 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDr-CiK: A Testbed for Foresight-Driven Agents
May 27, 2026Time series forecasting in real-world settings often depends not only on historical observations, but also on external context that must be actively discovered from noisy, heterogeneous information sources. Yet existing context-aided forecasting benchmarks typically assume that the supporting context is already provided, leaving open whether agents can identify it on their own. Therefore, we introduce Dr-CiK, a benchmark for evaluating whether agents can retrieve forecasting-relevant supporting context from a document corpus, filter out distractors, distill the retrieved context into forecast-useful evidence, and generate forecasts supported by that evidence. Through context ablations and evaluations of state-of-the-art deep research and forecasting methods paired together, we show that high-quality context substantially improves forecasting performance in Dr-CiK. However, most existing DR agents recover only a small fraction of the ground-truth supporting evidence (usually <5%), are frequently misled by distractors (>80% distractor citations), and can cause forecasters to perform worse with retrieved context than without context. Our results motivate research on foresight-driven agents that search for the right context to predict the future.
Overcoming the Modality Gap in Context-Aided Forecasting
Mar 16, 2026Context-aided forecasting (CAF) holds promise for integrating domain knowledge and forward-looking information, enabling AI systems to surpass traditional statistical methods. However, recent empirical studies reveal a puzzling gap: multimodal models often fail to outperform their unimodal counterparts. We hypothesize that this underperformance stems from poor context quality in existing datasets, as verification is challenging. To address these limitations, we introduce a semi-synthetic data augmentation method that generates contexts both descriptive of temporal dynamics and verifiably complementary to numerical histories. This approach enables massive-scale dataset creation, resulting in CAF-7M, a corpus of 7 million context-augmented time series windows, including a rigorously verified test set. We demonstrate that semi-synthetic pre-training transfers effectively to real-world evaluation, and show clear evidence of context utilization. Our results suggest that dataset quality, rather than architectural limitations, has been the primary bottleneck in context-aided forecasting.
Bound to Disagree: Generalization Bounds via Certifiable Surrogates
Feb 26, 2026Generalization bounds for deep learning models are typically vacuous, not computable or restricted to specific model classes. In this paper, we tackle these issues by providing new disagreement-based certificates for the gap between the true risk of any two predictors. We then bound the true risk of the predictor of interest via a surrogate model that enjoys tight generalization guarantees, and evaluating our disagreement bound on an unlabeled dataset. We empirically demonstrate the tightness of the obtained certificates and showcase the versatility of the approach by training surrogate models leveraging three different frameworks: sample compression, model compression and PAC-Bayes theory. Importantly, such guarantees are achieved without modifying the target model, nor adapting the training procedure to the generalization framework.
Beyond Naïve Prompting: Strategies for Improved Zero-shot Context-aided Forecasting with LLMs
Aug 13, 2025Forecasting in real-world settings requires models to integrate not only historical data but also relevant contextual information, often available in textual form. While recent work has shown that large language models (LLMs) can be effective context-aided forecasters via na\"ive direct prompting, their full potential remains underexplored. We address this gap with 4 strategies, providing new insights into the zero-shot capabilities of LLMs in this setting. ReDP improves interpretability by eliciting explicit reasoning traces, allowing us to assess the model's reasoning over the context independently from its forecast accuracy. CorDP leverages LLMs solely to refine existing forecasts with context, enhancing their applicability in real-world forecasting pipelines. IC-DP proposes embedding historical examples of context-aided forecasting tasks in the prompt, substantially improving accuracy even for the largest models. Finally, RouteDP optimizes resource efficiency by using LLMs to estimate task difficulty, and routing the most challenging tasks to larger models. Evaluated on different kinds of context-aided forecasting tasks from the CiK benchmark, our strategies demonstrate distinct benefits over na\"ive prompting across LLMs of different sizes and families. These results open the door to further simple yet effective improvements in LLM-based context-aided forecasting.
PairBench: A Systematic Framework for Selecting Reliable Judge VLMs
Feb 21, 2025As large vision language models (VLMs) are increasingly used as automated evaluators, understanding their ability to effectively compare data pairs as instructed in the prompt becomes essential. To address this, we present PairBench, a low-cost framework that systematically evaluates VLMs as customizable similarity tools across various modalities and scenarios. Through PairBench, we introduce four metrics that represent key desiderata of similarity scores: alignment with human annotations, consistency for data pairs irrespective of their order, smoothness of similarity distributions, and controllability through prompting. Our analysis demonstrates that no model, whether closed- or open-source, is superior on all metrics; the optimal choice depends on an auto evaluator's desired behavior (e.g., a smooth vs. a sharp judge), highlighting risks of widespread adoption of VLMs as evaluators without thorough assessment. For instance, the majority of VLMs struggle with maintaining symmetric similarity scores regardless of order. Additionally, our results show that the performance of VLMs on the metrics in PairBench closely correlates with popular benchmarks, showcasing its predictive power in ranking models.
Learning to Defer for Causal Discovery with Imperfect Experts
Feb 18, 2025
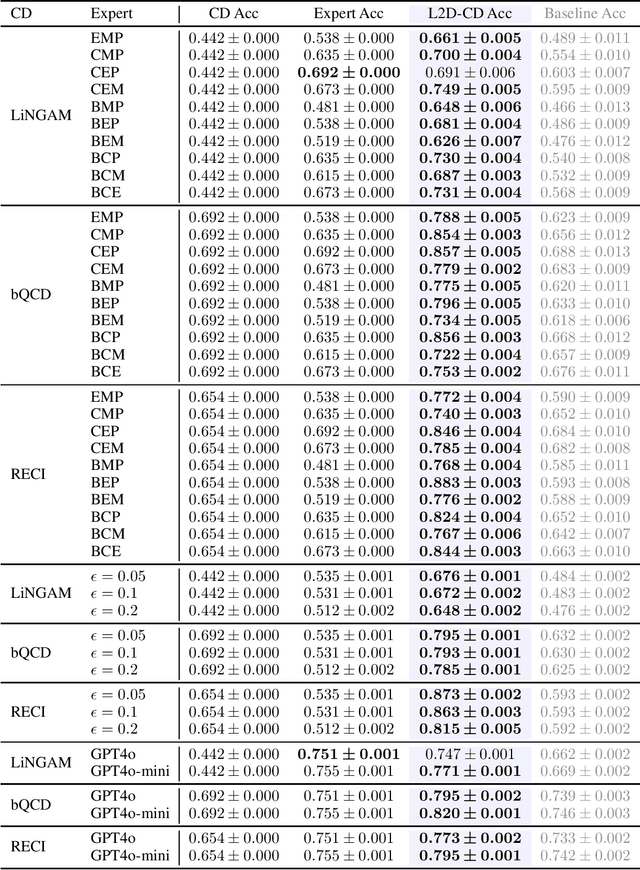
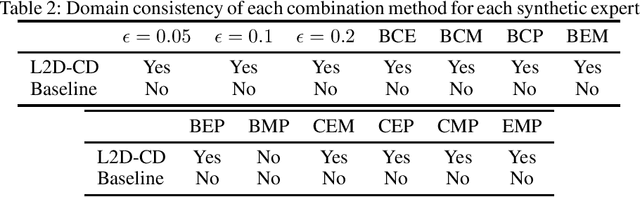
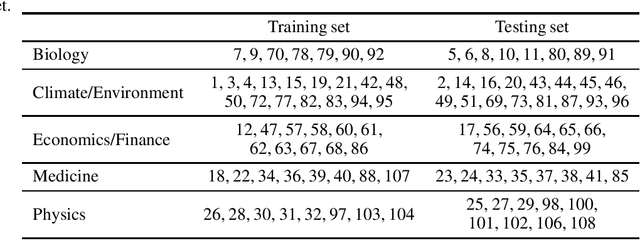
Integrating expert knowledge, e.g. from large language models, into causal discovery algorithms can be challenging when the knowledge is not guaranteed to be correct. Expert recommendations may contradict data-driven results, and their reliability can vary significantly depending on the domain or specific query. Existing methods based on soft constraints or inconsistencies in predicted causal relationships fail to account for these variations in expertise. To remedy this, we propose L2D-CD, a method for gauging the correctness of expert recommendations and optimally combining them with data-driven causal discovery results. By adapting learning-to-defer (L2D) algorithms for pairwise causal discovery (CD), we learn a deferral function that selects whether to rely on classical causal discovery methods using numerical data or expert recommendations based on textual meta-data. We evaluate L2D-CD on the canonical T\"ubingen pairs dataset and demonstrate its superior performance compared to both the causal discovery method and the expert used in isolation. Moreover, our approach identifies domains where the expert's performance is strong or weak. Finally, we outline a strategy for generalizing this approach to causal discovery on graphs with more than two variables, paving the way for further research in this area.
ReTreever: Tree-based Coarse-to-Fine Representations for Retrieval
Feb 11, 2025Document retrieval is a core component of question-answering systems, as it enables conditioning answer generation on new and large-scale corpora. While effective, the standard practice of encoding documents into high-dimensional embeddings for similarity search entails large memory and compute footprints, and also makes it hard to inspect the inner workings of the system. In this paper, we propose a tree-based method for organizing and representing reference documents at various granular levels, which offers the flexibility to balance cost and utility, and eases the inspection of the corpus content and retrieval operations. Our method, called ReTreever, jointly learns a routing function per internal node of a binary tree such that query and reference documents are assigned to similar tree branches, hence directly optimizing for retrieval performance. Our evaluations show that ReTreever generally preserves full representation accuracy. Its hierarchical structure further provides strong coarse representations and enhances transparency by indirectly learning meaningful semantic groupings. Among hierarchical retrieval methods, ReTreever achieves the best retrieval accuracy at the lowest latency, proving that this family of techniques can be viable in practical applications.
Performance Control in Early Exiting to Deploy Large Models at the Same Cost of Smaller Ones
Dec 26, 2024Early Exiting (EE) is a promising technique for speeding up inference by adaptively allocating compute resources to data points based on their difficulty. The approach enables predictions to exit at earlier layers for simpler samples while reserving more computation for challenging ones. In this study, we first present a novel perspective on the EE approach, showing that larger models deployed with EE can achieve higher performance than smaller models while maintaining similar computational costs. As existing EE approaches rely on confidence estimation at each exit point, we further study the impact of overconfidence on the controllability of the compute-performance trade-off. We introduce Performance Control Early Exiting (PCEE), a method that enables accuracy thresholding by basing decisions not on a data point's confidence but on the average accuracy of samples with similar confidence levels from a held-out validation set. In our experiments, we show that PCEE offers a simple yet computationally efficient approach that provides better control over performance than standard confidence-based approaches, and allows us to scale up model sizes to yield performance gain while reducing the computational cost.
Context is Key: A Benchmark for Forecasting with Essential Textual Information
Oct 24, 2024



Forecasting is a critical task in decision making across various domains. While numerical data provides a foundation, it often lacks crucial context necessary for accurate predictions. Human forecasters frequently rely on additional information, such as background knowledge or constraints, which can be efficiently communicated through natural language. However, the ability of existing forecasting models to effectively integrate this textual information remains an open question. To address this, we introduce "Context is Key" (CiK), a time series forecasting benchmark that pairs numerical data with diverse types of carefully crafted textual context, requiring models to integrate both modalities. We evaluate a range of approaches, including statistical models, time series foundation models, and LLM-based forecasters, and propose a simple yet effective LLM prompting method that outperforms all other tested methods on our benchmark. Our experiments highlight the importance of incorporating contextual information, demonstrate surprising performance when using LLM-based forecasting models, and also reveal some of their critical shortcomings. By presenting this benchmark, we aim to advance multimodal forecasting, promoting models that are both accurate and accessible to decision-makers with varied technical expertise. The benchmark can be visualized at https://servicenow.github.io/context-is-key-forecasting/v0/ .
Sample compression unleashed : New generalization bounds for real valued losses
Sep 26, 2024
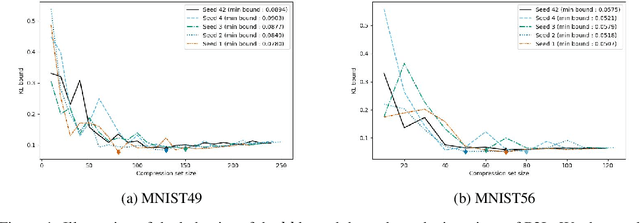

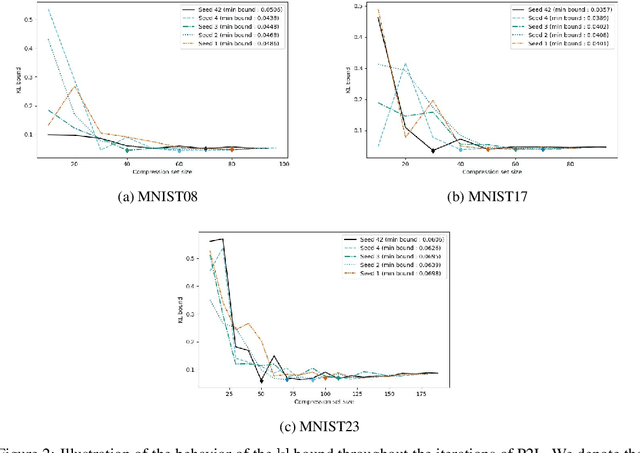
The sample compression theory provides generalization guarantees for predictors that can be fully defined using a subset of the training dataset and a (short) message string, generally defined as a binary sequence. Previous works provided generalization bounds for the zero-one loss, which is restrictive, notably when applied to deep learning approaches. In this paper, we present a general framework for deriving new sample compression bounds that hold for real-valued losses. We empirically demonstrate the tightness of the bounds and their versatility by evaluating them on different types of models, e.g., neural networks and decision forests, trained with the Pick-To-Learn (P2L) meta-algorithm, which transforms the training method of any machine-learning predictor to yield sample-compressed predictors. In contrast to existing P2L bounds, ours are valid in the non-consistent case.