 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimplicity Suffices for Parameter Noise Injection in Stochastic Gradient Descent
Jun 10, 2026Injecting noise into the optimization process is a well-established technique for improving the training and generalization of deep neural networks. Yet, despite the breadth of existing approaches, it remains unclear which design choices truly matter in practice. In this work, we investigate parameter noise injection for stochastic gradient descent, focusing on two key questions: how to efficiently pair each training example with its own perturbation in mini-batch training, and whether sophisticated noise parameterizations or multi-sample gradient averaging yield meaningful gains over simpler alternatives. To address the first question, we leverage a distributional identity for linear layers that allows per-example noise injection without breaking batched computation. To address the second, we systematically compare several diagonal Gaussian parameterizations against an isotropic baseline across varying noise levels on CIFAR100. Our results consistently show that simple, lightweight strategies, isotropic noise with a single perturbed forward pass per update step, recover most of the benefit of more complex schemes. These findings suggest that simplicity suffices for parameter noise injection, and that practitioners need not resort to elaborate perturbation designs to reap the optimization and generalization benefits of noisy SGD.
PAC-Bayesian Generalization Guarantees for Fairness on Stochastic and Deterministic Classifiers
Feb 12, 2026Classical PAC generalization bounds on the prediction risk of a classifier are insufficient to provide theoretical guarantees on fairness when the goal is to learn models balancing predictive risk and fairness constraints. We propose a PAC-Bayesian framework for deriving generalization bounds for fairness, covering both stochastic and deterministic classifiers. For stochastic classifiers, we derive a fairness bound using standard PAC-Bayes techniques. Whereas for deterministic classifiers, as usual PAC-Bayes arguments do not apply directly, we leverage a recent advance in PAC-Bayes to extend the fairness bound beyond the stochastic setting. Our framework has two advantages: (i) It applies to a broad class of fairness measures that can be expressed as a risk discrepancy, and (ii) it leads to a self-bounding algorithm in which the learning procedure directly optimizes a trade-off between generalization bounds on the prediction risk and on the fairness. We empirically evaluate our framework with three classical fairness measures, demonstrating not only its usefulness but also the tightness of our bounds.
Sample Compression Hypernetworks: From Generalization Bounds to Meta-Learning
Oct 17, 2024Reconstruction functions are pivotal in sample compression theory, a framework for deriving tight generalization bounds. From a small sample of the training set (the compression set) and an optional stream of information (the message), they recover a predictor previously learned from the whole training set. While usually fixed, we propose to learn reconstruction functions. To facilitate the optimization and increase the expressiveness of the message, we derive a new sample compression generalization bound for real-valued messages. From this theoretical analysis, we then present a new hypernetwork architecture that outputs predictors with tight generalization guarantees when trained using an original meta-learning framework. The results of promising preliminary experiments are then reported.
Interpretability in Machine Learning: on the Interplay with Explainability, Predictive Performances and Models
Nov 20, 2023Interpretability has recently gained attention in the field of machine learning, for it is crucial when it comes to high-stakes decisions or troubleshooting. This abstract concept is hard to grasp and has been associated, over time, with many labels and preconceived ideas. In this position paper, in order to clarify some misunderstandings regarding interpretability, we discuss its relationship with significant concepts in machine learning: explainability, predictive performances, and machine learning models. For instance, we challenge the idea that interpretability and explainability are substitutes to one another, or that a fixed degree of interpretability can be associated with a given machine learning model.
A Greedy Algorithm for Building Compact Binary Activated Neural Networks
Sep 07, 2022


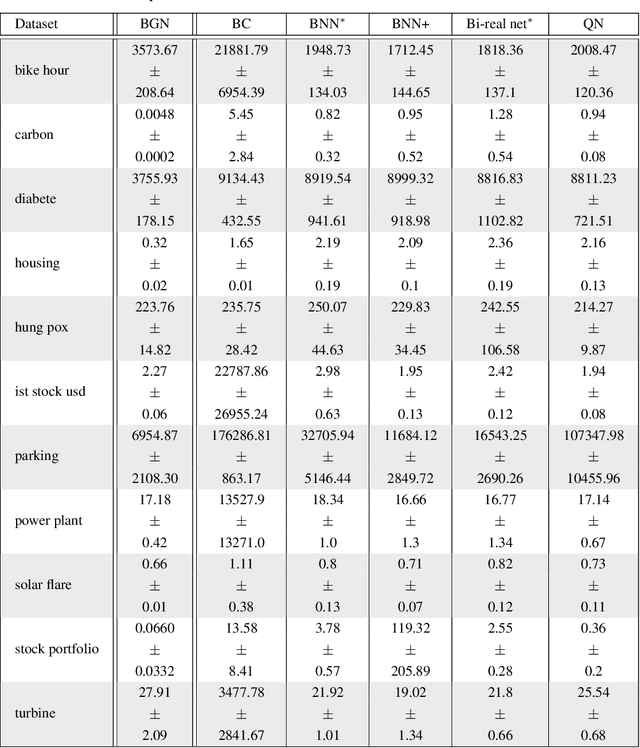
We study binary activated neural networks in the context of regression tasks, provide guarantees on the expressiveness of these particular networks and propose a greedy algorithm for building such networks. Aiming for predictors having small resources needs, the greedy approach does not need to fix in advance an architecture for the network: this one is built one layer at a time, one neuron at a time, leading to predictors that aren't needlessly wide and deep for a given task. Similarly to boosting algorithms, our approach guarantees a training loss reduction every time a neuron is added to a layer. This greatly differs from most binary activated neural networks training schemes that rely on stochastic gradient descent (circumventing the 0-almost-everywhere derivative problem of the binary activation function by surrogates such as the straight through estimator or continuous binarization). We show that our method provides compact and sparse predictors while obtaining similar performances to state-of-the-art methods for training binary activated networks.
Learning Aggregations of Binary Activated Neural Networks with Probabilities over Representations
Oct 29, 2021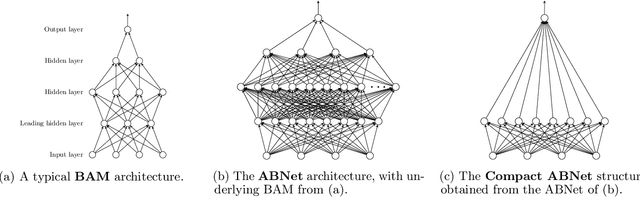
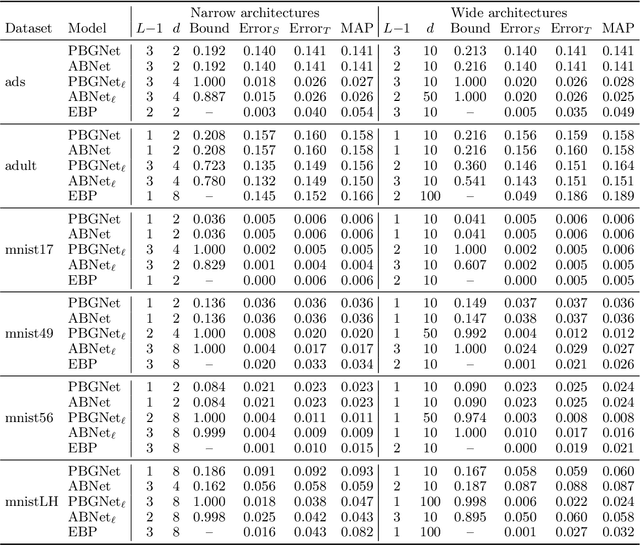
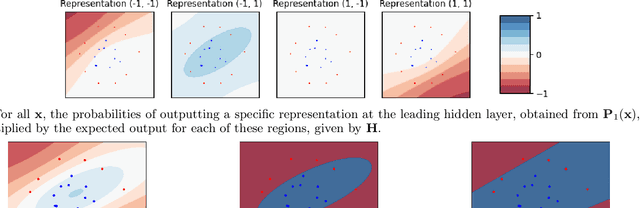
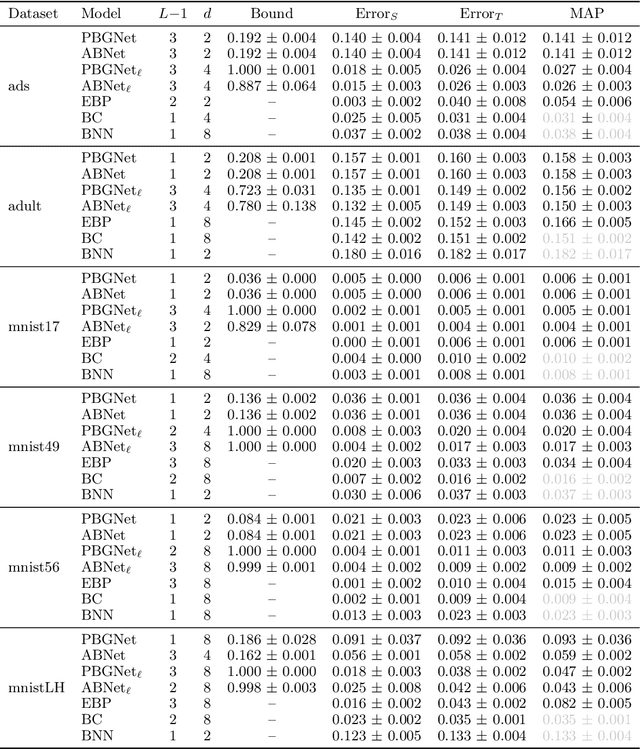
Considering a probability distribution over parameters is known as an efficient strategy to learn a neural network with non-differentiable activation functions. We study the expectation of a probabilistic neural network as a predictor by itself, focusing on the aggregation of binary activated neural networks with normal distributions over real-valued weights. Our work leverages a recent analysis derived from the PAC-Bayesian framework that derives tight generalization bounds and learning procedures for the expected output value of such an aggregation, which is given by an analytical expression. While the combinatorial nature of the latter has been circumvented by approximations in previous works, we show that the exact computation remains tractable for deep but narrow neural networks, thanks to a dynamic programming approach. This leads us to a peculiar bound minimization learning algorithm for binary activated neural networks, where the forward pass propagates probabilities over representations instead of activation values. A stochastic counterpart of this new neural networks training scheme that scales to wider architectures is proposed.