 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecure Tool Manifest and Digital Signing Solution for Verifiable MCP and LLM Pipelines
Jan 30, 2026Large Language Models (LLMs) are increasingly adopted in sensitive domains such as healthcare and financial institutions' data analytics; however, their execution pipelines remain vulnerable to manipulation and unverifiable behavior. Existing control mechanisms, such as the Model Context Protocol (MCP), define compliance policies for tool invocation but lack verifiable enforcement and transparent validation of model actions. To address this gap, we propose a novel Secure Tool Manifest and Digital Signing Framework, a structured and security-aware extension of Model Context Protocols. The framework enforces cryptographically signed manifests, integrates transparent verification logs, and isolates model-internal execution metadata from user-visible components to ensure verifiable execution integrity. Furthermore, the evaluation demonstrates that the framework scales nearly linearly (R-squared = 0.998), achieves near-perfect acceptance of valid executions while consistently rejecting invalid ones, and maintains balanced model utilization across execution pipelines.
Prism: Dynamic and Flexible Benchmarking of LLMs Code Generation with Monte Carlo Tree Search
Apr 10, 2025The rapid advancement of Large Language Models (LLMs) has outpaced traditional evaluation methods. Static benchmarks fail to capture the depth and breadth of LLM capabilities and eventually become obsolete, while most dynamic approaches either rely too heavily on LLM-based evaluation or remain constrained by predefined test sets. We introduce Prism, a flexible, dynamic benchmarking framework designed for comprehensive LLM assessment. Prism builds on three key components: (1) a tree-based state representation that models evaluation as a Markov Decision Process, (2) a Monte Carlo Tree Search algorithm adapted to uncover challenging evaluation scenarios, and (3) a multi-agent evaluation pipeline that enables simultaneous assessment of diverse capabilities. To ensure robust evaluation, Prism integrates structural measurements of tree exploration patterns with performance metrics across difficulty levels, providing detailed diagnostics of error patterns, test coverage, and solution approaches. Through extensive experiments on five state-of-the-art LLMs, we analyze how model architecture and scale influence code generation performance across varying task difficulties. Our results demonstrate Prism's effectiveness as a dynamic benchmark that evolves with model advancements while offering deeper insights into their limitations.
An Efficient Model Maintenance Approach for MLOps
Dec 05, 2024In recent years, many industries have utilized machine learning models (ML) in their systems. Ideally, machine learning models should be trained on and applied to data from the same distributions. However, the data evolves over time in many application areas, leading to data and concept drift, which in turn causes the performance of the ML models to degrade over time. Therefore, maintaining up to date ML models plays a critical role in the MLOps pipeline. Existing ML model maintenance approaches are often computationally resource intensive, costly, time consuming, and model dependent. Thus, we propose an improved MLOps pipeline, a new model maintenance approach and a Similarity Based Model Reuse (SimReuse) tool to address the challenges of ML model maintenance. We identify seasonal and recurrent distribution patterns in time series datasets throughout a preliminary study. Recurrent distribution patterns enable us to reuse previously trained models for similar distributions in the future, thus avoiding frequent retraining. Then, we integrated the model reuse approach into the MLOps pipeline and proposed our improved MLOps pipeline. Furthermore, we develop SimReuse, a tool to implement the new components of our MLOps pipeline to store models and reuse them for inference of data segments with similar data distributions in the future. Our evaluation results on four time series datasets demonstrate that our model reuse approach can maintain the performance of models while significantly reducing maintenance time and costs. Our model reuse approach achieves ML performance comparable to the best baseline, while being 15 times more efficient in terms of computation time and costs. Therefore, industries and practitioners can benefit from our approach and use our tool to maintain the performance of their ML models in the deployment phase to reduce their maintenance costs.
Fault Localization in Deep Learning-based Software: A System-level Approach
Nov 12, 2024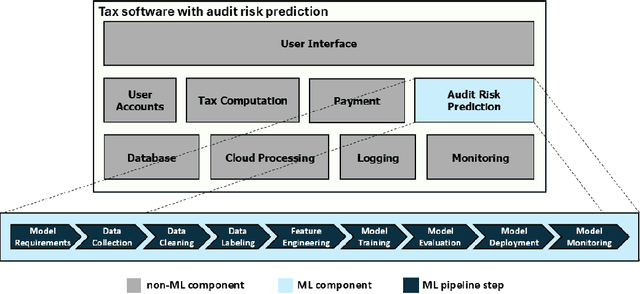

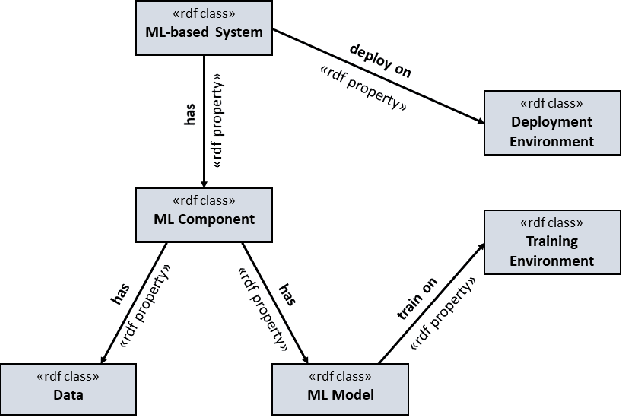
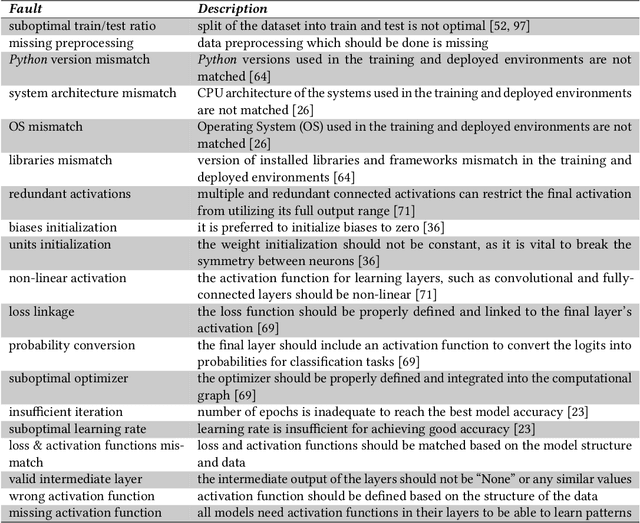
Over the past decade, Deep Learning (DL) has become an integral part of our daily lives. This surge in DL usage has heightened the need for developing reliable DL software systems. Given that fault localization is a critical task in reliability assessment, researchers have proposed several fault localization techniques for DL-based software, primarily focusing on faults within the DL model. While the DL model is central to DL components, there are other elements that significantly impact the performance of DL components. As a result, fault localization methods that concentrate solely on the DL model overlook a large portion of the system. To address this, we introduce FL4Deep, a system-level fault localization approach considering the entire DL development pipeline to effectively localize faults across the DL-based systems. In an evaluation using 100 faulty DL scripts, FL4Deep outperformed four previous approaches in terms of accuracy for three out of six DL-related faults, including issues related to data (84%), mismatched libraries between training and deployment (100%), and loss function (69%). Additionally, FL4Deep demonstrated superior precision and recall in fault localization for five categories of faults including three mentioned fault types in terms of accuracy, plus insufficient training iteration and activation function.
Toward Debugging Deep Reinforcement Learning Programs with RLExplorer
Oct 06, 2024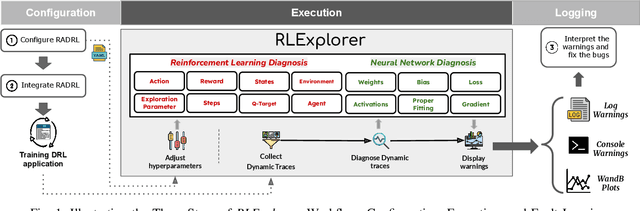
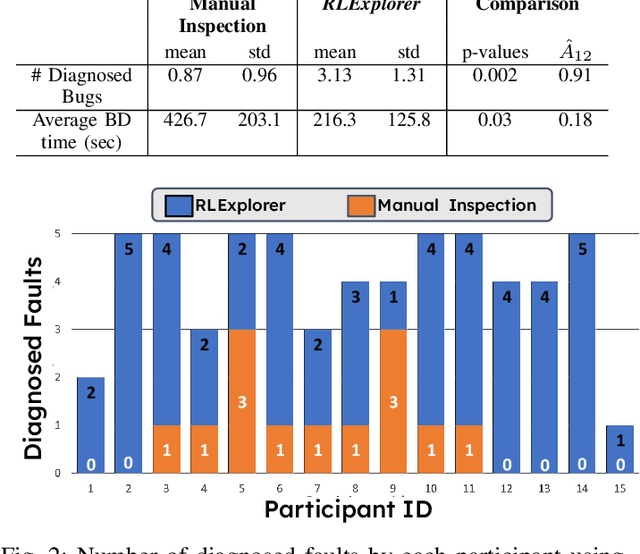
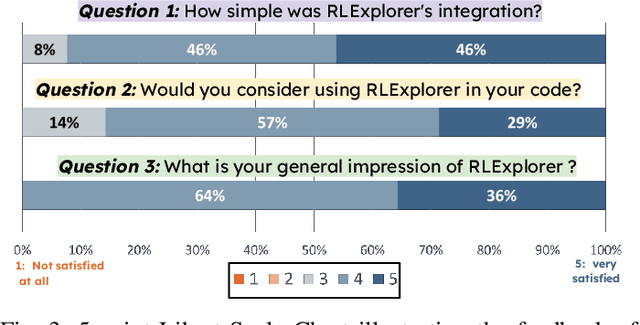
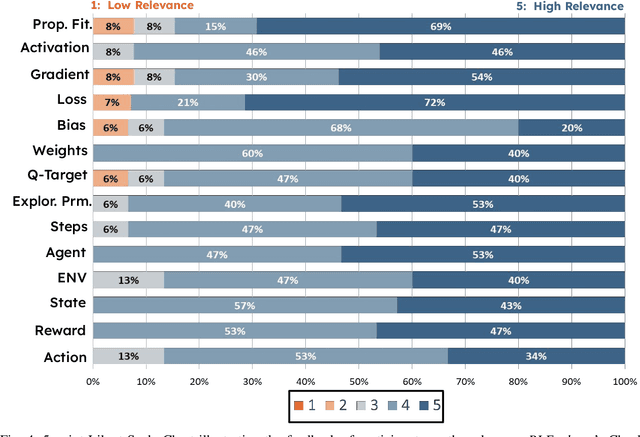
Deep reinforcement learning (DRL) has shown success in diverse domains such as robotics, computer games, and recommendation systems. However, like any other software system, DRL-based software systems are susceptible to faults that pose unique challenges for debugging and diagnosing. These faults often result in unexpected behavior without explicit failures and error messages, making debugging difficult and time-consuming. Therefore, automating the monitoring and diagnosis of DRL systems is crucial to alleviate the burden on developers. In this paper, we propose RLExplorer, the first fault diagnosis approach for DRL-based software systems. RLExplorer automatically monitors training traces and runs diagnosis routines based on properties of the DRL learning dynamics to detect the occurrence of DRL-specific faults. It then logs the results of these diagnoses as warnings that cover theoretical concepts, recommended practices, and potential solutions to the identified faults. We conducted two sets of evaluations to assess RLExplorer. Our first evaluation of faulty DRL samples from Stack Overflow revealed that our approach can effectively diagnose real faults in 83% of the cases. Our second evaluation of RLExplorer with 15 DRL experts/developers showed that (1) RLExplorer could identify 3.6 times more defects than manual debugging and (2) RLExplorer is easily integrated into DRL applications.
Assessing Programming Task Difficulty for Efficient Evaluation of Large Language Models
Jul 30, 2024



Large Language Models (LLMs) show promising potential in Software Engineering, especially for code-related tasks like code completion and code generation. LLMs' evaluation is generally centred around general metrics computed over benchmarks. While painting a macroscopic view of the benchmarks and of the LLMs' capacity, it is unclear how each programming task in these benchmarks assesses the capabilities of the LLMs. In particular, the difficulty level of the tasks in the benchmarks is not reflected in the score used to report the performance of the model. Yet, a model achieving a 90% score on a benchmark of predominantly easy tasks is likely less capable than a model achieving a 90% score on a benchmark containing predominantly difficult tasks. This paper devises a framework, HardEval, for assessing task difficulty for LLMs and crafting new tasks based on identified hard tasks. The framework uses a diverse array of prompts for a single task across multiple LLMs to obtain a difficulty score for each task of a benchmark. Using two code generation benchmarks, HumanEval+ and ClassEval, we show that HardEval can reliably identify the hard tasks within those benchmarks, highlighting that only 21% of HumanEval+ and 27% of ClassEval tasks are hard for LLMs. Through our analysis of task difficulty, we also characterize 6 practical hard task topics which we used to generate new hard tasks. Orthogonal to current benchmarking evaluation efforts, HardEval can assist researchers and practitioners in fostering better assessments of LLMs. The difficulty score can be used to identify hard tasks within existing benchmarks. This, in turn, can be leveraged to generate more hard tasks centred around specific topics either for evaluation or improvement of LLMs. HardEval generalistic approach can be applied to other domains such as code completion or Q/A.
DeepCodeProbe: Towards Understanding What Models Trained on Code Learn
Jul 11, 2024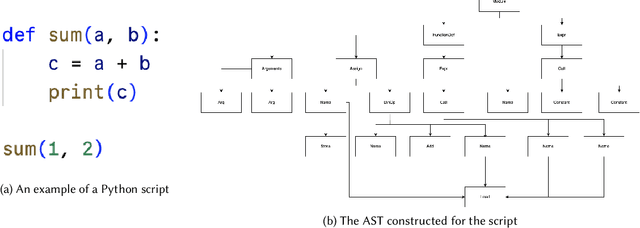
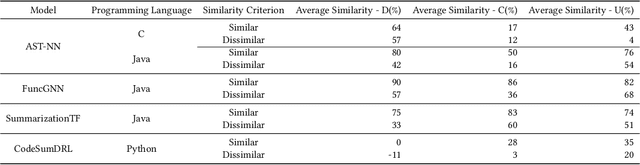
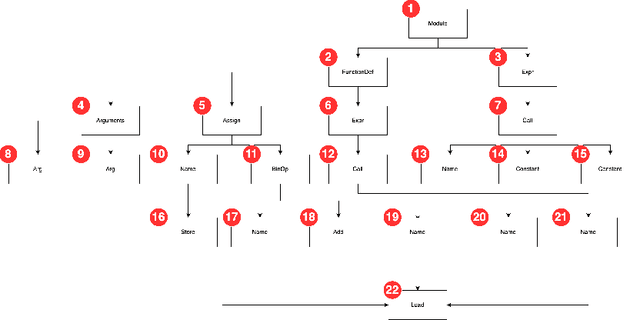
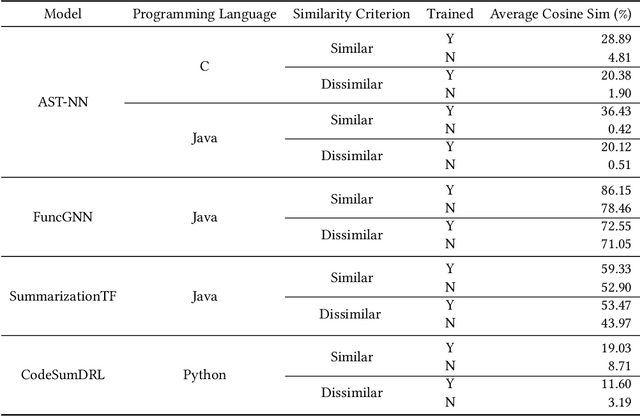
Machine learning models trained on code and related artifacts offer valuable support for software maintenance but suffer from interpretability issues due to their complex internal variables. These concerns are particularly significant in safety-critical applications where the models' decision-making processes must be reliable. The specific features and representations learned by these models remain unclear, adding to the hesitancy in adopting them widely. To address these challenges, we introduce DeepCodeProbe, a probing approach that examines the syntax and representation learning abilities of ML models designed for software maintenance tasks. Our study applies DeepCodeProbe to state-of-the-art models for code clone detection, code summarization, and comment generation. Findings reveal that while small models capture abstract syntactic representations, their ability to fully grasp programming language syntax is limited. Increasing model capacity improves syntax learning but introduces trade-offs such as increased training time and overfitting. DeepCodeProbe also identifies specific code patterns the models learn from their training data. Additionally, we provide best practices for training models on code to enhance performance and interpretability, supported by an open-source replication package for broader application of DeepCodeProbe in interpreting other code-related models.
Introducing v0.5 of the AI Safety Benchmark from MLCommons
Apr 18, 2024



This paper introduces v0.5 of the AI Safety Benchmark, which has been created by the MLCommons AI Safety Working Group. The AI Safety Benchmark has been designed to assess the safety risks of AI systems that use chat-tuned language models. We introduce a principled approach to specifying and constructing the benchmark, which for v0.5 covers only a single use case (an adult chatting to a general-purpose assistant in English), and a limited set of personas (i.e., typical users, malicious users, and vulnerable users). We created a new taxonomy of 13 hazard categories, of which 7 have tests in the v0.5 benchmark. We plan to release version 1.0 of the AI Safety Benchmark by the end of 2024. The v1.0 benchmark will provide meaningful insights into the safety of AI systems. However, the v0.5 benchmark should not be used to assess the safety of AI systems. We have sought to fully document the limitations, flaws, and challenges of v0.5. This release of v0.5 of the AI Safety Benchmark includes (1) a principled approach to specifying and constructing the benchmark, which comprises use cases, types of systems under test (SUTs), language and context, personas, tests, and test items; (2) a taxonomy of 13 hazard categories with definitions and subcategories; (3) tests for seven of the hazard categories, each comprising a unique set of test items, i.e., prompts. There are 43,090 test items in total, which we created with templates; (4) a grading system for AI systems against the benchmark; (5) an openly available platform, and downloadable tool, called ModelBench that can be used to evaluate the safety of AI systems on the benchmark; (6) an example evaluation report which benchmarks the performance of over a dozen openly available chat-tuned language models; (7) a test specification for the benchmark.
Bugs in Large Language Models Generated Code: An Empirical Study
Mar 18, 2024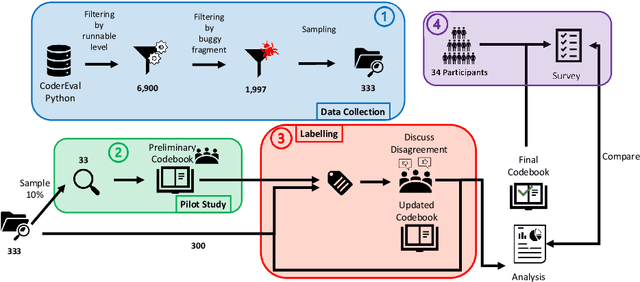

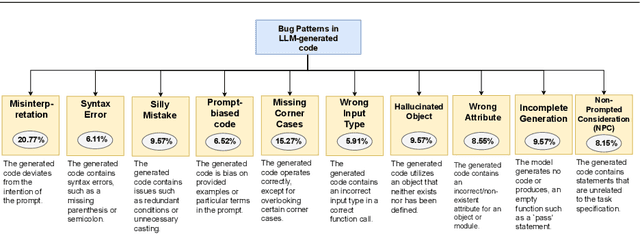

Large Language Models (LLMs) for code have gained significant attention recently. They can generate code in different programming languages based on provided prompts, fulfilling a long-lasting dream in Software Engineering (SE), i.e., automatic code generation. Similar to human-written code, LLM-generated code is prone to bugs, and these bugs have not yet been thoroughly examined by the community. Given the increasing adoption of LLM-based code generation tools (e.g., GitHub Copilot) in SE activities, it is critical to understand the characteristics of bugs contained in code generated by LLMs. This paper examines a sample of 333 bugs collected from code generated using three leading LLMs (i.e., CodeGen, PanGu-Coder, and Codex) and identifies the following 10 distinctive bug patterns: Misinterpretations, Syntax Error, Silly Mistake, Prompt-biased code, Missing Corner Case, Wrong Input Type, Hallucinated Object, Wrong Attribute, Incomplete Generation, and Non-Prompted Consideration. The bug patterns are presented in the form of a taxonomy. The identified bug patterns are validated using an online survey with 34 LLM practitioners and researchers. The surveyed participants generally asserted the significance and prevalence of the bug patterns. Researchers and practitioners can leverage these findings to develop effective quality assurance techniques for LLM-generated code. This study sheds light on the distinctive characteristics of LLM-generated code.
Trained Without My Consent: Detecting Code Inclusion In Language Models Trained on Code
Feb 14, 2024


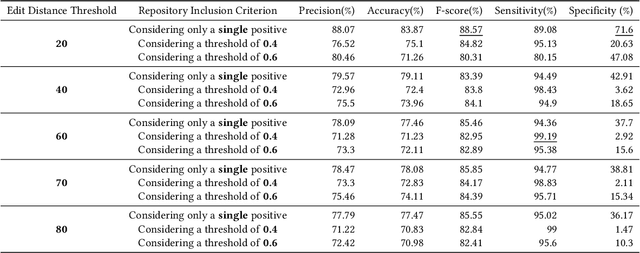
Code auditing ensures that the developed code adheres to standards, regulations, and copyright protection by verifying that it does not contain code from protected sources. The recent advent of Large Language Models (LLMs) as coding assistants in the software development process poses new challenges for code auditing. The dataset for training these models is mainly collected from publicly available sources. This raises the issue of intellectual property infringement as developers' codes are already included in the dataset. Therefore, auditing code developed using LLMs is challenging, as it is difficult to reliably assert if an LLM used during development has been trained on specific copyrighted codes, given that we do not have access to the training datasets of these models. Given the non-disclosure of the training datasets, traditional approaches such as code clone detection are insufficient for asserting copyright infringement. To address this challenge, we propose a new approach, TraWiC; a model-agnostic and interpretable method based on membership inference for detecting code inclusion in an LLM's training dataset. We extract syntactic and semantic identifiers unique to each program to train a classifier for detecting code inclusion. In our experiments, we observe that TraWiC is capable of detecting 83.87% of codes that were used to train an LLM. In comparison, the prevalent clone detection tool NiCad is only capable of detecting 47.64%. In addition to its remarkable performance, TraWiC has low resource overhead in contrast to pair-wise clone detection that is conducted during the auditing process of tools like CodeWhisperer reference tracker, across thousands of code snippets.