 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBugs in Large Language Models Generated Code: An Empirical Study
Mar 18, 2024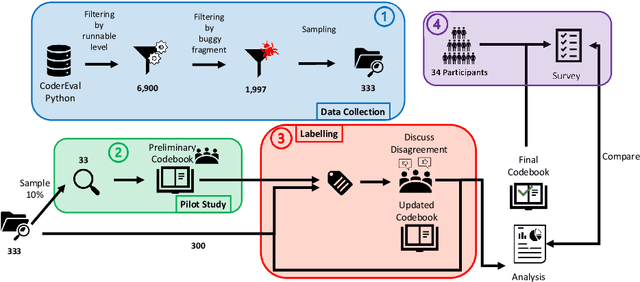

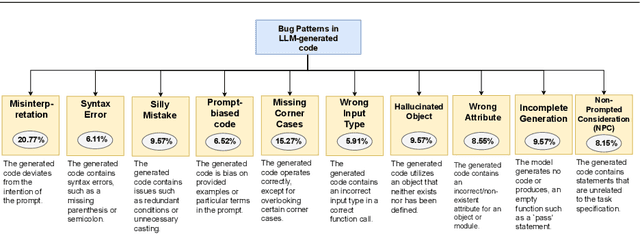

Large Language Models (LLMs) for code have gained significant attention recently. They can generate code in different programming languages based on provided prompts, fulfilling a long-lasting dream in Software Engineering (SE), i.e., automatic code generation. Similar to human-written code, LLM-generated code is prone to bugs, and these bugs have not yet been thoroughly examined by the community. Given the increasing adoption of LLM-based code generation tools (e.g., GitHub Copilot) in SE activities, it is critical to understand the characteristics of bugs contained in code generated by LLMs. This paper examines a sample of 333 bugs collected from code generated using three leading LLMs (i.e., CodeGen, PanGu-Coder, and Codex) and identifies the following 10 distinctive bug patterns: Misinterpretations, Syntax Error, Silly Mistake, Prompt-biased code, Missing Corner Case, Wrong Input Type, Hallucinated Object, Wrong Attribute, Incomplete Generation, and Non-Prompted Consideration. The bug patterns are presented in the form of a taxonomy. The identified bug patterns are validated using an online survey with 34 LLM practitioners and researchers. The surveyed participants generally asserted the significance and prevalence of the bug patterns. Researchers and practitioners can leverage these findings to develop effective quality assurance techniques for LLM-generated code. This study sheds light on the distinctive characteristics of LLM-generated code.
Alloprof: a new French question-answer education dataset and its use in an information retrieval case study
Feb 10, 2023



Teachers and students are increasingly relying on online learning resources to supplement the ones provided in school. This increase in the breadth and depth of available resources is a great thing for students, but only provided they are able to find answers to their queries. Question-answering and information retrieval systems have benefited from public datasets to train and evaluate their algorithms, but most of these datasets have been in English text written by and for adults. We introduce a new public French question-answering dataset collected from Alloprof, a Quebec-based primary and high-school help website, containing 29 349 questions and their explanations in a variety of school subjects from 10 368 students, with more than half of the explanations containing links to other questions or some of the 2 596 reference pages on the website. We also present a case study of this dataset in an information retrieval task. This dataset was collected on the Alloprof public forum, with all questions verified for their appropriateness and the explanations verified both for their appropriateness and their relevance to the question. To predict relevant documents, architectures using pre-trained BERT models were fine-tuned and evaluated. This dataset will allow researchers to develop question-answering, information retrieval and other algorithms specifically for the French speaking education context. Furthermore, the range of language proficiency, images, mathematical symbols and spelling mistakes will necessitate algorithms based on a multimodal comprehension. The case study we present as a baseline shows an approach that relies on recent techniques provides an acceptable performance level, but more work is necessary before it can reliably be used and trusted in a production setting.
Dev2vec: Representing Domain Expertise of Developers in an Embedding Space
Jul 11, 2022

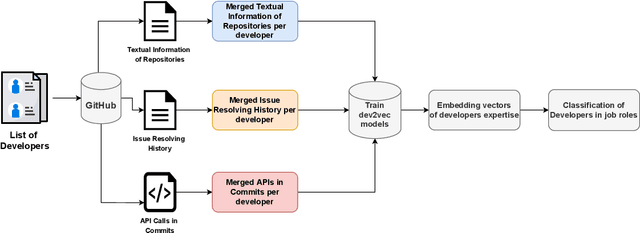
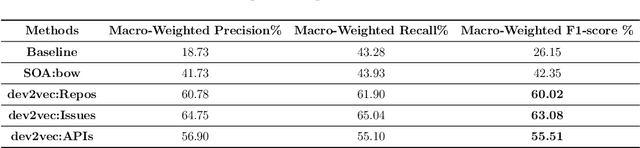
Accurate assessment of the domain expertise of developers is important for assigning the proper candidate to contribute to a project or to attend a job role. Since the potential candidate can come from a large pool, the automated assessment of this domain expertise is a desirable goal. While previous methods have had some success within a single software project, the assessment of a developer's domain expertise from contributions across multiple projects is more challenging. In this paper, we employ doc2vec to represent the domain expertise of developers as embedding vectors. These vectors are derived from different sources that contain evidence of developers' expertise, such as the description of repositories that they contributed, their issue resolving history, and API calls in their commits. We name it dev2vec and demonstrate its effectiveness in representing the technical specialization of developers. Our results indicate that encoding the expertise of developers in an embedding vector outperforms state-of-the-art methods and improves the F1-score up to 21%. Moreover, our findings suggest that ``issue resolving history'' of developers is the most informative source of information to represent the domain expertise of developers in embedding spaces.
GitHub Copilot AI pair programmer: Asset or Liability?
Jun 30, 2022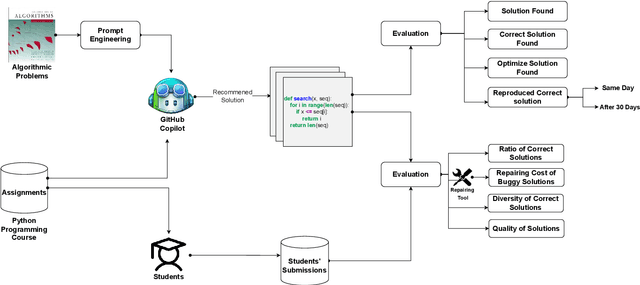
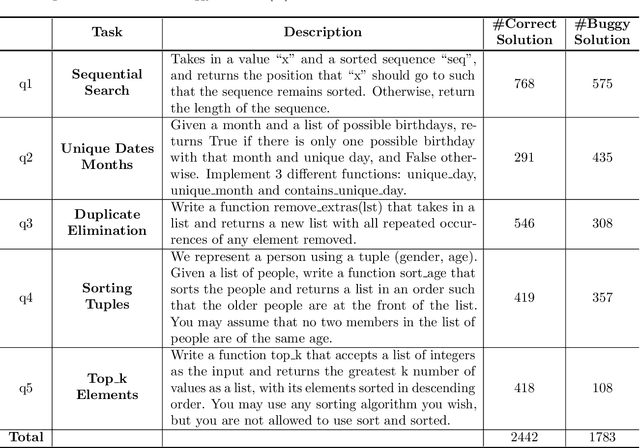

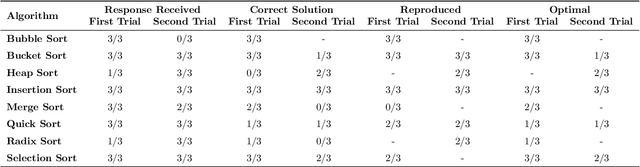
Automatic program synthesis is a long-lasting dream in software engineering. Recently, a promising Deep Learning (DL) based solution, called Copilot, has been proposed by Open AI and Microsoft as an industrial product. Although some studies evaluate the correctness of Copilot solutions and report its issues, more empirical evaluations are necessary to understand how developers can benefit from it effectively. In this paper, we study the capabilities of Copilot in two different programming tasks: (1) generating (and reproducing) correct and efficient solutions for fundamental algorithmic problems, and (2) comparing Copilot's proposed solutions with those of human programmers on a set of programming tasks. For the former, we assess the performance and functionality of Copilot in solving selected fundamental problems in computer science, like sorting and implementing basic data structures. In the latter, a dataset of programming problems with human-provided solutions is used. The results show that Copilot is capable of providing solutions for almost all fundamental algorithmic problems, however, some solutions are buggy and non-reproducible. Moreover, Copilot has some difficulties in combining multiple methods to generate a solution. Comparing Copilot to humans, our results show that the correct ratio of human solutions is greater than Copilot's correct ratio, while the buggy solutions generated by Copilot require less effort to be repaired. While Copilot shows limitations as an assistant for developers especially in advanced programming tasks, as highlighted in this study and previous ones, it can generate preliminary solutions for basic programming tasks.
Deep Knowledge Tracing and Dynamic Student Classification for Knowledge Tracing
Sep 24, 2018
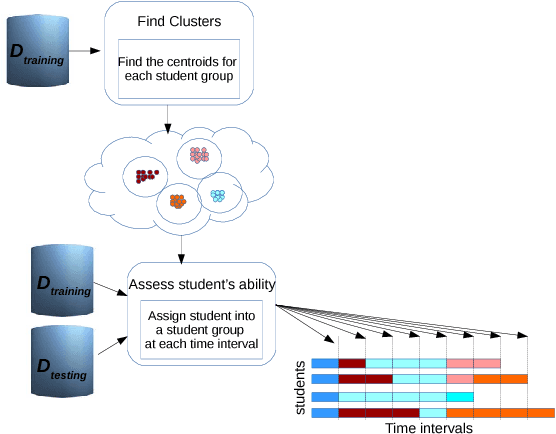
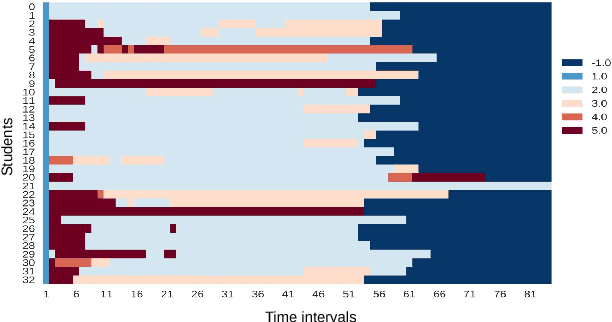
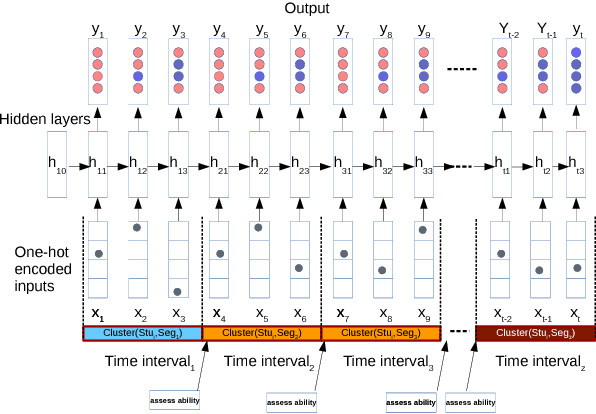
In Intelligent Tutoring System (ITS), tracing the student's knowledge state during learning has been studied for several decades in order to provide more supportive learning instructions. In this paper, we propose a novel model for knowledge tracing that i) captures students' learning ability and dynamically assigns students into distinct groups with similar ability at regular time intervals, and ii) combines this information with a Recurrent Neural Network architecture known as Deep Knowledge Tracing. Experimental results confirm that the proposed model is significantly better at predicting student performance than well known state-of-the-art techniques for student modelling.