 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Moral Stress Testing of Large Language Models
Apr 01, 2026Evaluating the ethical robustness of large language models (LLMs) deployed in software systems remains challenging, particularly under sustained adversarial user interaction. Existing safety benchmarks typically rely on single-round evaluations and aggregate metrics, such as toxicity scores and refusal rates, which offer limited visibility into behavioral instability that may arise during realistic multi-turn interactions. As a result, rare but high-impact ethical failures and progressive degradation effects may remain undetected prior to deployment. This paper introduces Adversarial Moral Stress Testing (AMST), a stress-based evaluation framework for assessing ethical robustness under adversarial multi-round interactions. AMST applies structured stress transformations to prompts and evaluates model behavior through distribution-aware robustness metrics that capture variance, tail risk, and temporal behavioral drift across interaction rounds. We evaluate AMST on several state-of-the-art LLMs, including LLaMA-3-8B, GPT-4o, and DeepSeek-v3, using a large set of adversarial scenarios generated under controlled stress conditions. The results demonstrate substantial differences in robustness profiles across models and expose degradation patterns that are not observable under conventional single-round evaluation protocols. In particular, robustness has been shown to depend on distributional stability and tail behavior rather than on average performance alone. Additionally, AMST provides a scalable and model-agnostic stress-testing methodology that enables robustness-aware evaluation and monitoring of LLM-enabled software systems operating in adversarial environments.
Secure Tool Manifest and Digital Signing Solution for Verifiable MCP and LLM Pipelines
Jan 30, 2026Large Language Models (LLMs) are increasingly adopted in sensitive domains such as healthcare and financial institutions' data analytics; however, their execution pipelines remain vulnerable to manipulation and unverifiable behavior. Existing control mechanisms, such as the Model Context Protocol (MCP), define compliance policies for tool invocation but lack verifiable enforcement and transparent validation of model actions. To address this gap, we propose a novel Secure Tool Manifest and Digital Signing Framework, a structured and security-aware extension of Model Context Protocols. The framework enforces cryptographically signed manifests, integrates transparent verification logs, and isolates model-internal execution metadata from user-visible components to ensure verifiable execution integrity. Furthermore, the evaluation demonstrates that the framework scales nearly linearly (R-squared = 0.998), achieves near-perfect acceptance of valid executions while consistently rejecting invalid ones, and maintains balanced model utilization across execution pipelines.
Chain of Targeted Verification Questions to Improve the Reliability of Code Generated by LLMs
May 22, 2024



LLM-based assistants, such as GitHub Copilot and ChatGPT, have the potential to generate code that fulfills a programming task described in a natural language description, referred to as a prompt. The widespread accessibility of these assistants enables users with diverse backgrounds to generate code and integrate it into software projects. However, studies show that code generated by LLMs is prone to bugs and may miss various corner cases in task specifications. Presenting such buggy code to users can impact their reliability and trust in LLM-based assistants. Moreover, significant efforts are required by the user to detect and repair any bug present in the code, especially if no test cases are available. In this study, we propose a self-refinement method aimed at improving the reliability of code generated by LLMs by minimizing the number of bugs before execution, without human intervention, and in the absence of test cases. Our approach is based on targeted Verification Questions (VQs) to identify potential bugs within the initial code. These VQs target various nodes within the Abstract Syntax Tree (AST) of the initial code, which have the potential to trigger specific types of bug patterns commonly found in LLM-generated code. Finally, our method attempts to repair these potential bugs by re-prompting the LLM with the targeted VQs and the initial code. Our evaluation, based on programming tasks in the CoderEval dataset, demonstrates that our proposed method outperforms state-of-the-art methods by decreasing the number of targeted errors in the code between 21% to 62% and improving the number of executable code instances to 13%.
Bugs in Large Language Models Generated Code: An Empirical Study
Mar 18, 2024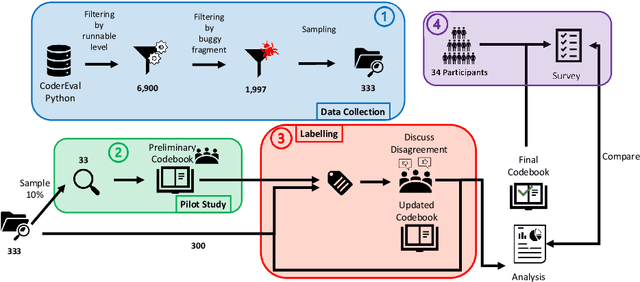

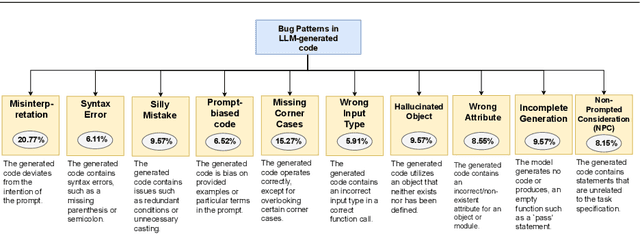

Large Language Models (LLMs) for code have gained significant attention recently. They can generate code in different programming languages based on provided prompts, fulfilling a long-lasting dream in Software Engineering (SE), i.e., automatic code generation. Similar to human-written code, LLM-generated code is prone to bugs, and these bugs have not yet been thoroughly examined by the community. Given the increasing adoption of LLM-based code generation tools (e.g., GitHub Copilot) in SE activities, it is critical to understand the characteristics of bugs contained in code generated by LLMs. This paper examines a sample of 333 bugs collected from code generated using three leading LLMs (i.e., CodeGen, PanGu-Coder, and Codex) and identifies the following 10 distinctive bug patterns: Misinterpretations, Syntax Error, Silly Mistake, Prompt-biased code, Missing Corner Case, Wrong Input Type, Hallucinated Object, Wrong Attribute, Incomplete Generation, and Non-Prompted Consideration. The bug patterns are presented in the form of a taxonomy. The identified bug patterns are validated using an online survey with 34 LLM practitioners and researchers. The surveyed participants generally asserted the significance and prevalence of the bug patterns. Researchers and practitioners can leverage these findings to develop effective quality assurance techniques for LLM-generated code. This study sheds light on the distinctive characteristics of LLM-generated code.
Dev2vec: Representing Domain Expertise of Developers in an Embedding Space
Jul 11, 2022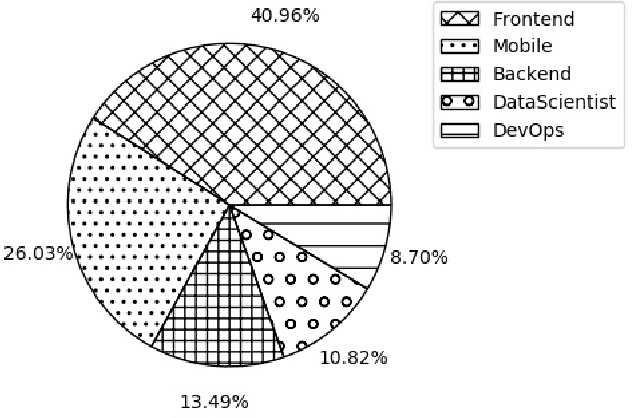

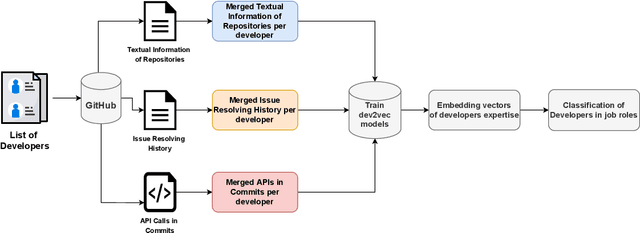
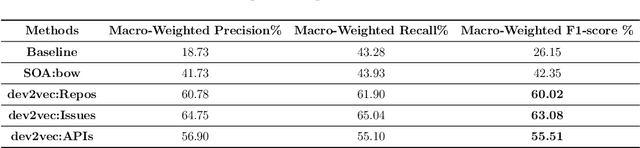
Accurate assessment of the domain expertise of developers is important for assigning the proper candidate to contribute to a project or to attend a job role. Since the potential candidate can come from a large pool, the automated assessment of this domain expertise is a desirable goal. While previous methods have had some success within a single software project, the assessment of a developer's domain expertise from contributions across multiple projects is more challenging. In this paper, we employ doc2vec to represent the domain expertise of developers as embedding vectors. These vectors are derived from different sources that contain evidence of developers' expertise, such as the description of repositories that they contributed, their issue resolving history, and API calls in their commits. We name it dev2vec and demonstrate its effectiveness in representing the technical specialization of developers. Our results indicate that encoding the expertise of developers in an embedding vector outperforms state-of-the-art methods and improves the F1-score up to 21%. Moreover, our findings suggest that ``issue resolving history'' of developers is the most informative source of information to represent the domain expertise of developers in embedding spaces.
GitHub Copilot AI pair programmer: Asset or Liability?
Jun 30, 2022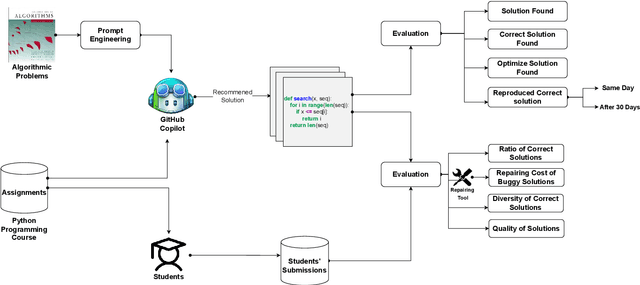
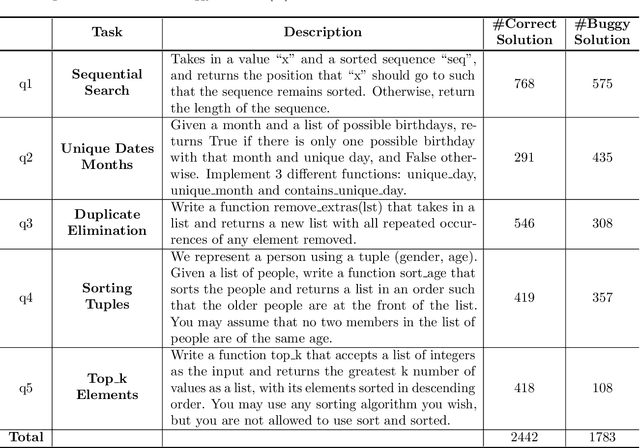

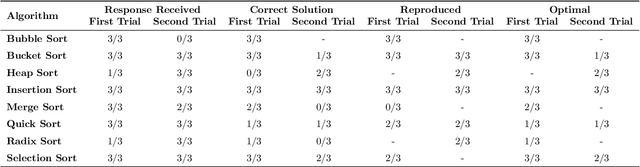
Automatic program synthesis is a long-lasting dream in software engineering. Recently, a promising Deep Learning (DL) based solution, called Copilot, has been proposed by Open AI and Microsoft as an industrial product. Although some studies evaluate the correctness of Copilot solutions and report its issues, more empirical evaluations are necessary to understand how developers can benefit from it effectively. In this paper, we study the capabilities of Copilot in two different programming tasks: (1) generating (and reproducing) correct and efficient solutions for fundamental algorithmic problems, and (2) comparing Copilot's proposed solutions with those of human programmers on a set of programming tasks. For the former, we assess the performance and functionality of Copilot in solving selected fundamental problems in computer science, like sorting and implementing basic data structures. In the latter, a dataset of programming problems with human-provided solutions is used. The results show that Copilot is capable of providing solutions for almost all fundamental algorithmic problems, however, some solutions are buggy and non-reproducible. Moreover, Copilot has some difficulties in combining multiple methods to generate a solution. Comparing Copilot to humans, our results show that the correct ratio of human solutions is greater than Copilot's correct ratio, while the buggy solutions generated by Copilot require less effort to be repaired. While Copilot shows limitations as an assistant for developers especially in advanced programming tasks, as highlighted in this study and previous ones, it can generate preliminary solutions for basic programming tasks.