 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultinational Address Parsing: A Zero-Shot Evaluation
Dec 07, 2021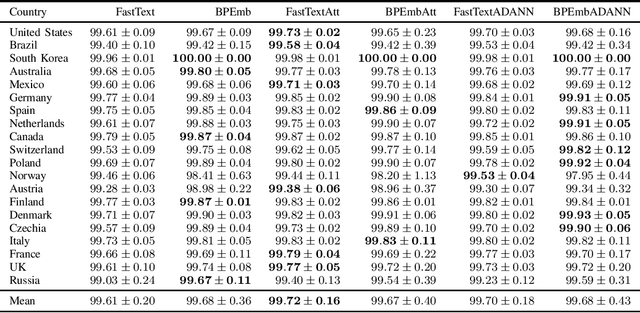
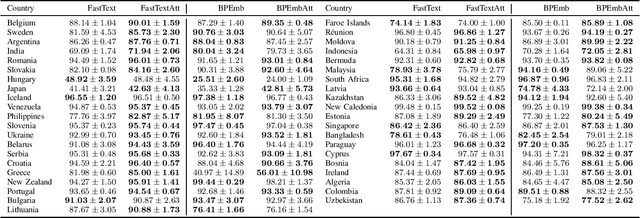
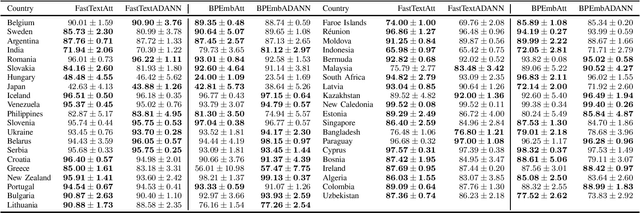
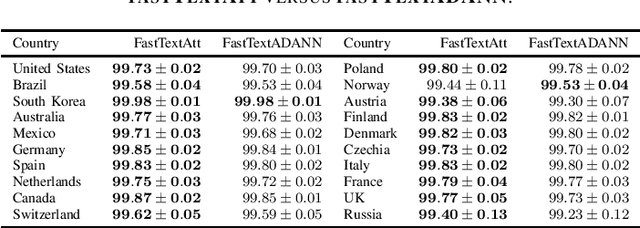
Address parsing consists of identifying the segments that make up an address, such as a street name or a postal code. Because of its importance for tasks like record linkage, address parsing has been approached with many techniques, the latest relying on neural networks. While these models yield notable results, previous work on neural networks has only focused on parsing addresses from a single source country. This paper explores the possibility of transferring the address parsing knowledge acquired by training deep learning models on some countries' addresses to others with no further training in a zero-shot transfer learning setting. We also experiment using an attention mechanism and a domain adversarial training algorithm in the same zero-shot transfer setting to improve performance. Both methods yield state-of-the-art performance for most of the tested countries while giving good results to the remaining countries. We also explore the effect of incomplete addresses on our best model, and we evaluate the impact of using incomplete addresses during training. In addition, we propose an open-source Python implementation of some of our trained models.
Learning Aggregations of Binary Activated Neural Networks with Probabilities over Representations
Oct 29, 2021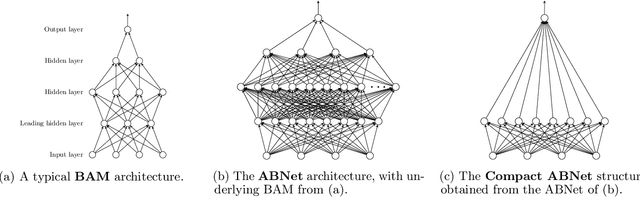
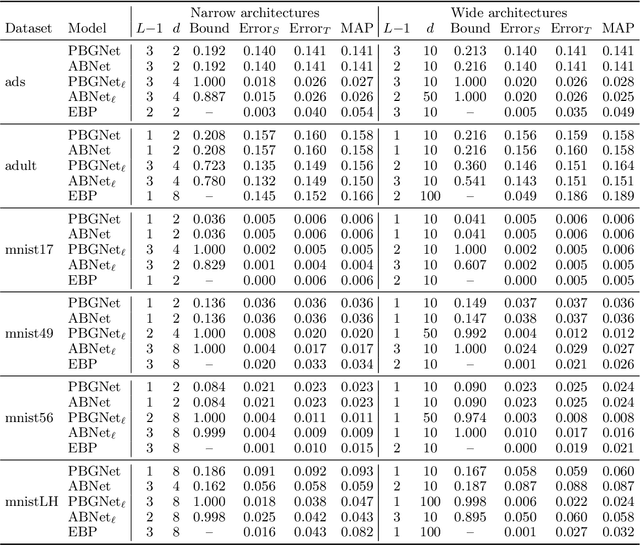
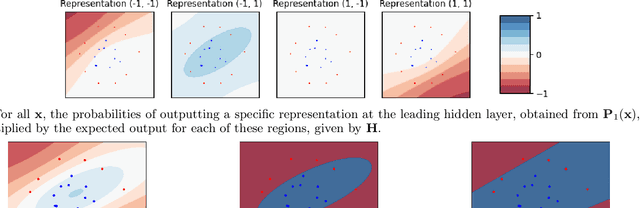
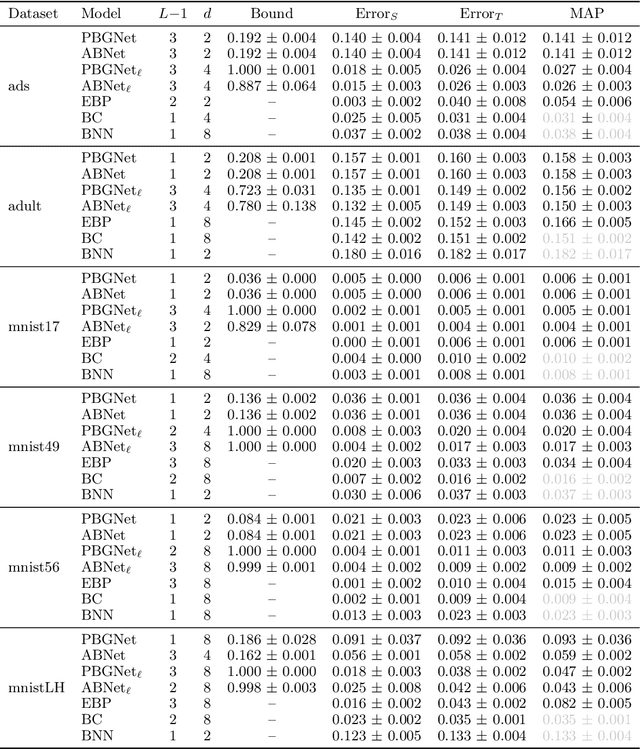
Considering a probability distribution over parameters is known as an efficient strategy to learn a neural network with non-differentiable activation functions. We study the expectation of a probabilistic neural network as a predictor by itself, focusing on the aggregation of binary activated neural networks with normal distributions over real-valued weights. Our work leverages a recent analysis derived from the PAC-Bayesian framework that derives tight generalization bounds and learning procedures for the expected output value of such an aggregation, which is given by an analytical expression. While the combinatorial nature of the latter has been circumvented by approximations in previous works, we show that the exact computation remains tractable for deep but narrow neural networks, thanks to a dynamic programming approach. This leads us to a peculiar bound minimization learning algorithm for binary activated neural networks, where the forward pass propagates probabilities over representations instead of activation values. A stochastic counterpart of this new neural networks training scheme that scales to wider architectures is proposed.
How to Certify Machine Learning Based Safety-critical Systems? A Systematic Literature Review
Aug 03, 2021
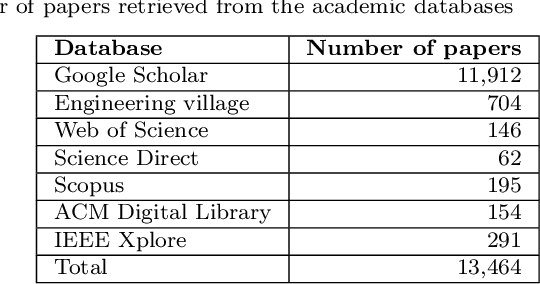

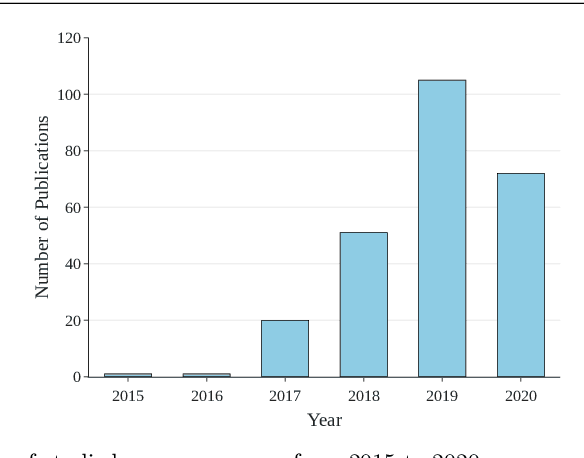
Context: Machine Learning (ML) has been at the heart of many innovations over the past years. However, including it in so-called 'safety-critical' systems such as automotive or aeronautic has proven to be very challenging, since the shift in paradigm that ML brings completely changes traditional certification approaches. Objective: This paper aims to elucidate challenges related to the certification of ML-based safety-critical systems, as well as the solutions that are proposed in the literature to tackle them, answering the question 'How to Certify Machine Learning Based Safety-critical Systems?'. Method: We conduct a Systematic Literature Review (SLR) of research papers published between 2015 to 2020, covering topics related to the certification of ML systems. In total, we identified 217 papers covering topics considered to be the main pillars of ML certification: Robustness, Uncertainty, Explainability, Verification, Safe Reinforcement Learning, and Direct Certification. We analyzed the main trends and problems of each sub-field and provided summaries of the papers extracted. Results: The SLR results highlighted the enthusiasm of the community for this subject, as well as the lack of diversity in terms of datasets and type of models. It also emphasized the need to further develop connections between academia and industries to deepen the domain study. Finally, it also illustrated the necessity to build connections between the above mention main pillars that are for now mainly studied separately. Conclusion: We highlighted current efforts deployed to enable the certification of ML based software systems, and discuss some future research directions.
Implicit Variational Inference: the Parameter and the Predictor Space
Oct 24, 2020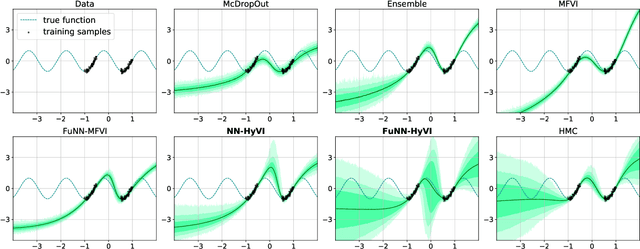
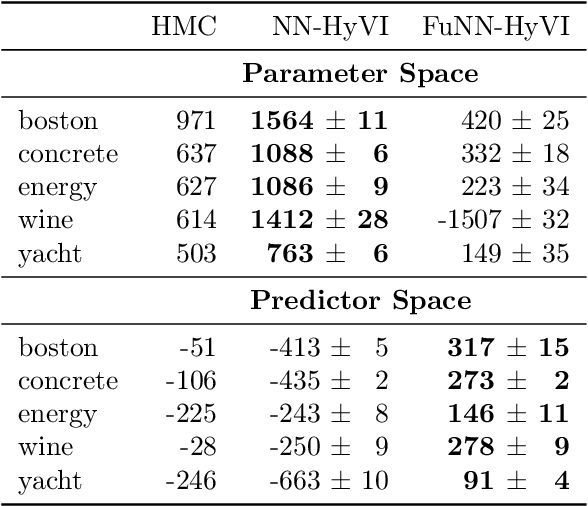
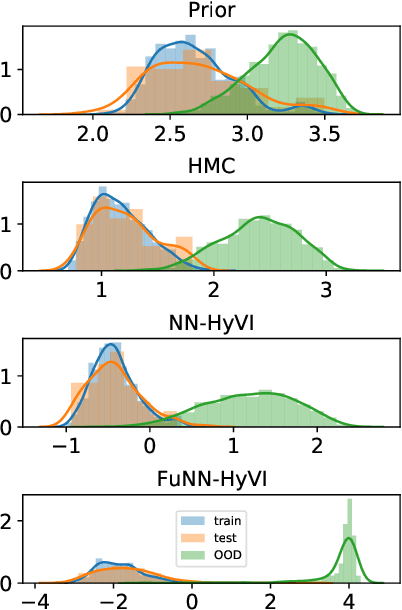
Having access to accurate confidence levels along with the predictions allows to determine whether making a decision is worth the risk. Under the Bayesian paradigm, the posterior distribution over parameters is used to capture model uncertainty, a valuable information that can be translated into predictive uncertainty. However, computing the posterior distribution for high capacity predictors, such as neural networks, is generally intractable, making approximate methods such as variational inference a promising alternative. While most methods perform inference in the space of parameters, we explore the benefits of carrying inference directly in the space of predictors. Relying on a family of distributions given by a deep generative neural network, we present two ways of carrying variational inference: one in \emph{parameter space}, one in \emph{predictor space}. Importantly, the latter requires us to choose a distribution of inputs, therefore allowing us at the same time to explicitly address the question of \emph{out-of-distribution} uncertainty. We explore from various perspectives the implications of working in the predictor space induced by neural networks as opposed to the parameter space, focusing mainly on the quality of uncertainty estimation for data lying outside of the training distribution. We compare posterior approximations obtained with these two methods to several standard methods and present results showing that variational approximations learned in the predictor space distinguish themselves positively from those trained in the parameter space.
Leveraging Subword Embeddings for Multinational Address Parsing
Jun 29, 2020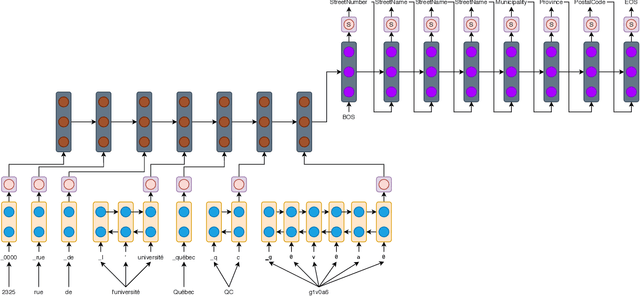
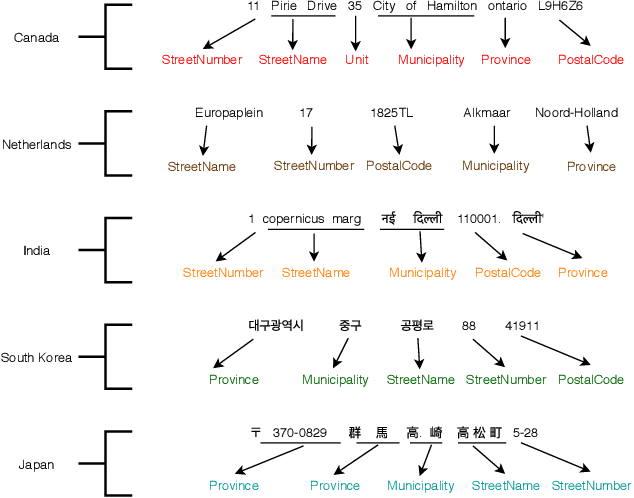


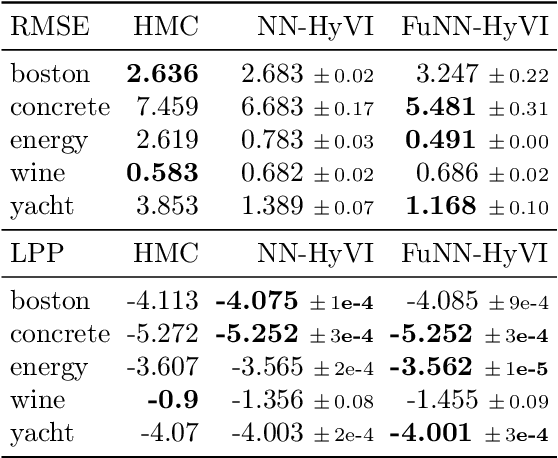
Address parsing consists of identifying the segments that make up an address such as a street name or a postal code. Because of its importance for tasks like record linkage, address parsing has been approached with many techniques. Neural network methods defined a new state-of-the-art for address parsing. While this approach yielded notable results, previous work has only focused on applying neural networks to achieve address parsing of addresses from one source country. We propose an approach in which we employ subword embeddings and a Recurrent Neural Network architecture to build a single model capable of learning to parse addresses from multiple countries at the same time while taking into account the difference in languages and address formatting systems. We achieved accuracies around 99 % on the countries used for training with no pre-processing nor post-processing needed. In addition, we explore the possibility of transferring the address parsing knowledge attained by training on some countries' addresses to others with no further training. This setting is also called zero-shot transfer learning. We achieve good results for 80 % of the countries (34 out of 41), almost 50 % of which (19 out of 41) is near state-of-the-art performance.
Unsupervised Domain Adversarial Self-Calibration for Electromyographic-based Gesture Recognition
Dec 21, 2019
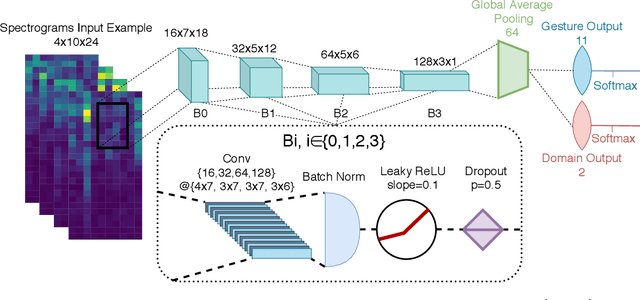
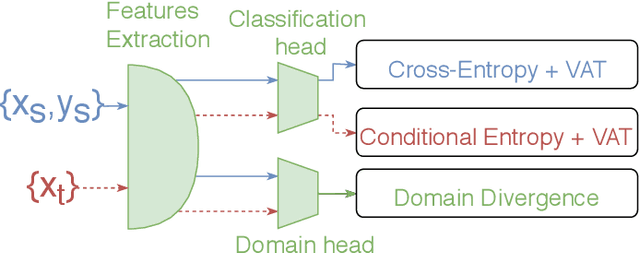
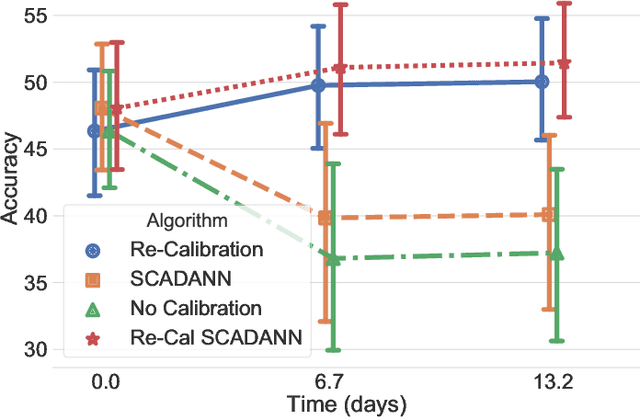
Surface electromyography (sEMG) provides an intuitive and non-invasive interface from which to control machines. However, preserving the myoelectric control system's performance over multiple days is challenging, due to the transient nature of this recording technique. In practice, if the system is to remain usable, a time-consuming and periodic re-calibration is necessary. In the case where the sEMG interface is employed every few days, the user might need to do this re-calibration before every use. Thus, severely limiting the practicality of such a control method. Consequently, this paper proposes tackling the especially challenging task of adapting to sEMG signals when multiple days have elapsed between each recording, by presenting SCADANN, a new, deep learning-based, self-calibrating algorithm. SCADANN is ranked against three state of the art domain adversarial algorithms and a multiple-vote self-calibrating algorithm on both offline and online datasets. Overall, SCADANN is shown to systematically improve classifiers' performance over no adaptation and ranks first on almost all the cases tested.
Virtual Reality to Study the Gap Between Offline and Real-Time EMG-based Gesture Recognition
Dec 16, 2019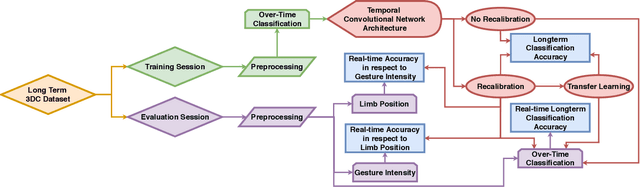
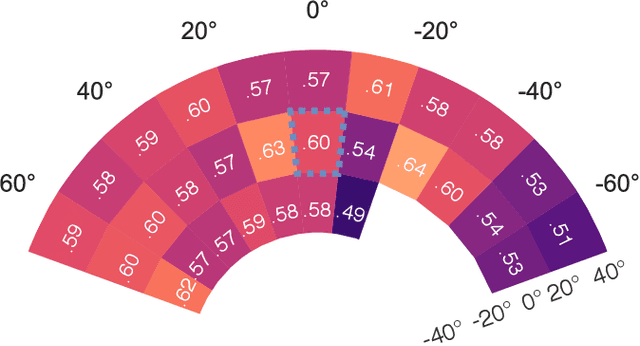
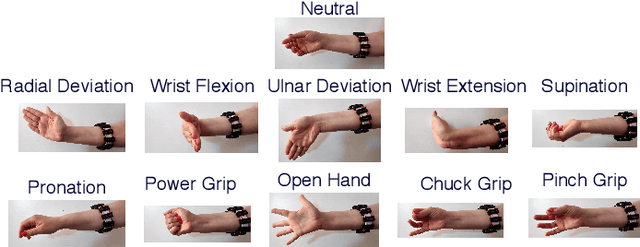
Within sEMG-based gesture recognition, a chasm exists in the literature between offline accuracy and real-time usability of a classifier. This gap mainly stems from the four main dynamic factors in sEMG-based gesture recognition: gesture intensity, limb position, electrode shift and transient changes in the signal. These factors are hard to include within an offline dataset as each of them exponentially augment the number of segments to be recorded. On the other hand, online datasets are biased towards the sEMG-based algorithms providing feedback to the participants, limiting the usability of such datasets as benchmarks. This paper proposes a virtual reality (VR) environment and a real-time experimental protocol from which the four main dynamic factors can more easily be studied. During the online experiment, the gesture recognition feedback is provided through the leap motion camera, enabling the proposed dataset to be re-used to compare future sEMG-based algorithms. 20 able-bodied persons took part in this study, completing three to four sessions over a period spanning between 14 and 21 days. Finally, TADANN, a new transfer learning-based algorithm, is proposed for long term gesture classification and significantly (p<0.05) outperforms fine-tuning a network.
Interpreting Deep Learning Features for Myoelectric Control: A Comparison with Handcrafted Features
Nov 30, 2019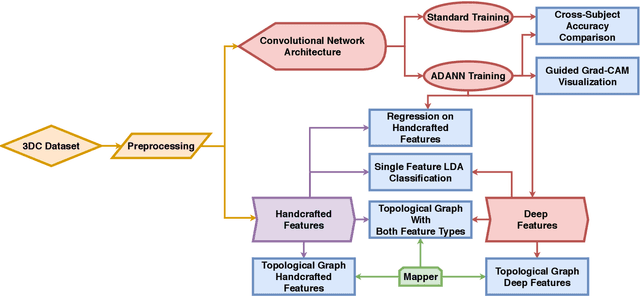
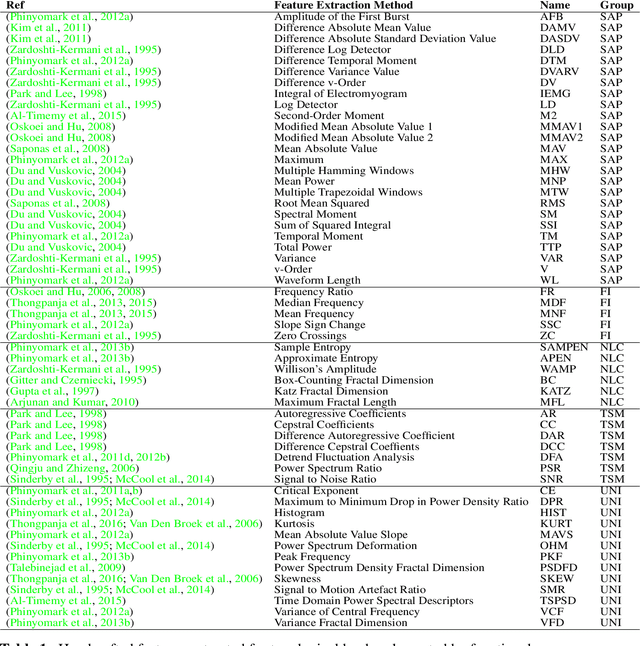


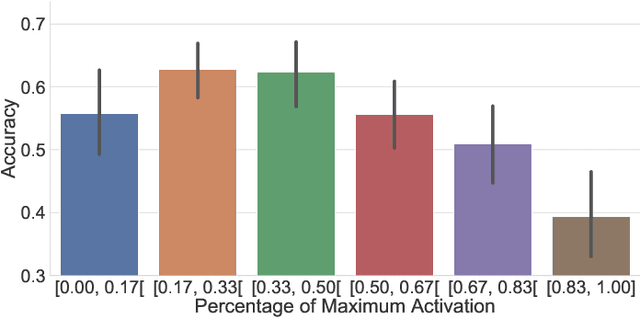
The research in myoelectric control systems primarily focuses on extracting discriminative representations from the electromyographic (EMG) signal by designing handcrafted features. Recently, deep learning techniques have been applied to the challenging task of EMG-based gesture recognition. The adoption of these techniques slowly shifts the focus from feature engineering to feature learning. However, the black-box nature of deep learning makes it hard to understand the type of information learned by the network and how it relates to handcrafted features. Additionally, due to the high variability in EMG recordings between participants, deep features tend to generalize poorly across subjects using standard training methods. Consequently, this work introduces a new multi-domain learning algorithm, named ADANN, which significantly enhances (p=0.00004) inter-subject classification accuracy by an average of 19.40\% compared to standard training. Using ADANN-generated features, the main contribution of this work is to provide the first topological data analysis of EMG-based gesture recognition for the characterisation of the information encoded within a deep network, using handcrafted features as landmarks. This analysis reveals that handcrafted features and the learned features (in the earlier layers) both try to discriminate between all gestures, but do not encode the same information to do so. Furthermore, using convolutional network visualization techniques reveal that learned features tend to ignore the most activated channel during gesture contraction, which is in stark contrast with the prevalence of handcrafted features designed to capture amplitude information. Overall, this work paves the way for hybrid feature sets by providing a clear guideline of complementary information encoded within learned and handcrafted features.
Dichotomize and Generalize: PAC-Bayesian Binary Activated Deep Neural Networks
May 29, 2019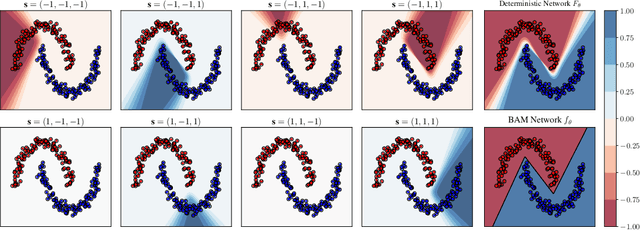
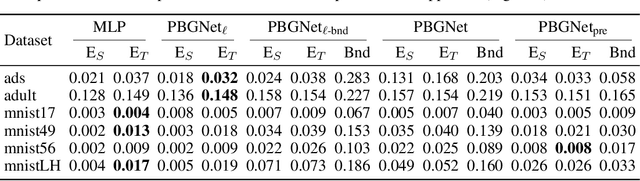
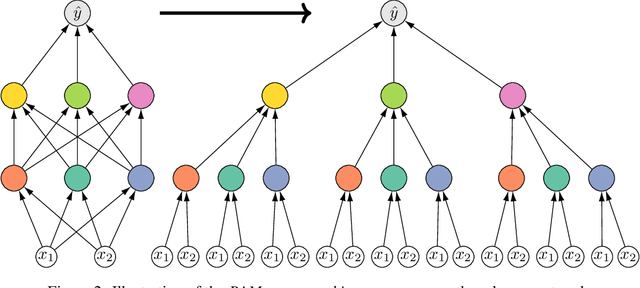
We present a comprehensive study of multilayer neural networks with binary activation, relying on the PAC-Bayesian theory. Our contributions are twofold: (i) we develop an end-to-end framework to train a binary activated deep neural network, overcoming the fact that binary activation function is non-differentiable; (ii) we provide nonvacuous PAC-Bayesian generalization bounds for binary activated deep neural networks. Noteworthy, our results are obtained by minimizing the expected loss of an architecture-dependent aggregation of binary activated deep neural networks. The performance of our approach is assessed on a thorough numerical experiment protocol on real-life datasets.
Deep Learning for Electromyographic Hand Gesture Signal Classification Using Transfer Learning
Jun 12, 2018
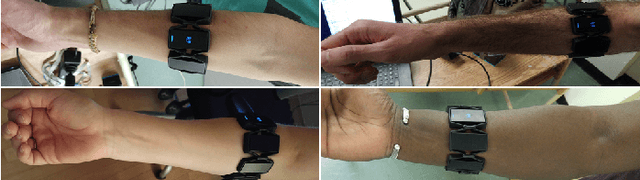
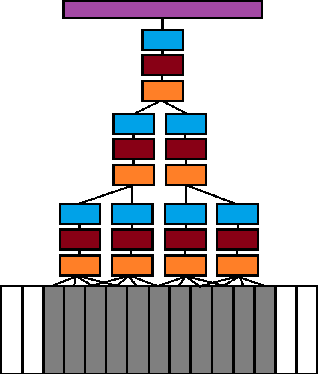
In recent years, the use of deep learning algorithms has become increasingly more prominent for their unparalleled ability to automatically learn discriminant features from large amounts of data. However, within the field of electromyography-based gesture recognition, deep learning algorithms are seldom employed as it requires an unreasonable amount of time for a single person, in a single session, to generate tens of thousands of examples. This work's hypothesis is that general, informative features can be learned from the large amount of data generated by aggregating the signals of multiple users, thus reducing the recording burden imposed on a single person while enhancing gesture recognition. As such, this paper proposes applying transfer learning on the aggregated data of multiple users, while leveraging the capacity of deep learning algorithms to learn discriminant features from large dataset, without the need for in-depth feature engineering. To this end, two datasets are recorded with the Myo Armband (Thalmic Labs), a low-cost, low-sampling rate (200Hz), 8-channel, consumer-grade, dry electrode sEMG armband. These two datasets are comprised of 19 and 17 able-bodied participants respectively. A third dataset, also recorded with the Myo Armband, was taken from the NinaPro database and is comprised of 10 able-bodied participants. This transfer learning scheme is shown to outperform the current state-of-the-art in gesture recognition. It achieves an average accuracy of 98.31% for 7 hand/wrist gestures over 17 able-bodied participants and 65.57% for 18 hand/wrist gestures over 10 able-bodied participants. Finally, a use-case study employing eight able-bodied participants suggests that real-time feedback reduces the degradation in accuracy normally experienced over time.