 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing Programming Task Difficulty for Efficient Evaluation of Large Language Models
Jul 30, 2024



Large Language Models (LLMs) show promising potential in Software Engineering, especially for code-related tasks like code completion and code generation. LLMs' evaluation is generally centred around general metrics computed over benchmarks. While painting a macroscopic view of the benchmarks and of the LLMs' capacity, it is unclear how each programming task in these benchmarks assesses the capabilities of the LLMs. In particular, the difficulty level of the tasks in the benchmarks is not reflected in the score used to report the performance of the model. Yet, a model achieving a 90% score on a benchmark of predominantly easy tasks is likely less capable than a model achieving a 90% score on a benchmark containing predominantly difficult tasks. This paper devises a framework, HardEval, for assessing task difficulty for LLMs and crafting new tasks based on identified hard tasks. The framework uses a diverse array of prompts for a single task across multiple LLMs to obtain a difficulty score for each task of a benchmark. Using two code generation benchmarks, HumanEval+ and ClassEval, we show that HardEval can reliably identify the hard tasks within those benchmarks, highlighting that only 21% of HumanEval+ and 27% of ClassEval tasks are hard for LLMs. Through our analysis of task difficulty, we also characterize 6 practical hard task topics which we used to generate new hard tasks. Orthogonal to current benchmarking evaluation efforts, HardEval can assist researchers and practitioners in fostering better assessments of LLMs. The difficulty score can be used to identify hard tasks within existing benchmarks. This, in turn, can be leveraged to generate more hard tasks centred around specific topics either for evaluation or improvement of LLMs. HardEval generalistic approach can be applied to other domains such as code completion or Q/A.
Chain of Targeted Verification Questions to Improve the Reliability of Code Generated by LLMs
May 22, 2024



LLM-based assistants, such as GitHub Copilot and ChatGPT, have the potential to generate code that fulfills a programming task described in a natural language description, referred to as a prompt. The widespread accessibility of these assistants enables users with diverse backgrounds to generate code and integrate it into software projects. However, studies show that code generated by LLMs is prone to bugs and may miss various corner cases in task specifications. Presenting such buggy code to users can impact their reliability and trust in LLM-based assistants. Moreover, significant efforts are required by the user to detect and repair any bug present in the code, especially if no test cases are available. In this study, we propose a self-refinement method aimed at improving the reliability of code generated by LLMs by minimizing the number of bugs before execution, without human intervention, and in the absence of test cases. Our approach is based on targeted Verification Questions (VQs) to identify potential bugs within the initial code. These VQs target various nodes within the Abstract Syntax Tree (AST) of the initial code, which have the potential to trigger specific types of bug patterns commonly found in LLM-generated code. Finally, our method attempts to repair these potential bugs by re-prompting the LLM with the targeted VQs and the initial code. Our evaluation, based on programming tasks in the CoderEval dataset, demonstrates that our proposed method outperforms state-of-the-art methods by decreasing the number of targeted errors in the code between 21% to 62% and improving the number of executable code instances to 13%.
Bugs in Large Language Models Generated Code: An Empirical Study
Mar 18, 2024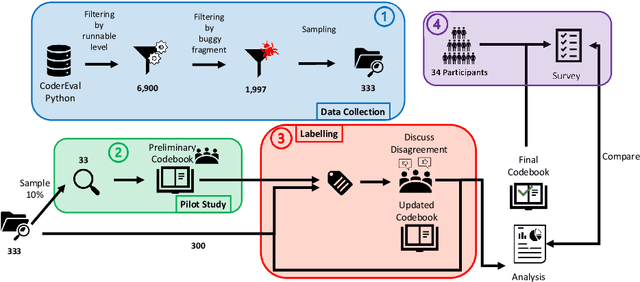

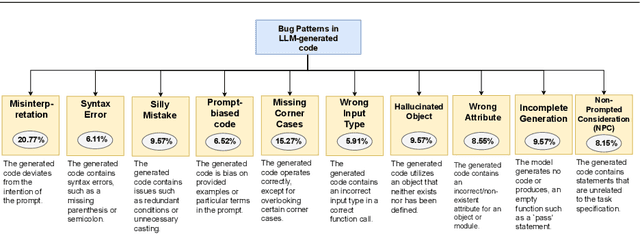

Large Language Models (LLMs) for code have gained significant attention recently. They can generate code in different programming languages based on provided prompts, fulfilling a long-lasting dream in Software Engineering (SE), i.e., automatic code generation. Similar to human-written code, LLM-generated code is prone to bugs, and these bugs have not yet been thoroughly examined by the community. Given the increasing adoption of LLM-based code generation tools (e.g., GitHub Copilot) in SE activities, it is critical to understand the characteristics of bugs contained in code generated by LLMs. This paper examines a sample of 333 bugs collected from code generated using three leading LLMs (i.e., CodeGen, PanGu-Coder, and Codex) and identifies the following 10 distinctive bug patterns: Misinterpretations, Syntax Error, Silly Mistake, Prompt-biased code, Missing Corner Case, Wrong Input Type, Hallucinated Object, Wrong Attribute, Incomplete Generation, and Non-Prompted Consideration. The bug patterns are presented in the form of a taxonomy. The identified bug patterns are validated using an online survey with 34 LLM practitioners and researchers. The surveyed participants generally asserted the significance and prevalence of the bug patterns. Researchers and practitioners can leverage these findings to develop effective quality assurance techniques for LLM-generated code. This study sheds light on the distinctive characteristics of LLM-generated code.
Deep Learning Model Reuse in the HuggingFace Community: Challenges, Benefit and Trends
Jan 24, 2024

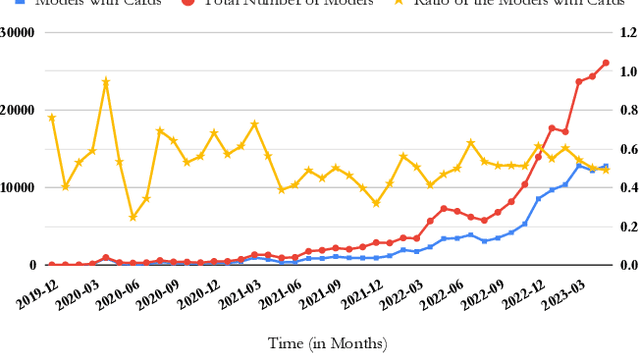

The ubiquity of large-scale Pre-Trained Models (PTMs) is on the rise, sparking interest in model hubs, and dedicated platforms for hosting PTMs. Despite this trend, a comprehensive exploration of the challenges that users encounter and how the community leverages PTMs remains lacking. To address this gap, we conducted an extensive mixed-methods empirical study by focusing on discussion forums and the model hub of HuggingFace, the largest public model hub. Based on our qualitative analysis, we present a taxonomy of the challenges and benefits associated with PTM reuse within this community. We then conduct a quantitative study to track model-type trends and model documentation evolution over time. Our findings highlight prevalent challenges such as limited guidance for beginner users, struggles with model output comprehensibility in training or inference, and a lack of model understanding. We also identified interesting trends among models where some models maintain high upload rates despite a decline in topics related to them. Additionally, we found that despite the introduction of model documentation tools, its quantity has not increased over time, leading to difficulties in model comprehension and selection among users. Our study sheds light on new challenges in reusing PTMs that were not reported before and we provide recommendations for various stakeholders involved in PTM reuse.
GIST: Generated Inputs Sets Transferability in Deep Learning
Nov 01, 2023As the demand for verifiability and testability of neural networks continues to rise, an increasing number of methods for generating test sets are being developed. However, each of these techniques tends to emphasize specific testing aspects and can be quite time-consuming. A straightforward solution to mitigate this issue is to transfer test sets between some benchmarked models and a new model under test, based on a desirable property one wishes to transfer. This paper introduces GIST (Generated Inputs Sets Transferability), a novel approach for the efficient transfer of test sets among Deep Learning models. Given a property of interest that a user wishes to transfer (e.g., coverage criterion), GIST enables the selection of good test sets from the point of view of this property among available ones from a benchmark. We empirically evaluate GIST on fault types coverage property with two modalities and different test set generation procedures to demonstrate the approach's feasibility. Experimental results show that GIST can select an effective test set for the given property to transfer it to the model under test. Our results suggest that GIST could be applied to transfer other properties and could generalize to different test sets' generation procedures and modalities
Bug Characterization in Machine Learning-based Systems
Jul 26, 2023Rapid growth of applying Machine Learning (ML) in different domains, especially in safety-critical areas, increases the need for reliable ML components, i.e., a software component operating based on ML. Understanding the bugs characteristics and maintenance challenges in ML-based systems can help developers of these systems to identify where to focus maintenance and testing efforts, by giving insights into the most error-prone components, most common bugs, etc. In this paper, we investigate the characteristics of bugs in ML-based software systems and the difference between ML and non-ML bugs from the maintenance viewpoint. We extracted 447,948 GitHub repositories that used one of the three most popular ML frameworks, i.e., TensorFlow, Keras, and PyTorch. After multiple filtering steps, we select the top 300 repositories with the highest number of closed issues. We manually investigate the extracted repositories to exclude non-ML-based systems. Our investigation involved a manual inspection of 386 sampled reported issues in the identified ML-based systems to indicate whether they affect ML components or not. Our analysis shows that nearly half of the real issues reported in ML-based systems are ML bugs, indicating that ML components are more error-prone than non-ML components. Next, we thoroughly examined 109 identified ML bugs to identify their root causes, symptoms, and calculate their required fixing time. The results also revealed that ML bugs have significantly different characteristics compared to non-ML bugs, in terms of the complexity of bug-fixing (number of commits, changed files, and changed lines of code). Based on our results, fixing ML bugs are more costly and ML components are more error-prone, compared to non-ML bugs and non-ML components respectively. Hence, paying a significant attention to the reliability of the ML components is crucial in ML-based systems.
Mutation Testing of Deep Reinforcement Learning Based on Real Faults
Jan 13, 2023Testing Deep Learning (DL) systems is a complex task as they do not behave like traditional systems would, notably because of their stochastic nature. Nonetheless, being able to adapt existing testing techniques such as Mutation Testing (MT) to DL settings would greatly improve their potential verifiability. While some efforts have been made to extend MT to the Supervised Learning paradigm, little work has gone into extending it to Reinforcement Learning (RL) which is also an important component of the DL ecosystem but behaves very differently from SL. This paper builds on the existing approach of MT in order to propose a framework, RLMutation, for MT applied to RL. Notably, we use existing taxonomies of faults to build a set of mutation operators relevant to RL and use a simple heuristic to generate test cases for RL. This allows us to compare different mutation killing definitions based on existing approaches, as well as to analyze the behavior of the obtained mutation operators and their potential combinations called Higher Order Mutation(s) (HOM). We show that the design choice of the mutation killing definition can affect whether or not a mutation is killed as well as the generated test cases. Moreover, we found that even with a relatively small number of test cases and operators we manage to generate HOM with interesting properties which can enhance testing capability in RL systems.
A Probabilistic Framework for Mutation Testing in Deep Neural Networks
Aug 11, 2022



Context: Mutation Testing (MT) is an important tool in traditional Software Engineering (SE) white-box testing. It aims to artificially inject faults in a system to evaluate a test suite's capability to detect them, assuming that the test suite defects finding capability will then translate to real faults. If MT has long been used in SE, it is only recently that it started gaining the attention of the Deep Learning (DL) community, with researchers adapting it to improve the testability of DL models and improve the trustworthiness of DL systems. Objective: If several techniques have been proposed for MT, most of them neglected the stochasticity inherent to DL resulting from the training phase. Even the latest MT approaches in DL, which propose to tackle MT through a statistical approach, might give inconsistent results. Indeed, as their statistic is based on a fixed set of sampled training instances, it can lead to different results across instances set when results should be consistent for any instance. Methods: In this work, we propose a Probabilistic Mutation Testing (PMT) approach that alleviates the inconsistency problem and allows for a more consistent decision on whether a mutant is killed or not. Results: We show that PMT effectively allows a more consistent and informed decision on mutations through evaluation using three models and eight mutation operators used in previously proposed MT methods. We also analyze the trade-off between the approximation error and the cost of our method, showing that relatively small error can be achieved for a manageable cost. Conclusion: Our results showed the limitation of current MT practices in DNN and the need to rethink them. We believe PMT is the first step in that direction which effectively removes the lack of consistency across test executions of previous methods caused by the stochasticity of DNN training.
Silent Bugs in Deep Learning Frameworks: An Empirical Study of Keras and TensorFlow
Dec 26, 2021

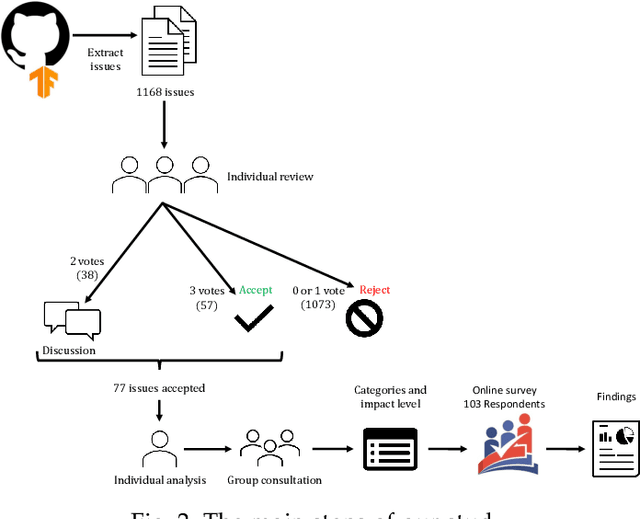

Deep Learning (DL) frameworks are now widely used, simplifying the creation of complex models as well as their integration to various applications even to non DL experts. However, like any other programs, they are prone to bugs. This paper deals with the subcategory of bugs named silent bugs: they lead to wrong behavior but they do not cause system crashes or hangs, nor show an error message to the user. Such bugs are even more dangerous in DL applications and frameworks due to the "black-box" and stochastic nature of the systems (the end user can not understand how the model makes decisions). This paper presents the first empirical study of Keras and TensorFlow silent bugs, and their impact on users' programs. We extracted closed issues related to Keras from the TensorFlow GitHub repository. Out of the 1,168 issues that we gathered, 77 were reproducible silent bugs affecting users' programs. We categorized the bugs based on the effects on the users' programs and the components where the issues occurred, using information from the issue reports. We then derived a threat level for each of the issues, based on the impact they had on the users' programs. To assess the relevance of identified categories and the impact scale, we conducted an online survey with 103 DL developers. The participants generally agreed with the significant impact of silent bugs in DL libraries and acknowledged our findings (i.e., categories of silent bugs and the proposed impact scale). Finally, leveraging our analysis, we provide a set of guidelines to facilitate safeguarding against such bugs in DL frameworks.
How to Certify Machine Learning Based Safety-critical Systems? A Systematic Literature Review
Aug 03, 2021
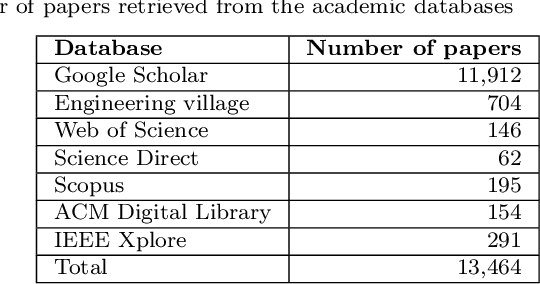

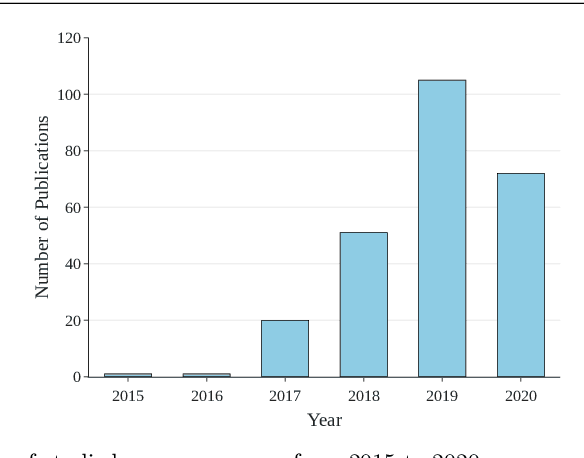
Context: Machine Learning (ML) has been at the heart of many innovations over the past years. However, including it in so-called 'safety-critical' systems such as automotive or aeronautic has proven to be very challenging, since the shift in paradigm that ML brings completely changes traditional certification approaches. Objective: This paper aims to elucidate challenges related to the certification of ML-based safety-critical systems, as well as the solutions that are proposed in the literature to tackle them, answering the question 'How to Certify Machine Learning Based Safety-critical Systems?'. Method: We conduct a Systematic Literature Review (SLR) of research papers published between 2015 to 2020, covering topics related to the certification of ML systems. In total, we identified 217 papers covering topics considered to be the main pillars of ML certification: Robustness, Uncertainty, Explainability, Verification, Safe Reinforcement Learning, and Direct Certification. We analyzed the main trends and problems of each sub-field and provided summaries of the papers extracted. Results: The SLR results highlighted the enthusiasm of the community for this subject, as well as the lack of diversity in terms of datasets and type of models. It also emphasized the need to further develop connections between academia and industries to deepen the domain study. Finally, it also illustrated the necessity to build connections between the above mention main pillars that are for now mainly studied separately. Conclusion: We highlighted current efforts deployed to enable the certification of ML based software systems, and discuss some future research directions.