 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBound to Disagree: Generalization Bounds via Certifiable Surrogates
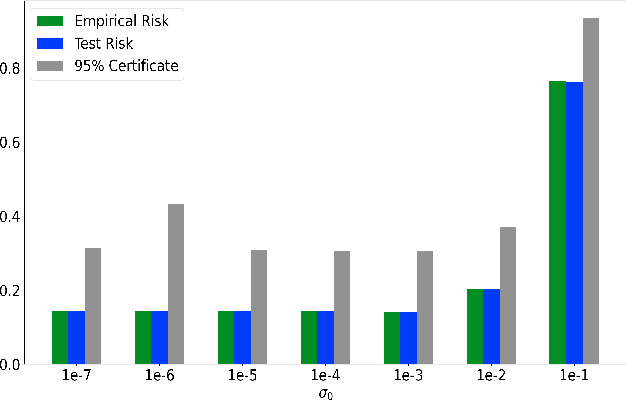
Feb 26, 2026Generalization bounds for deep learning models are typically vacuous, not computable or restricted to specific model classes. In this paper, we tackle these issues by providing new disagreement-based certificates for the gap between the true risk of any two predictors. We then bound the true risk of the predictor of interest via a surrogate model that enjoys tight generalization guarantees, and evaluating our disagreement bound on an unlabeled dataset. We empirically demonstrate the tightness of the obtained certificates and showcase the versatility of the approach by training surrogate models leveraging three different frameworks: sample compression, model compression and PAC-Bayes theory. Importantly, such guarantees are achieved without modifying the target model, nor adapting the training procedure to the generalization framework.
PAC-Bayesian Generalization Guarantees for Fairness on Stochastic and Deterministic Classifiers
Feb 12, 2026Classical PAC generalization bounds on the prediction risk of a classifier are insufficient to provide theoretical guarantees on fairness when the goal is to learn models balancing predictive risk and fairness constraints. We propose a PAC-Bayesian framework for deriving generalization bounds for fairness, covering both stochastic and deterministic classifiers. For stochastic classifiers, we derive a fairness bound using standard PAC-Bayes techniques. Whereas for deterministic classifiers, as usual PAC-Bayes arguments do not apply directly, we leverage a recent advance in PAC-Bayes to extend the fairness bound beyond the stochastic setting. Our framework has two advantages: (i) It applies to a broad class of fairness measures that can be expressed as a risk discrepancy, and (ii) it leads to a self-bounding algorithm in which the learning procedure directly optimizes a trade-off between generalization bounds on the prediction risk and on the fairness. We empirically evaluate our framework with three classical fairness measures, demonstrating not only its usefulness but also the tightness of our bounds.
Sample Compression for Continual Learning
Mar 13, 2025Continual learning algorithms aim to learn from a sequence of tasks, making the training distribution non-stationary. The majority of existing continual learning approaches in the literature rely on heuristics and do not provide learning guarantees for the continual learning setup. In this paper, we present a new method called 'Continual Pick-to-Learn' (CoP2L), which is able to retain the most representative samples for each task in an efficient way. The algorithm is adapted from the Pick-to-Learn algorithm, rooted in the sample compression theory. This allows us to provide high-confidence upper bounds on the generalization loss of the learned predictors, numerically computable after every update of the learned model. We also empirically show on several standard continual learning benchmarks that our algorithm is able to outperform standard experience replay, significantly mitigating catastrophic forgetting.
Sample Compression Hypernetworks: From Generalization Bounds to Meta-Learning
Oct 17, 2024Reconstruction functions are pivotal in sample compression theory, a framework for deriving tight generalization bounds. From a small sample of the training set (the compression set) and an optional stream of information (the message), they recover a predictor previously learned from the whole training set. While usually fixed, we propose to learn reconstruction functions. To facilitate the optimization and increase the expressiveness of the message, we derive a new sample compression generalization bound for real-valued messages. From this theoretical analysis, we then present a new hypernetwork architecture that outputs predictors with tight generalization guarantees when trained using an original meta-learning framework. The results of promising preliminary experiments are then reported.
Sample compression unleashed : New generalization bounds for real valued losses
Sep 26, 2024
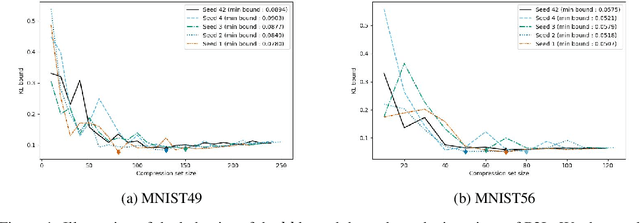

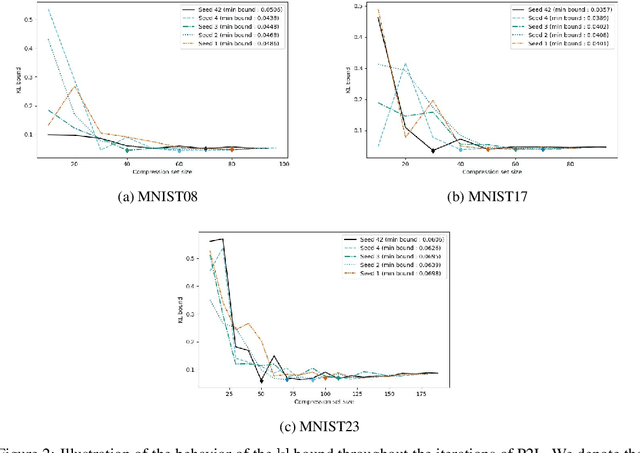
The sample compression theory provides generalization guarantees for predictors that can be fully defined using a subset of the training dataset and a (short) message string, generally defined as a binary sequence. Previous works provided generalization bounds for the zero-one loss, which is restrictive, notably when applied to deep learning approaches. In this paper, we present a general framework for deriving new sample compression bounds that hold for real-valued losses. We empirically demonstrate the tightness of the bounds and their versatility by evaluating them on different types of models, e.g., neural networks and decision forests, trained with the Pick-To-Learn (P2L) meta-algorithm, which transforms the training method of any machine-learning predictor to yield sample-compressed predictors. In contrast to existing P2L bounds, ours are valid in the non-consistent case.
Phoneme Discretized Saliency Maps for Explainable Detection of AI-Generated Voice
Jun 14, 2024



In this paper, we propose Phoneme Discretized Saliency Maps (PDSM), a discretization algorithm for saliency maps that takes advantage of phoneme boundaries for explainable detection of AI-generated voice. We experimentally show with two different Text-to-Speech systems (i.e., Tacotron2 and Fastspeech2) that the proposed algorithm produces saliency maps that result in more faithful explanations compared to standard posthoc explanation methods. Moreover, by associating the saliency maps to the phoneme representations, this methodology generates explanations that tend to be more understandable than standard saliency maps on magnitude spectrograms.
Interpretability in Machine Learning: on the Interplay with Explainability, Predictive Performances and Models
Nov 20, 2023Interpretability has recently gained attention in the field of machine learning, for it is crucial when it comes to high-stakes decisions or troubleshooting. This abstract concept is hard to grasp and has been associated, over time, with many labels and preconceived ideas. In this position paper, in order to clarify some misunderstandings regarding interpretability, we discuss its relationship with significant concepts in machine learning: explainability, predictive performances, and machine learning models. For instance, we challenge the idea that interpretability and explainability are substitutes to one another, or that a fixed degree of interpretability can be associated with a given machine learning model.
Statistical Guarantees for Variational Autoencoders using PAC-Bayesian Theory
Oct 07, 2023
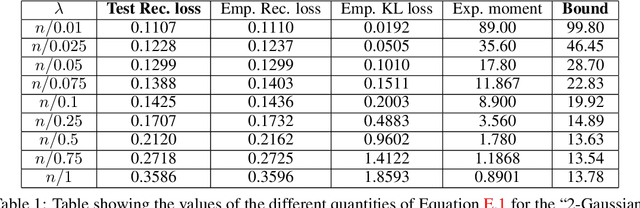
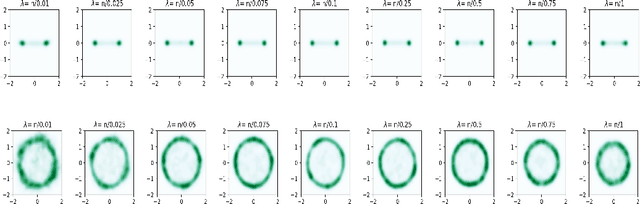
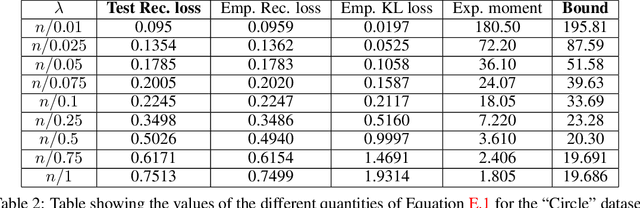
Since their inception, Variational Autoencoders (VAEs) have become central in machine learning. Despite their widespread use, numerous questions regarding their theoretical properties remain open. Using PAC-Bayesian theory, this work develops statistical guarantees for VAEs. First, we derive the first PAC-Bayesian bound for posterior distributions conditioned on individual samples from the data-generating distribution. Then, we utilize this result to develop generalization guarantees for the VAE's reconstruction loss, as well as upper bounds on the distance between the input and the regenerated distributions. More importantly, we provide upper bounds on the Wasserstein distance between the input distribution and the distribution defined by the VAE's generative model.
Invariant Causal Set Covering Machines
Jun 07, 2023
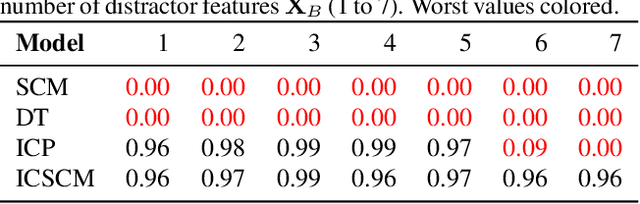

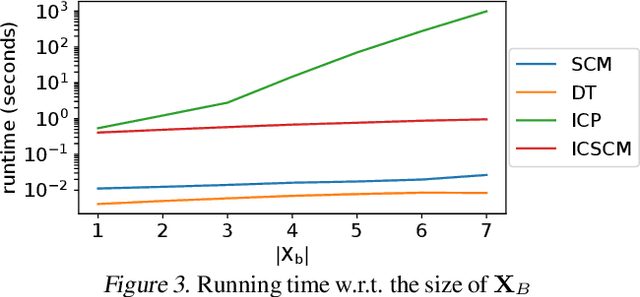
Rule-based models, such as decision trees, appeal to practitioners due to their interpretable nature. However, the learning algorithms that produce such models are often vulnerable to spurious associations and thus, they are not guaranteed to extract causally-relevant insights. In this work, we build on ideas from the invariant causal prediction literature to propose Invariant Causal Set Covering Machines, an extension of the classical Set Covering Machine algorithm for conjunctions/disjunctions of binary-valued rules that provably avoids spurious associations. We demonstrate both theoretically and empirically that our method can identify the causal parents of a variable of interest in polynomial time.
PAC-Bayesian Generalization Bounds for Adversarial Generative Models
Feb 17, 2023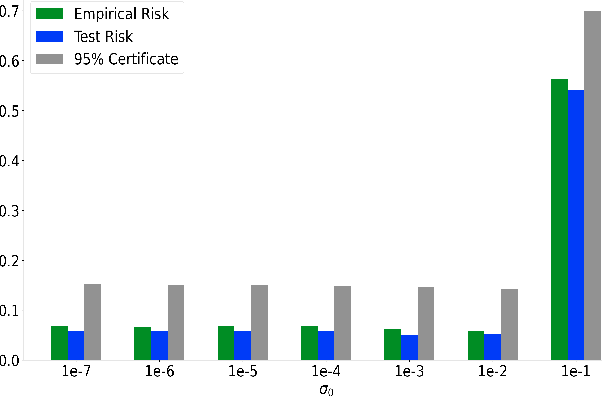
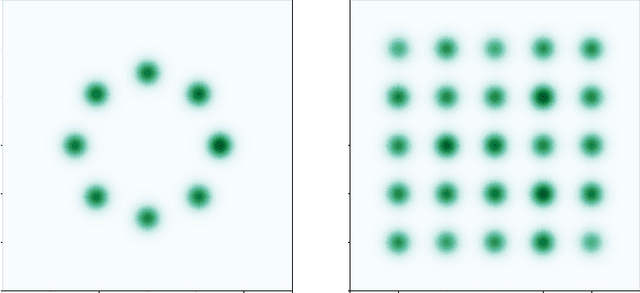

We extend PAC-Bayesian theory to generative models and develop generalization bounds for models based on the Wasserstein distance and the total variation distance. Our first result on the Wasserstein distance assumes the instance space is bounded, while our second result takes advantage of dimensionality reduction. Our results naturally apply to Wasserstein GANs and Energy-Based GANs, and our bounds provide new training objectives for these two. Although our work is mainly theoretical, we perform numerical experiments showing non-vacuous generalization bounds for Wasserstein GANs on synthetic datasets.