 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrained Without My Consent: Detecting Code Inclusion In Language Models Trained on Code
Paper and Code
Feb 14, 2024


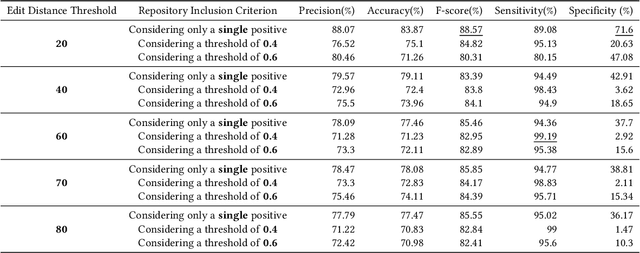
Code auditing ensures that the developed code adheres to standards, regulations, and copyright protection by verifying that it does not contain code from protected sources. The recent advent of Large Language Models (LLMs) as coding assistants in the software development process poses new challenges for code auditing. The dataset for training these models is mainly collected from publicly available sources. This raises the issue of intellectual property infringement as developers' codes are already included in the dataset. Therefore, auditing code developed using LLMs is challenging, as it is difficult to reliably assert if an LLM used during development has been trained on specific copyrighted codes, given that we do not have access to the training datasets of these models. Given the non-disclosure of the training datasets, traditional approaches such as code clone detection are insufficient for asserting copyright infringement. To address this challenge, we propose a new approach, TraWiC; a model-agnostic and interpretable method based on membership inference for detecting code inclusion in an LLM's training dataset. We extract syntactic and semantic identifiers unique to each program to train a classifier for detecting code inclusion. In our experiments, we observe that TraWiC is capable of detecting 83.87% of codes that were used to train an LLM. In comparison, the prevalent clone detection tool NiCad is only capable of detecting 47.64%. In addition to its remarkable performance, TraWiC has low resource overhead in contrast to pair-wise clone detection that is conducted during the auditing process of tools like CodeWhisperer reference tracker, across thousands of code snippets.