Diversity). Our findings reveal that while these methods excel in detecting unknown classes, their performance is inconsistent when encountering other types of distribution shifts. In other words, they only reliably detect unexpected inputs that they have been specifically designed to expect. As a first step toward broad OOD detection, we learn a generative model of existing detection scores with a Gaussian mixture. By doing so, we present an ensemble approach that offers a more consistent and comprehensive solution for broad OOD detection, demonstrating superior performance compared to existing methods. Our code to download BROAD and reproduce our experiments is publicly available.
CADet: Fully Self-Supervised Anomaly Detection With Contrastive Learning
Oct 04, 2022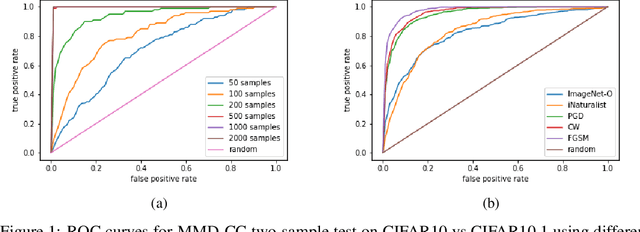
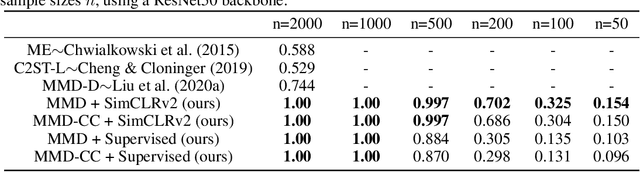

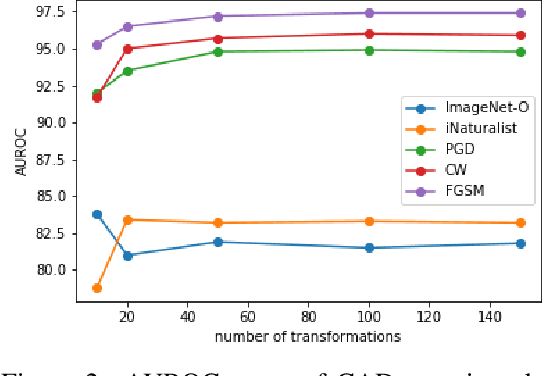
Handling out-of-distribution (OOD) samples has become a major stake in the real-world deployment of machine learning systems. This work explores the application of self-supervised contrastive learning to the simultaneous detection of two types of OOD samples: unseen classes and adversarial perturbations. Since in practice the distribution of such samples is not known in advance, we do not assume access to OOD examples. We show that similarity functions trained with contrastive learning can be leveraged with the maximum mean discrepancy (MMD) two-sample test to verify whether two independent sets of samples are drawn from the same distribution. Inspired by this approach, we introduce CADet (Contrastive Anomaly Detection), a method based on image augmentations to perform anomaly detection on single samples. CADet compares favorably to adversarial detection methods to detect adversarially perturbed samples on ImageNet. Simultaneously, it achieves comparable performance to unseen label detection methods on two challenging benchmarks: ImageNet-O and iNaturalist. CADet is fully self-supervised and requires neither labels for in-distribution samples nor access to OOD examples.
Constraining Representations Yields Models That Know What They Don't Know
Aug 30, 2022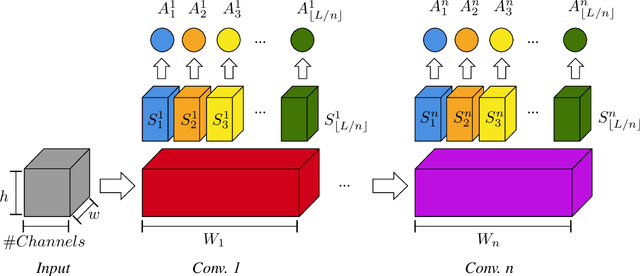

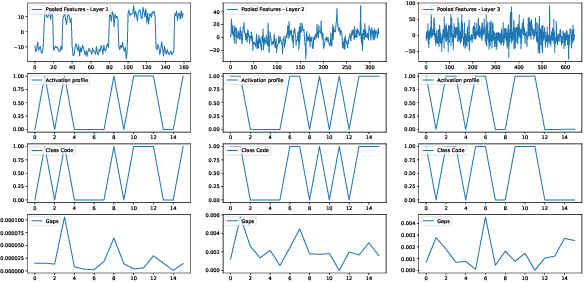
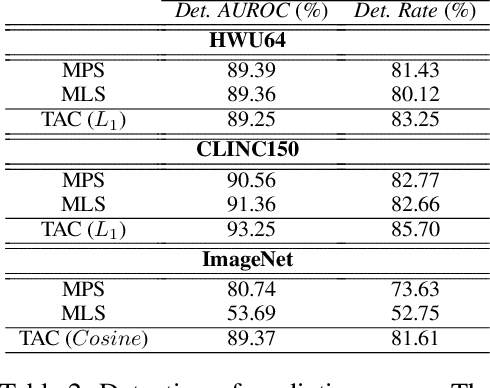
A well-known failure mode of neural networks corresponds to high confidence erroneous predictions, especially for data that somehow differs from the training distribution. Such an unsafe behaviour limits their applicability. To counter that, we show that models offering accurate confidence levels can be defined via adding constraints in their internal representations. That is, we encode class labels as fixed unique binary vectors, or class codes, and use those to enforce class-dependent activation patterns throughout the model. Resulting predictors are dubbed Total Activation Classifiers (TAC), and TAC is used as an additional component to a base classifier to indicate how reliable a prediction is. Given a data instance, TAC slices intermediate representations into disjoint sets and reduces such slices into scalars, yielding activation profiles. During training, activation profiles are pushed towards the code assigned to a given training instance. At testing time, one can predict the class corresponding to the code that best matches the activation profile of an example. Empirically, we observe that the resemblance between activation patterns and their corresponding codes results in an inexpensive unsupervised approach for inducing discriminative confidence scores. Namely, we show that TAC is at least as good as state-of-the-art confidence scores extracted from existing models, while strictly improving the model's value on the rejection setting. TAC was also observed to work well on multiple types of architectures and data modalities.