 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Hitchhikers Guide to Production-ready Trustworthy Foundation Model powered Software (FMware)
May 15, 2025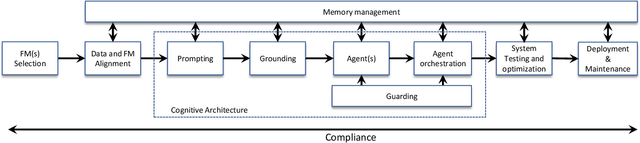
Foundation Models (FMs) such as Large Language Models (LLMs) are reshaping the software industry by enabling FMware, systems that integrate these FMs as core components. In this KDD 2025 tutorial, we present a comprehensive exploration of FMware that combines a curated catalogue of challenges with real-world production concerns. We first discuss the state of research and practice in building FMware. We further examine the difficulties in selecting suitable models, aligning high-quality domain-specific data, engineering robust prompts, and orchestrating autonomous agents. We then address the complex journey from impressive demos to production-ready systems by outlining issues in system testing, optimization, deployment, and integration with legacy software. Drawing on our industrial experience and recent research in the area, we provide actionable insights and a technology roadmap for overcoming these challenges. Attendees will gain practical strategies to enable the creation of trustworthy FMware in the evolving technology landscape.
Towards AI-Native Software Engineering (SE 3.0): A Vision and a Challenge Roadmap
Oct 08, 2024



The rise of AI-assisted software engineering (SE 2.0), powered by Foundation Models (FMs) and FM-powered copilots, has shown promise in improving developer productivity. However, it has also exposed inherent limitations, such as cognitive overload on developers and inefficiencies. We propose a shift towards Software Engineering 3.0 (SE 3.0), an AI-native approach characterized by intent-first, conversation-oriented development between human developers and AI teammates. SE 3.0 envisions AI systems evolving beyond task-driven copilots into intelligent collaborators, capable of deeply understanding and reasoning about software engineering principles and intents. We outline the key components of the SE 3.0 technology stack, which includes Teammate.next for adaptive and personalized AI partnership, IDE.next for intent-first conversation-oriented development, Compiler.next for multi-objective code synthesis, and Runtime.next for SLA-aware execution with edge-computing support. Our vision addresses the inefficiencies and cognitive strain of SE 2.0 by fostering a symbiotic relationship between human developers and AI, maximizing their complementary strengths. We also present a roadmap of challenges that must be overcome to realize our vision of SE 3.0. This paper lays the foundation for future discussions on the role of AI in the next era of software engineering.
Keeping Deep Learning Models in Check: A History-Based Approach to Mitigate Overfitting
Jan 18, 2024In software engineering, deep learning models are increasingly deployed for critical tasks such as bug detection and code review. However, overfitting remains a challenge that affects the quality, reliability, and trustworthiness of software systems that utilize deep learning models. Overfitting can be (1) prevented (e.g., using dropout or early stopping) or (2) detected in a trained model (e.g., using correlation-based approaches). Both overfitting detection and prevention approaches that are currently used have constraints (e.g., requiring modification of the model structure, and high computing resources). In this paper, we propose a simple, yet powerful approach that can both detect and prevent overfitting based on the training history (i.e., validation losses). Our approach first trains a time series classifier on training histories of overfit models. This classifier is then used to detect if a trained model is overfit. In addition, our trained classifier can be used to prevent overfitting by identifying the optimal point to stop a model's training. We evaluate our approach on its ability to identify and prevent overfitting in real-world samples. We compare our approach against correlation-based detection approaches and the most commonly used prevention approach (i.e., early stopping). Our approach achieves an F1 score of 0.91 which is at least 5% higher than the current best-performing non-intrusive overfitting detection approach. Furthermore, our approach can stop training to avoid overfitting at least 32% of the times earlier than early stopping and has the same or a better rate of returning the best model.
Studying the Practices of Testing Machine Learning Software in the Wild
Dec 19, 2023
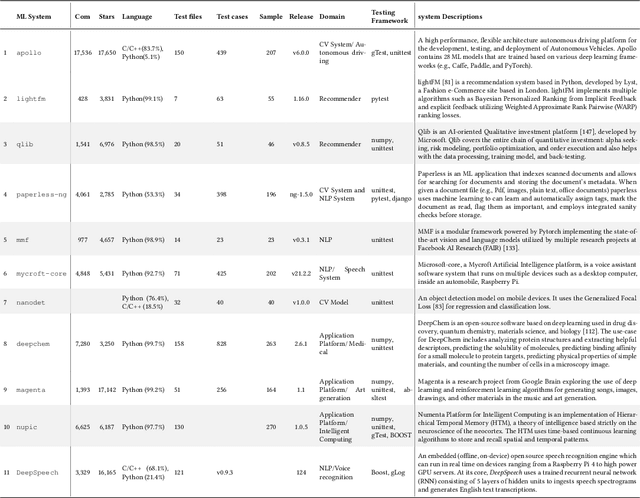
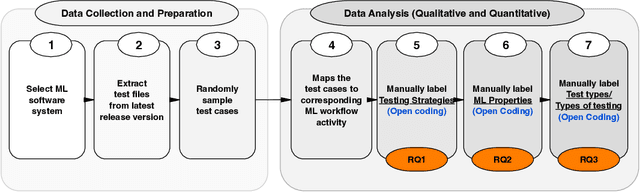

Background: We are witnessing an increasing adoption of machine learning (ML), especially deep learning (DL) algorithms in many software systems, including safety-critical systems such as health care systems or autonomous driving vehicles. Ensuring the software quality of these systems is yet an open challenge for the research community, mainly due to the inductive nature of ML software systems. Traditionally, software systems were constructed deductively, by writing down the rules that govern the behavior of the system as program code. However, for ML software, these rules are inferred from training data. Few recent research advances in the quality assurance of ML systems have adapted different concepts from traditional software testing, such as mutation testing, to help improve the reliability of ML software systems. However, it is unclear if any of these proposed testing techniques from research are adopted in practice. There is little empirical evidence about the testing strategies of ML engineers. Aims: To fill this gap, we perform the first fine-grained empirical study on ML testing practices in the wild, to identify the ML properties being tested, the followed testing strategies, and their implementation throughout the ML workflow. Method: First, we systematically summarized the different testing strategies (e.g., Oracle Approximation), the tested ML properties (e.g., Correctness, Bias, and Fairness), and the testing methods (e.g., Unit test) from the literature. Then, we conducted a study to understand the practices of testing ML software. Results: In our findings: 1) we identified four (4) major categories of testing strategy including Grey-box, White-box, Black-box, and Heuristic-based techniques that are used by the ML engineers to find software bugs. 2) We identified 16 ML properties that are tested in the ML workflow.
Bug Characterization in Machine Learning-based Systems
Jul 26, 2023Rapid growth of applying Machine Learning (ML) in different domains, especially in safety-critical areas, increases the need for reliable ML components, i.e., a software component operating based on ML. Understanding the bugs characteristics and maintenance challenges in ML-based systems can help developers of these systems to identify where to focus maintenance and testing efforts, by giving insights into the most error-prone components, most common bugs, etc. In this paper, we investigate the characteristics of bugs in ML-based software systems and the difference between ML and non-ML bugs from the maintenance viewpoint. We extracted 447,948 GitHub repositories that used one of the three most popular ML frameworks, i.e., TensorFlow, Keras, and PyTorch. After multiple filtering steps, we select the top 300 repositories with the highest number of closed issues. We manually investigate the extracted repositories to exclude non-ML-based systems. Our investigation involved a manual inspection of 386 sampled reported issues in the identified ML-based systems to indicate whether they affect ML components or not. Our analysis shows that nearly half of the real issues reported in ML-based systems are ML bugs, indicating that ML components are more error-prone than non-ML components. Next, we thoroughly examined 109 identified ML bugs to identify their root causes, symptoms, and calculate their required fixing time. The results also revealed that ML bugs have significantly different characteristics compared to non-ML bugs, in terms of the complexity of bug-fixing (number of commits, changed files, and changed lines of code). Based on our results, fixing ML bugs are more costly and ML components are more error-prone, compared to non-ML bugs and non-ML components respectively. Hence, paying a significant attention to the reliability of the ML components is crucial in ML-based systems.
GitHub Copilot AI pair programmer: Asset or Liability?
Jun 30, 2022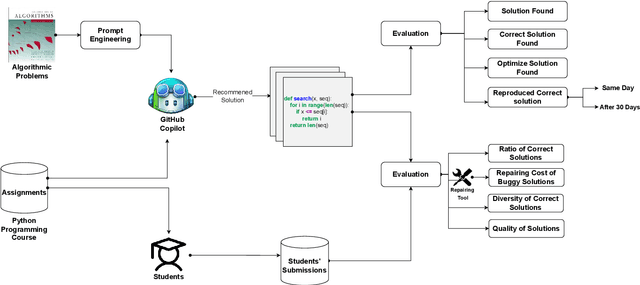
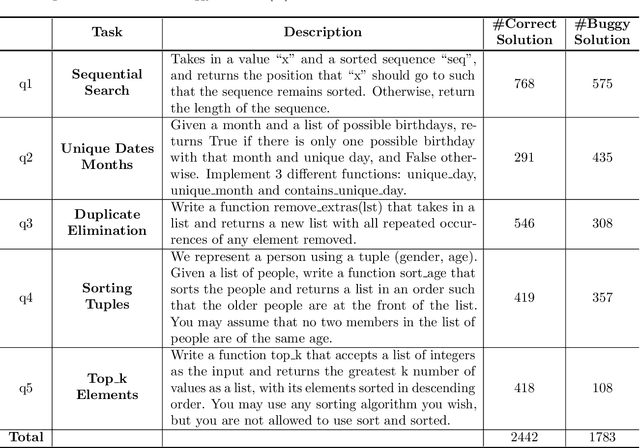

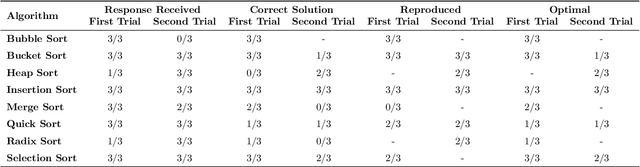
Automatic program synthesis is a long-lasting dream in software engineering. Recently, a promising Deep Learning (DL) based solution, called Copilot, has been proposed by Open AI and Microsoft as an industrial product. Although some studies evaluate the correctness of Copilot solutions and report its issues, more empirical evaluations are necessary to understand how developers can benefit from it effectively. In this paper, we study the capabilities of Copilot in two different programming tasks: (1) generating (and reproducing) correct and efficient solutions for fundamental algorithmic problems, and (2) comparing Copilot's proposed solutions with those of human programmers on a set of programming tasks. For the former, we assess the performance and functionality of Copilot in solving selected fundamental problems in computer science, like sorting and implementing basic data structures. In the latter, a dataset of programming problems with human-provided solutions is used. The results show that Copilot is capable of providing solutions for almost all fundamental algorithmic problems, however, some solutions are buggy and non-reproducible. Moreover, Copilot has some difficulties in combining multiple methods to generate a solution. Comparing Copilot to humans, our results show that the correct ratio of human solutions is greater than Copilot's correct ratio, while the buggy solutions generated by Copilot require less effort to be repaired. While Copilot shows limitations as an assistant for developers especially in advanced programming tasks, as highlighted in this study and previous ones, it can generate preliminary solutions for basic programming tasks.
An Empirical Study of Challenges in Converting Deep Learning Models
Jun 28, 2022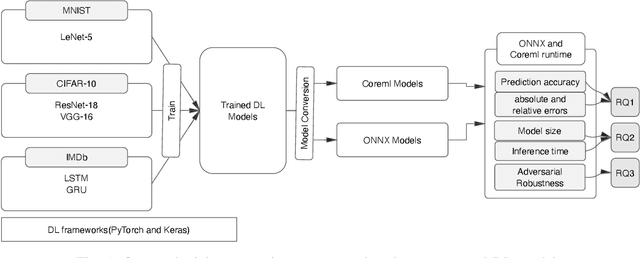
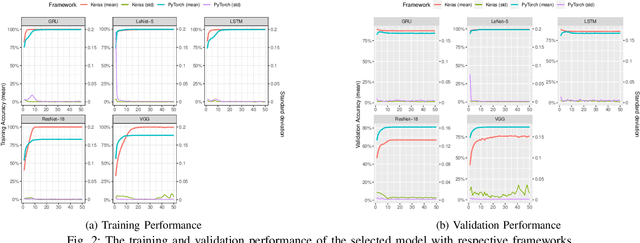
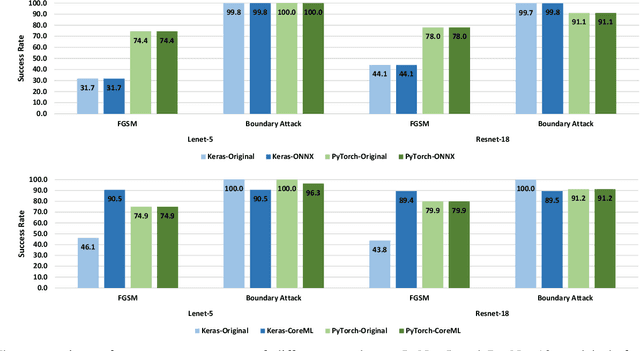
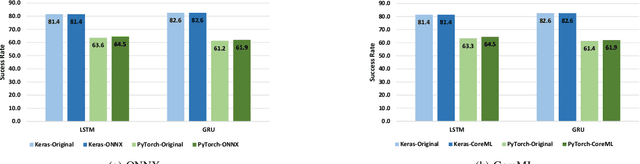
There is an increase in deploying Deep Learning (DL)-based software systems in real-world applications. Usually DL models are developed and trained using DL frameworks that have their own internal mechanisms/formats to represent and train DL models, and usually those formats cannot be recognized by other frameworks. Moreover, trained models are usually deployed in environments different from where they were developed. To solve the interoperability issue and make DL models compatible with different frameworks/environments, some exchange formats are introduced for DL models, like ONNX and CoreML. However, ONNX and CoreML were never empirically evaluated by the community to reveal their prediction accuracy, performance, and robustness after conversion. Poor accuracy or non-robust behavior of converted models may lead to poor quality of deployed DL-based software systems. We conduct, in this paper, the first empirical study to assess ONNX and CoreML for converting trained DL models. In our systematic approach, two popular DL frameworks, Keras and PyTorch, are used to train five widely used DL models on three popular datasets. The trained models are then converted to ONNX and CoreML and transferred to two runtime environments designated for such formats, to be evaluated. We investigate the prediction accuracy before and after conversion. Our results unveil that the prediction accuracy of converted models are at the same level of originals. The performance (time cost and memory consumption) of converted models are studied as well. The size of models are reduced after conversion, which can result in optimized DL-based software deployment. Converted models are generally assessed as robust at the same level of originals. However, obtained results show that CoreML models are more vulnerable to adversarial attacks compared to ONNX.
Bugs in Machine Learning-based Systems: A Faultload Benchmark
Jun 24, 2022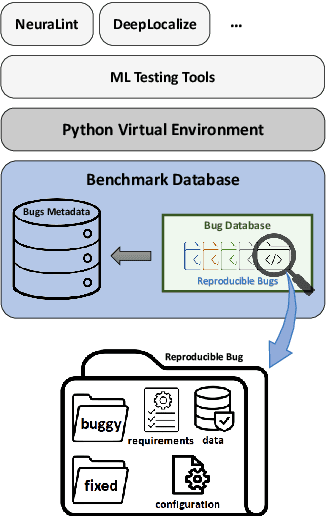


The rapid escalation of applying Machine Learning (ML) in various domains has led to paying more attention to the quality of ML components. There is then a growth of techniques and tools aiming at improving the quality of ML components and integrating them into the ML-based system safely. Although most of these tools use bugs' lifecycle, there is no standard benchmark of bugs to assess their performance, compare them and discuss their advantages and weaknesses. In this study, we firstly investigate the reproducibility and verifiability of the bugs in ML-based systems and show the most important factors in each one. Then, we explore the challenges of generating a benchmark of bugs in ML-based software systems and provide a bug benchmark namely defect4ML that satisfies all criteria of standard benchmark, i.e. relevance, reproducibility, fairness, verifiability, and usability. This faultload benchmark contains 113 bugs reported by ML developers on GitHub and Stack Overflow, using two of the most popular ML frameworks: TensorFlow and Keras. defect4ML also addresses important challenges in Software Reliability Engineering of ML-based software systems, like: 1) fast changes in frameworks, by providing various bugs for different versions of frameworks, 2) code portability, by delivering similar bugs in different ML frameworks, 3) bug reproducibility, by providing fully reproducible bugs with complete information about required dependencies and data, and 4) lack of detailed information on bugs, by presenting links to the bugs' origins. defect4ML can be of interest to ML-based systems practitioners and researchers to assess their testing tools and techniques.
Towards a Change Taxonomy for Machine Learning Systems
Mar 21, 2022

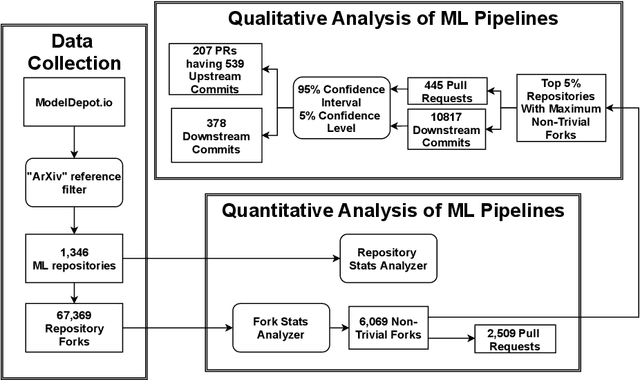
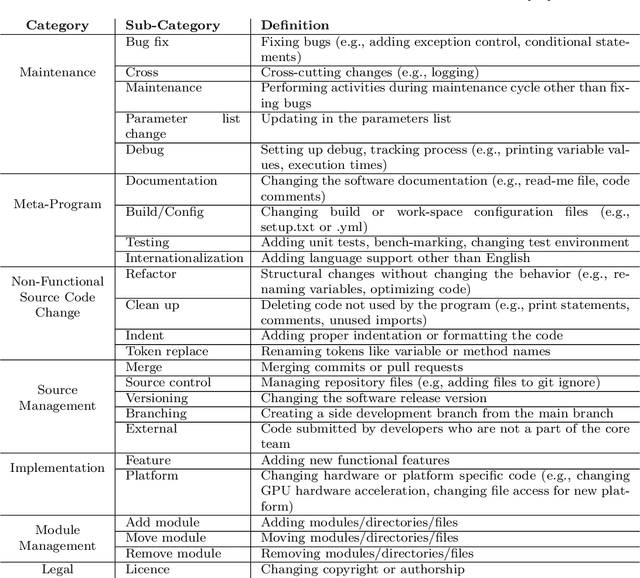
Machine Learning (ML) research publications commonly provide open-source implementations on GitHub, allowing their audience to replicate, validate, or even extend machine learning algorithms, data sets, and metadata. However, thus far little is known about the degree of collaboration activity happening on such ML research repositories, in particular regarding (1) the degree to which such repositories receive contributions from forks, (2) the nature of such contributions (i.e., the types of changes), and (3) the nature of changes that are not contributed back to forks, which might represent missed opportunities. In this paper, we empirically study contributions to 1,346 ML research repositories and their 67,369 forks, both quantitatively and qualitatively (by building on Hindle et al.'s seminal taxonomy of code changes). We found that while ML research repositories are heavily forked, only 9% of the forks made modifications to the forked repository. 42% of the latter sent changes to the parent repositories, half of which (52%) were accepted by the parent repositories. Our qualitative analysis on 539 contributed and 378 local (fork-only) changes, extends Hindle et al.'s taxonomy with one new top-level change category related to ML (Data), and 15 new sub-categories, including nine ML-specific ones (input data, output data, program data, sharing, change evaluation, parameter tuning, performance, pre-processing, model training). While the changes that are not contributed back by the forks mostly concern domain-specific customizations and local experimentation (e.g., parameter tuning), the origin ML repositories do miss out on a non-negligible 15.4% of Documentation changes, 13.6% of Feature changes and 11.4% of Bug fix changes. The findings in this paper will be useful for practitioners, researchers, toolsmiths, and educators.
Towards a consistent interpretation of AIOps models
Feb 04, 2022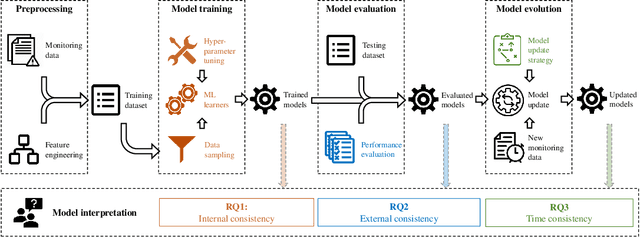


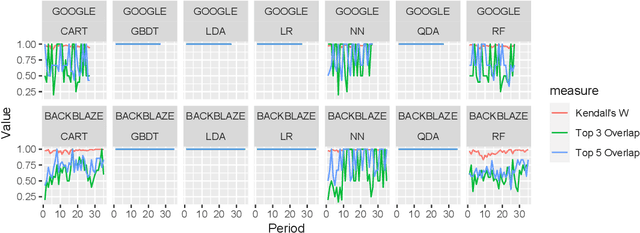
Artificial Intelligence for IT Operations (AIOps) has been adopted in organizations in various tasks, including interpreting models to identify indicators of service failures. To avoid misleading practitioners, AIOps model interpretations should be consistent (i.e., different AIOps models on the same task agree with one another on feature importance). However, many AIOps studies violate established practices in the machine learning community when deriving interpretations, such as interpreting models with suboptimal performance, though the impact of such violations on the interpretation consistency has not been studied. In this paper, we investigate the consistency of AIOps model interpretation along three dimensions: internal consistency, external consistency, and time consistency. We conduct a case study on two AIOps tasks: predicting Google cluster job failures, and Backblaze hard drive failures. We find that the randomness from learners, hyperparameter tuning, and data sampling should be controlled to generate consistent interpretations. AIOps models with AUCs greater than 0.75 yield more consistent interpretation compared to low-performing models. Finally, AIOps models that are constructed with the Sliding Window or Full History approaches have the most consistent interpretation with the trends presented in the entire datasets. Our study provides valuable guidelines for practitioners to derive consistent AIOps model interpretation.