 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation Improvement in Latent Space for Search-Based Testing of Autonomous Robotic Systems
Mar 26, 2025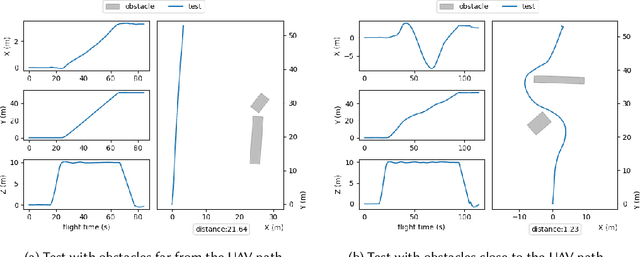
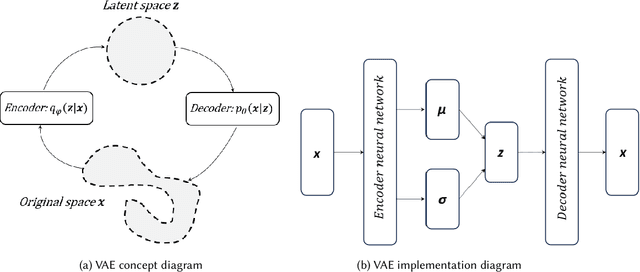

Testing autonomous robotic systems, such as self-driving cars and unmanned aerial vehicles, is challenging due to their interaction with highly unpredictable environments. A common practice is to first conduct simulation-based testing, which, despite reducing real-world risks, remains time-consuming and resource-intensive due to the vast space of possible test scenarios. A number of search-based approaches were proposed to generate test scenarios more efficiently. A key aspect of any search-based test generation approach is the choice of representation used during the search process. However, existing methods for improving test scenario representation remain limited. We propose RILaST (Representation Improvement in Latent Space for Search-Based Testing) approach, which enhances test representation by mapping it to the latent space of a variational autoencoder. We evaluate RILaST on two use cases, including autonomous drone and autonomous lane-keeping assist system. The obtained results show that RILaST allows finding between 3 to 4.6 times more failures than baseline approaches, achieving a high level of test diversity.
In-Simulation Testing of Deep Learning Vision Models in Autonomous Robotic Manipulators
Oct 25, 2024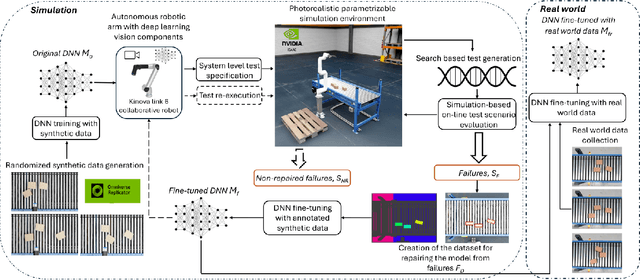


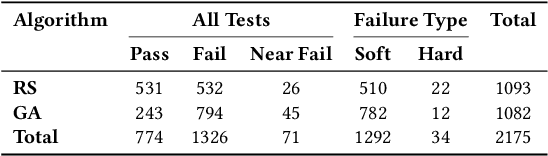
Testing autonomous robotic manipulators is challenging due to the complex software interactions between vision and control components. A crucial element of modern robotic manipulators is the deep learning based object detection model. The creation and assessment of this model requires real world data, which can be hard to label and collect, especially when the hardware setup is not available. The current techniques primarily focus on using synthetic data to train deep neural networks (DDNs) and identifying failures through offline or online simulation-based testing. However, the process of exploiting the identified failures to uncover design flaws early on, and leveraging the optimized DNN within the simulation to accelerate the engineering of the DNN for real-world tasks remains unclear. To address these challenges, we propose the MARTENS (Manipulator Robot Testing and Enhancement in Simulation) framework, which integrates a photorealistic NVIDIA Isaac Sim simulator with evolutionary search to identify critical scenarios aiming at improving the deep learning vision model and uncovering system design flaws. Evaluation of two industrial case studies demonstrated that MARTENS effectively reveals robotic manipulator system failures, detecting 25 % to 50 % more failures with greater diversity compared to random test generation. The model trained and repaired using the MARTENS approach achieved mean average precision (mAP) scores of 0.91 and 0.82 on real-world images with no prior retraining. Further fine-tuning on real-world images for a few epochs (less than 10) increased the mAP to 0.95 and 0.89 for the first and second use cases, respectively. In contrast, a model trained solely on real-world data achieved mAPs of 0.8 and 0.75 for use case 1 and use case 2 after more than 25 epochs.
Data Cleaning and Machine Learning: A Systematic Literature Review
Oct 03, 2023



Context: Machine Learning (ML) is integrated into a growing number of systems for various applications. Because the performance of an ML model is highly dependent on the quality of the data it has been trained on, there is a growing interest in approaches to detect and repair data errors (i.e., data cleaning). Researchers are also exploring how ML can be used for data cleaning; hence creating a dual relationship between ML and data cleaning. To the best of our knowledge, there is no study that comprehensively reviews this relationship. Objective: This paper's objectives are twofold. First, it aims to summarize the latest approaches for data cleaning for ML and ML for data cleaning. Second, it provides future work recommendations. Method: We conduct a systematic literature review of the papers published between 2016 and 2022 inclusively. We identify different types of data cleaning activities with and for ML: feature cleaning, label cleaning, entity matching, outlier detection, imputation, and holistic data cleaning. Results: We summarize the content of 101 papers covering various data cleaning activities and provide 24 future work recommendations. Our review highlights many promising data cleaning techniques that can be further extended. Conclusion: We believe that our review of the literature will help the community develop better approaches to clean data.
Reinforcement learning informed evolutionary search for autonomous systems testing
Aug 24, 2023Evolutionary search-based techniques are commonly used for testing autonomous robotic systems. However, these approaches often rely on computationally expensive simulator-based models for test scenario evaluation. To improve the computational efficiency of the search-based testing, we propose augmenting the evolutionary search (ES) with a reinforcement learning (RL) agent trained using surrogate rewards derived from domain knowledge. In our approach, known as RIGAA (Reinforcement learning Informed Genetic Algorithm for Autonomous systems testing), we first train an RL agent to learn useful constraints of the problem and then use it to produce a certain part of the initial population of the search algorithm. By incorporating an RL agent into the search process, we aim to guide the algorithm towards promising regions of the search space from the start, enabling more efficient exploration of the solution space. We evaluate RIGAA on two case studies: maze generation for an autonomous ant robot and road topology generation for an autonomous vehicle lane keeping assist system. In both case studies, RIGAA converges faster to fitter solutions and produces a better test suite (in terms of average test scenario fitness and diversity). RIGAA also outperforms the state-of-the-art tools for vehicle lane keeping assist system testing, such as AmbieGen and Frenetic.
AmbieGen: A Search-based Framework for Autonomous Systems Testing
Jan 01, 2023
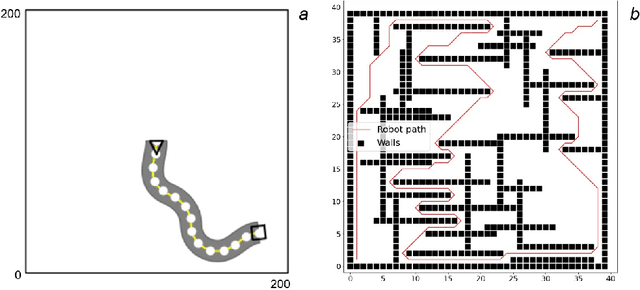
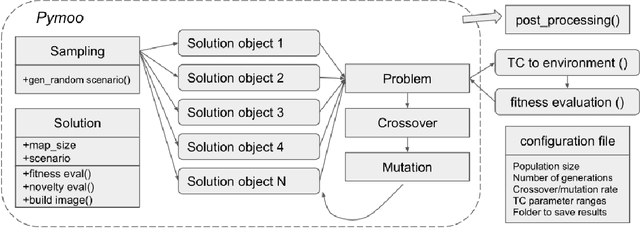
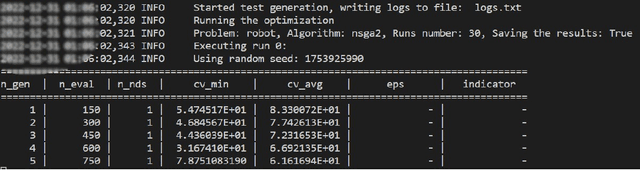
Thorough testing of safety-critical autonomous systems, such as self-driving cars, autonomous robots, and drones, is essential for detecting potential failures before deployment. One crucial testing stage is model-in-the-loop testing, where the system model is evaluated by executing various scenarios in a simulator. However, the search space of possible parameters defining these test scenarios is vast, and simulating all combinations is computationally infeasible. To address this challenge, we introduce AmbieGen, a search-based test case generation framework for autonomous systems. AmbieGen uses evolutionary search to identify the most critical scenarios for a given system, and has a modular architecture that allows for the addition of new systems under test, algorithms, and search operators. Currently, AmbieGen supports test case generation for autonomous robots and autonomous car lane keeping assist systems. In this paper, we provide a high-level overview of the framework's architecture and demonstrate its practical use cases.
A Search-Based Framework for Automatic Generation of Testing Environments for Cyber-Physical Systems
Mar 23, 2022
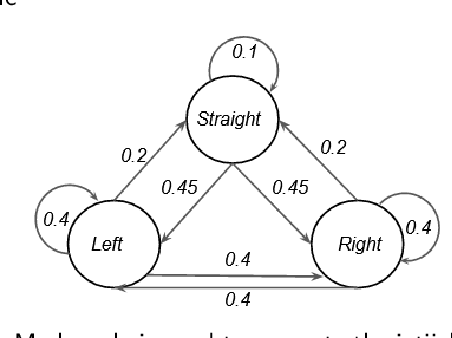
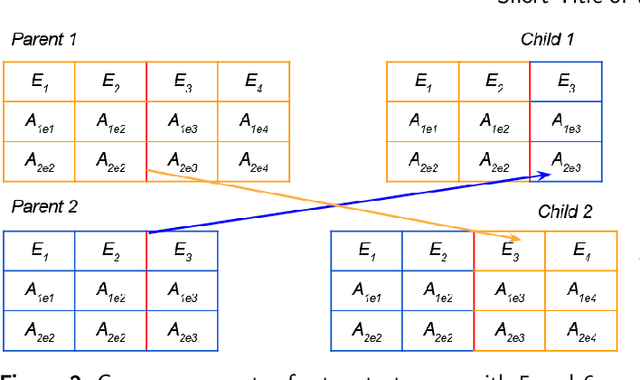
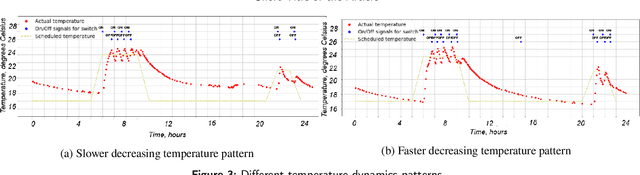
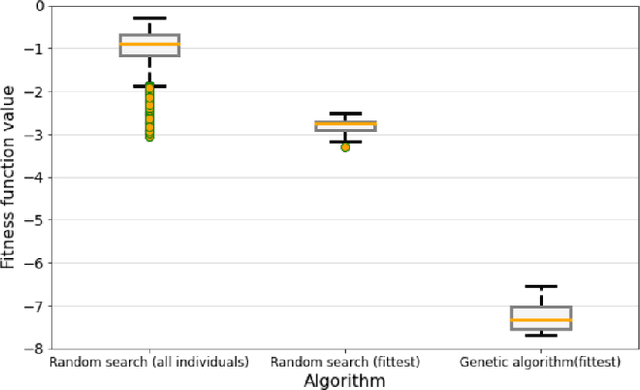
Many modern cyber physical systems incorporate computer vision technologies, complex sensors and advanced control software, allowing them to interact with the environment autonomously. Testing such systems poses numerous challenges: not only should the system inputs be varied, but also the surrounding environment should be accounted for. A number of tools have been developed to test the system model for the possible inputs falsifying its requirements. However, they are not directly applicable to autonomous cyber physical systems, as the inputs to their models are generated while operating in a virtual environment. In this paper, we aim to design a search based framework, named AmbieGen, for generating diverse fault revealing test scenarios for autonomous cyber physical systems. The scenarios represent an environment in which an autonomous agent operates. The framework should be applicable to generating different types of environments. To generate the test scenarios, we leverage the NSGA II algorithm with two objectives. The first objective evaluates the deviation of the observed system behaviour from its expected behaviour. The second objective is the test case diversity, calculated as a Jaccard distance with a reference test case. We evaluate AmbieGen on three scenario generation case studies, namely a smart-thermostat, a robot obstacle avoidance system, and a vehicle lane keeping assist system. We compared three configurations of AmbieGen: based on a single objective genetic algorithm, multi objective, and random search. Both single and multi objective configurations outperform the random search. Multi objective configuration can find the individuals of the same quality as the single objective, producing more unique test scenarios in the same time budget.
Data Driven Testing of Cyber Physical Systems
Feb 23, 2021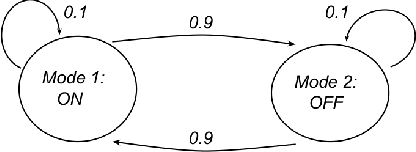

Consumer grade cyber-physical systems are becoming an integral part of our life, automatizing and simplifying everyday tasks; they are almost always capable of connection to the network allowing remote monitoring and programming. They rely on powerful programming languages, cloud infrastructures, and ultimately on complex software stacks. Indeed, due to complex interactions between hardware, networking and software, developing and testing such systems is known to be a challenging task. Ensuring properties such as dependability, security or data confidentiality is far from obvious. Various quality assurance and testing strategies have been proposed. The most common approach for pre-deployment testing is to model the system and run simulations with models or software in the loop. In practice, most often, tests are run for a small number of simulations, which are selected based on the engineers' domain knowledge and experience. We have implemented our approach in Python, using standard frameworks and used it to generate scenarios violating temperature constraints for a smart thermostat implemented as a part of our IoT testbed. Data collected from an application managing a smart building have been used to learn models of the environment under ever changing conditions. The suggested approach allowed us to identify several pit-fails, scenarios (i.e. environment conditions), where the system behaves not as expected.