 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrism: Dynamic and Flexible Benchmarking of LLMs Code Generation with Monte Carlo Tree Search
Apr 10, 2025The rapid advancement of Large Language Models (LLMs) has outpaced traditional evaluation methods. Static benchmarks fail to capture the depth and breadth of LLM capabilities and eventually become obsolete, while most dynamic approaches either rely too heavily on LLM-based evaluation or remain constrained by predefined test sets. We introduce Prism, a flexible, dynamic benchmarking framework designed for comprehensive LLM assessment. Prism builds on three key components: (1) a tree-based state representation that models evaluation as a Markov Decision Process, (2) a Monte Carlo Tree Search algorithm adapted to uncover challenging evaluation scenarios, and (3) a multi-agent evaluation pipeline that enables simultaneous assessment of diverse capabilities. To ensure robust evaluation, Prism integrates structural measurements of tree exploration patterns with performance metrics across difficulty levels, providing detailed diagnostics of error patterns, test coverage, and solution approaches. Through extensive experiments on five state-of-the-art LLMs, we analyze how model architecture and scale influence code generation performance across varying task difficulties. Our results demonstrate Prism's effectiveness as a dynamic benchmark that evolves with model advancements while offering deeper insights into their limitations.
DeepCodeProbe: Towards Understanding What Models Trained on Code Learn
Jul 11, 2024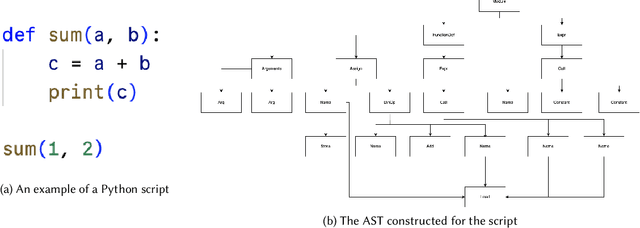
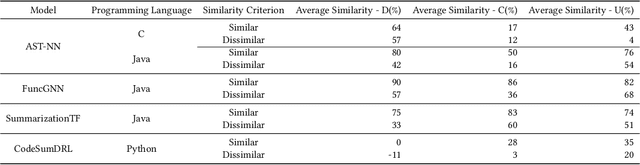
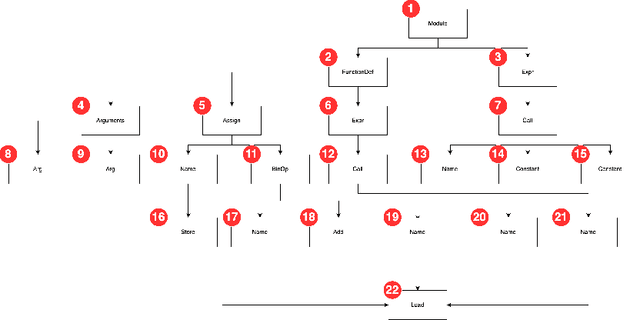
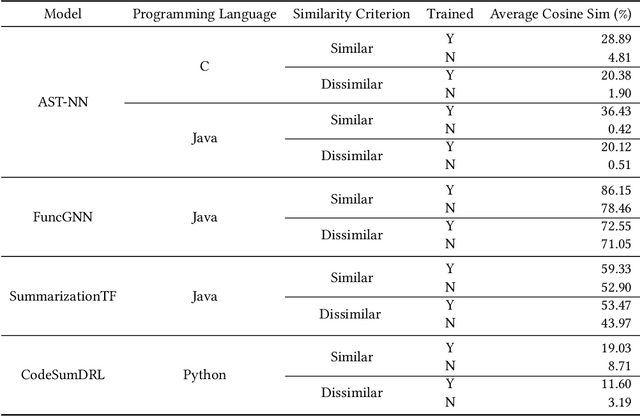
Machine learning models trained on code and related artifacts offer valuable support for software maintenance but suffer from interpretability issues due to their complex internal variables. These concerns are particularly significant in safety-critical applications where the models' decision-making processes must be reliable. The specific features and representations learned by these models remain unclear, adding to the hesitancy in adopting them widely. To address these challenges, we introduce DeepCodeProbe, a probing approach that examines the syntax and representation learning abilities of ML models designed for software maintenance tasks. Our study applies DeepCodeProbe to state-of-the-art models for code clone detection, code summarization, and comment generation. Findings reveal that while small models capture abstract syntactic representations, their ability to fully grasp programming language syntax is limited. Increasing model capacity improves syntax learning but introduces trade-offs such as increased training time and overfitting. DeepCodeProbe also identifies specific code patterns the models learn from their training data. Additionally, we provide best practices for training models on code to enhance performance and interpretability, supported by an open-source replication package for broader application of DeepCodeProbe in interpreting other code-related models.
Trained Without My Consent: Detecting Code Inclusion In Language Models Trained on Code
Feb 14, 2024


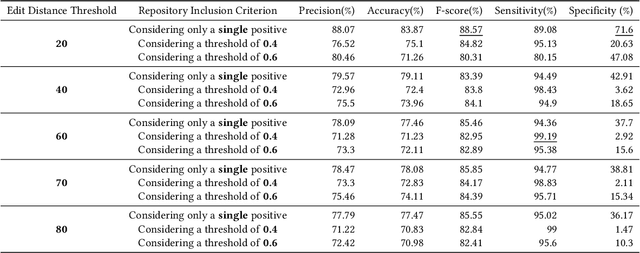
Code auditing ensures that the developed code adheres to standards, regulations, and copyright protection by verifying that it does not contain code from protected sources. The recent advent of Large Language Models (LLMs) as coding assistants in the software development process poses new challenges for code auditing. The dataset for training these models is mainly collected from publicly available sources. This raises the issue of intellectual property infringement as developers' codes are already included in the dataset. Therefore, auditing code developed using LLMs is challenging, as it is difficult to reliably assert if an LLM used during development has been trained on specific copyrighted codes, given that we do not have access to the training datasets of these models. Given the non-disclosure of the training datasets, traditional approaches such as code clone detection are insufficient for asserting copyright infringement. To address this challenge, we propose a new approach, TraWiC; a model-agnostic and interpretable method based on membership inference for detecting code inclusion in an LLM's training dataset. We extract syntactic and semantic identifiers unique to each program to train a classifier for detecting code inclusion. In our experiments, we observe that TraWiC is capable of detecting 83.87% of codes that were used to train an LLM. In comparison, the prevalent clone detection tool NiCad is only capable of detecting 47.64%. In addition to its remarkable performance, TraWiC has low resource overhead in contrast to pair-wise clone detection that is conducted during the auditing process of tools like CodeWhisperer reference tracker, across thousands of code snippets.
An Empirical Study on Bugs Inside PyTorch: A Replication Study
Aug 01, 2023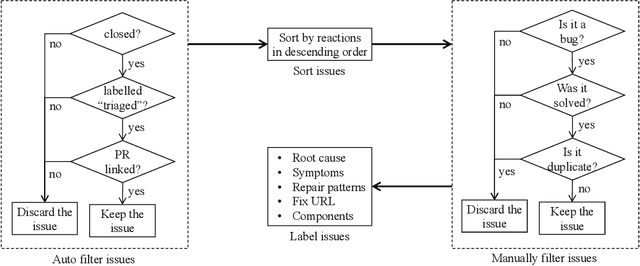
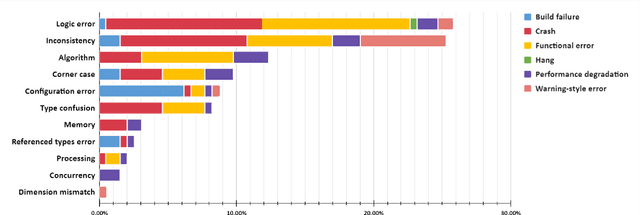
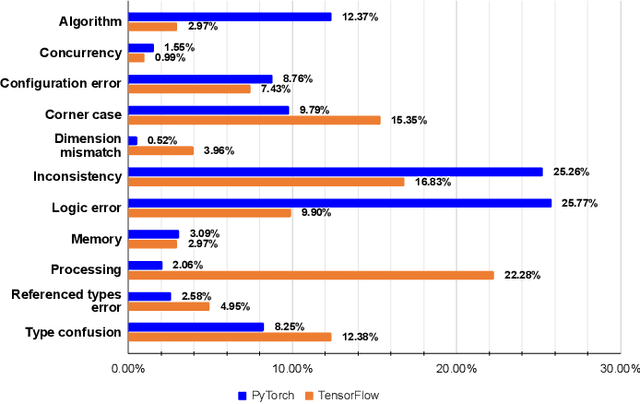
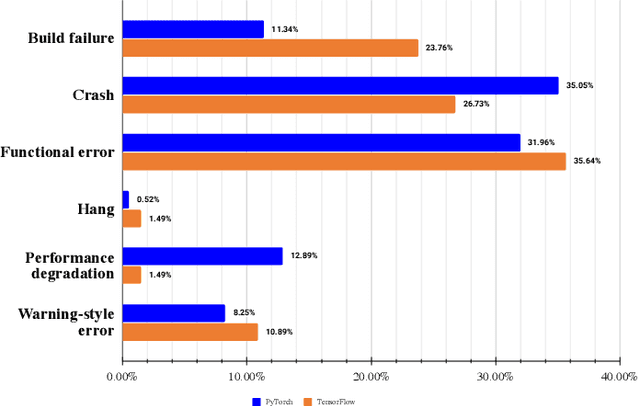
Software systems are increasingly relying on deep learning components, due to their remarkable capability of identifying complex data patterns and powering intelligent behaviour. A core enabler of this change in software development is the availability of easy-to-use deep learning libraries. Libraries like PyTorch and TensorFlow empower a large variety of intelligent systems, offering a multitude of algorithms and configuration options, applicable to numerous domains of systems. However, bugs in those popular deep learning libraries also may have dire consequences for the quality of systems they enable; thus, it is important to understand how bugs are identified and fixed in those libraries. Inspired by a study of Jia et al., which investigates the bug identification and fixing process at TensorFlow, we characterize bugs in the PyTorch library, a very popular deep learning framework. We investigate the causes and symptoms of bugs identified during PyTorch's development, and assess their locality within the project, and extract patterns of bug fixes. Our results highlight that PyTorch bugs are more like traditional software projects bugs, than related to deep learning characteristics. Finally, we also compare our results with the study on TensorFlow, highlighting similarities and differences across the bug identification and fixing process.
Mutation Testing of Deep Reinforcement Learning Based on Real Faults
Jan 13, 2023Testing Deep Learning (DL) systems is a complex task as they do not behave like traditional systems would, notably because of their stochastic nature. Nonetheless, being able to adapt existing testing techniques such as Mutation Testing (MT) to DL settings would greatly improve their potential verifiability. While some efforts have been made to extend MT to the Supervised Learning paradigm, little work has gone into extending it to Reinforcement Learning (RL) which is also an important component of the DL ecosystem but behaves very differently from SL. This paper builds on the existing approach of MT in order to propose a framework, RLMutation, for MT applied to RL. Notably, we use existing taxonomies of faults to build a set of mutation operators relevant to RL and use a simple heuristic to generate test cases for RL. This allows us to compare different mutation killing definitions based on existing approaches, as well as to analyze the behavior of the obtained mutation operators and their potential combinations called Higher Order Mutation(s) (HOM). We show that the design choice of the mutation killing definition can affect whether or not a mutation is killed as well as the generated test cases. Moreover, we found that even with a relatively small number of test cases and operators we manage to generate HOM with interesting properties which can enhance testing capability in RL systems.
GitHub Copilot AI pair programmer: Asset or Liability?
Jun 30, 2022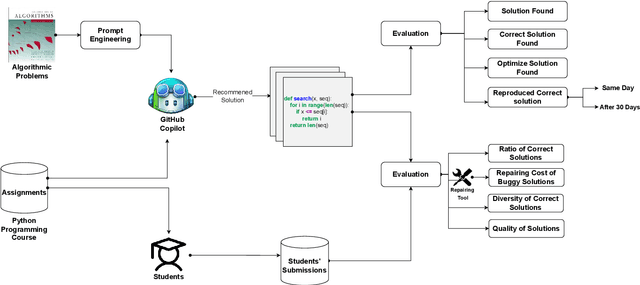
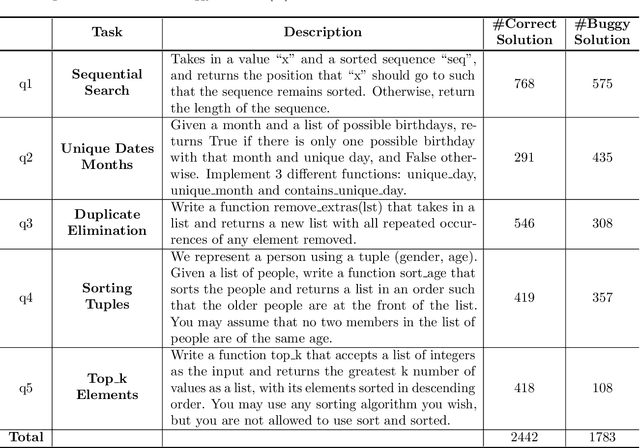

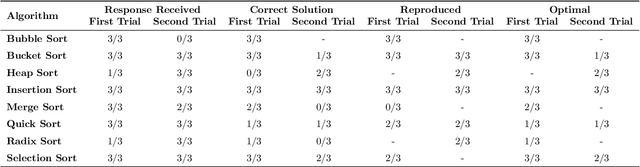
Automatic program synthesis is a long-lasting dream in software engineering. Recently, a promising Deep Learning (DL) based solution, called Copilot, has been proposed by Open AI and Microsoft as an industrial product. Although some studies evaluate the correctness of Copilot solutions and report its issues, more empirical evaluations are necessary to understand how developers can benefit from it effectively. In this paper, we study the capabilities of Copilot in two different programming tasks: (1) generating (and reproducing) correct and efficient solutions for fundamental algorithmic problems, and (2) comparing Copilot's proposed solutions with those of human programmers on a set of programming tasks. For the former, we assess the performance and functionality of Copilot in solving selected fundamental problems in computer science, like sorting and implementing basic data structures. In the latter, a dataset of programming problems with human-provided solutions is used. The results show that Copilot is capable of providing solutions for almost all fundamental algorithmic problems, however, some solutions are buggy and non-reproducible. Moreover, Copilot has some difficulties in combining multiple methods to generate a solution. Comparing Copilot to humans, our results show that the correct ratio of human solutions is greater than Copilot's correct ratio, while the buggy solutions generated by Copilot require less effort to be repaired. While Copilot shows limitations as an assistant for developers especially in advanced programming tasks, as highlighted in this study and previous ones, it can generate preliminary solutions for basic programming tasks.