 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Simulation Testing of Deep Learning Vision Models in Autonomous Robotic Manipulators
Oct 25, 2024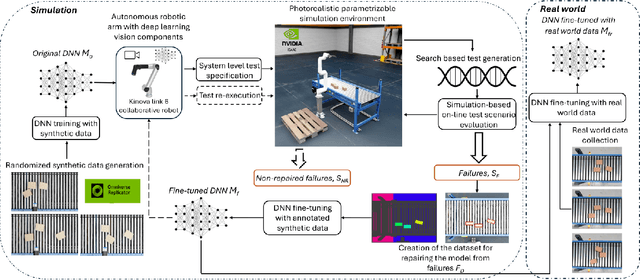


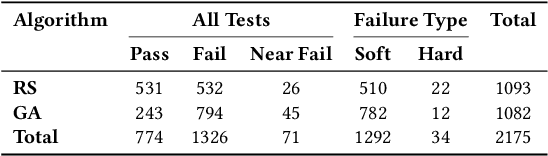
Testing autonomous robotic manipulators is challenging due to the complex software interactions between vision and control components. A crucial element of modern robotic manipulators is the deep learning based object detection model. The creation and assessment of this model requires real world data, which can be hard to label and collect, especially when the hardware setup is not available. The current techniques primarily focus on using synthetic data to train deep neural networks (DDNs) and identifying failures through offline or online simulation-based testing. However, the process of exploiting the identified failures to uncover design flaws early on, and leveraging the optimized DNN within the simulation to accelerate the engineering of the DNN for real-world tasks remains unclear. To address these challenges, we propose the MARTENS (Manipulator Robot Testing and Enhancement in Simulation) framework, which integrates a photorealistic NVIDIA Isaac Sim simulator with evolutionary search to identify critical scenarios aiming at improving the deep learning vision model and uncovering system design flaws. Evaluation of two industrial case studies demonstrated that MARTENS effectively reveals robotic manipulator system failures, detecting 25 % to 50 % more failures with greater diversity compared to random test generation. The model trained and repaired using the MARTENS approach achieved mean average precision (mAP) scores of 0.91 and 0.82 on real-world images with no prior retraining. Further fine-tuning on real-world images for a few epochs (less than 10) increased the mAP to 0.95 and 0.89 for the first and second use cases, respectively. In contrast, a model trained solely on real-world data achieved mAPs of 0.8 and 0.75 for use case 1 and use case 2 after more than 25 epochs.
Trimming the Risk: Towards Reliable Continuous Training for Deep Learning Inspection Systems
Sep 13, 2024



The industry increasingly relies on deep learning (DL) technology for manufacturing inspections, which are challenging to automate with rule-based machine vision algorithms. DL-powered inspection systems derive defect patterns from labeled images, combining human-like agility with the consistency of a computerized system. However, finite labeled datasets often fail to encompass all natural variations necessitating Continuous Training (CT) to regularly adjust their models with recent data. Effective CT requires fresh labeled samples from the original distribution; otherwise, selfgenerated labels can lead to silent performance degradation. To mitigate this risk, we develop a robust CT-based maintenance approach that updates DL models using reliable data selections through a two-stage filtering process. The initial stage filters out low-confidence predictions, as the model inherently discredits them. The second stage uses variational auto-encoders and histograms to generate image embeddings that capture latent and pixel characteristics, then rejects the inputs of substantially shifted embeddings as drifted data with erroneous overconfidence. Then, a fine-tuning of the original DL model is executed on the filtered inputs while validating on a mixture of recent production and original datasets. This strategy mitigates catastrophic forgetting and ensures the model adapts effectively to new operational conditions. Evaluations on industrial inspection systems for popsicle stick prints and glass bottles using critical real-world datasets showed less than 9% of erroneous self-labeled data are retained after filtering and used for fine-tuning, improving model performance on production data by up to 14% without compromising its results on original validation data.
Machine Learning Robustness: A Primer
Apr 01, 2024This chapter explores the foundational concept of robustness in Machine Learning (ML) and its integral role in establishing trustworthiness in Artificial Intelligence (AI) systems. The discussion begins with a detailed definition of robustness, portraying it as the ability of ML models to maintain stable performance across varied and unexpected environmental conditions. ML robustness is dissected through several lenses: its complementarity with generalizability; its status as a requirement for trustworthy AI; its adversarial vs non-adversarial aspects; its quantitative metrics; and its indicators such as reproducibility and explainability. The chapter delves into the factors that impede robustness, such as data bias, model complexity, and the pitfalls of underspecified ML pipelines. It surveys key techniques for robustness assessment from a broad perspective, including adversarial attacks, encompassing both digital and physical realms. It covers non-adversarial data shifts and nuances of Deep Learning (DL) software testing methodologies. The discussion progresses to explore amelioration strategies for bolstering robustness, starting with data-centric approaches like debiasing and augmentation. Further examination includes a variety of model-centric methods such as transfer learning, adversarial training, and randomized smoothing. Lastly, post-training methods are discussed, including ensemble techniques, pruning, and model repairs, emerging as cost-effective strategies to make models more resilient against the unpredictable. This chapter underscores the ongoing challenges and limitations in estimating and achieving ML robustness by existing approaches. It offers insights and directions for future research on this crucial concept, as a prerequisite for trustworthy AI systems.
An Intentional Forgetting-Driven Self-Healing Method For Deep Reinforcement Learning Systems
Aug 23, 2023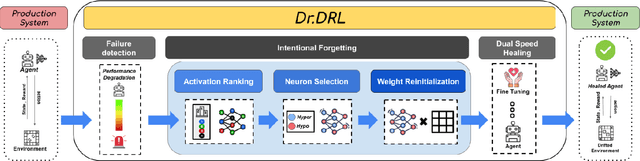
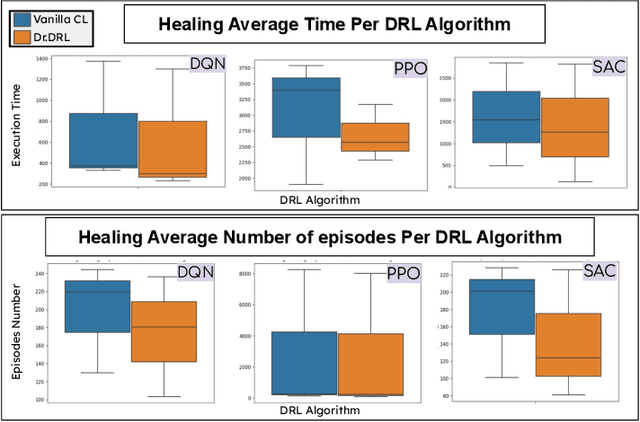
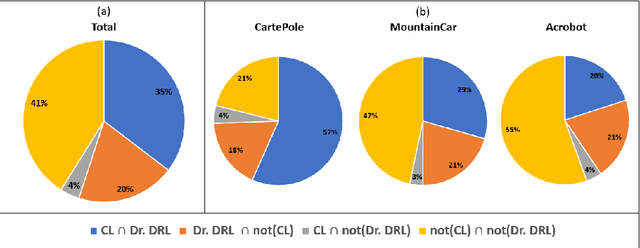
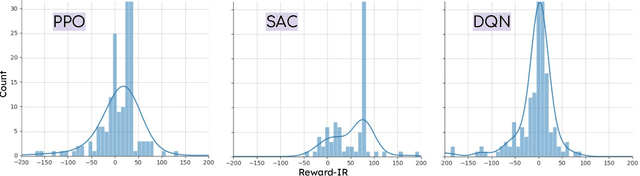
Deep reinforcement learning (DRL) is increasingly applied in large-scale productions like Netflix and Facebook. As with most data-driven systems, DRL systems can exhibit undesirable behaviors due to environmental drifts, which often occur in constantly-changing production settings. Continual Learning (CL) is the inherent self-healing approach for adapting the DRL agent in response to the environment's conditions shifts. However, successive shifts of considerable magnitude may cause the production environment to drift from its original state. Recent studies have shown that these environmental drifts tend to drive CL into long, or even unsuccessful, healing cycles, which arise from inefficiencies such as catastrophic forgetting, warm-starting failure, and slow convergence. In this paper, we propose Dr. DRL, an effective self-healing approach for DRL systems that integrates a novel mechanism of intentional forgetting into vanilla CL to overcome its main issues. Dr. DRL deliberately erases the DRL system's minor behaviors to systematically prioritize the adaptation of the key problem-solving skills. Using well-established DRL algorithms, Dr. DRL is compared with vanilla CL on various drifted environments. Dr. DRL is able to reduce, on average, the healing time and fine-tuning episodes by, respectively, 18.74% and 17.72%. Dr. DRL successfully helps agents to adapt to 19.63% of drifted environments left unsolved by vanilla CL while maintaining and even enhancing by up to 45% the obtained rewards for drifted environments that are resolved by both approaches.
SmOOD: Smoothness-based Out-of-Distribution Detection Approach for Surrogate Neural Networks in Aircraft Design
Sep 07, 2022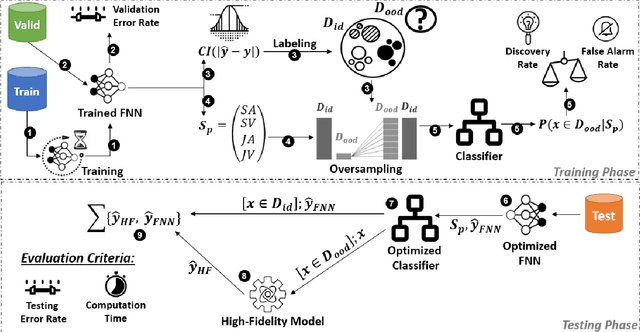

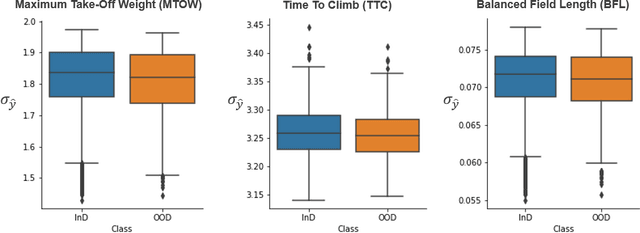
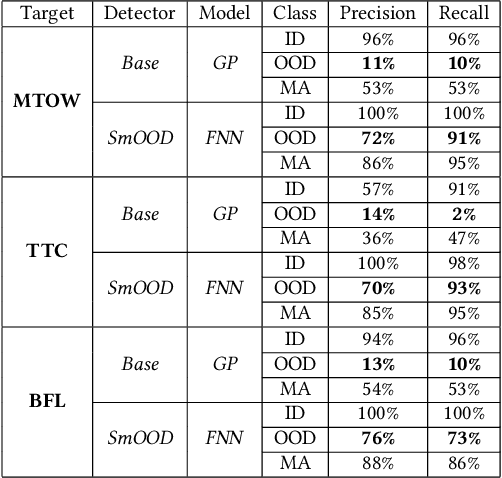
Aircraft industry is constantly striving for more efficient design optimization methods in terms of human efforts, computation time, and resource consumption. Hybrid surrogate optimization maintains high results quality while providing rapid design assessments when both the surrogate model and the switch mechanism for eventually transitioning to the HF model are calibrated properly. Feedforward neural networks (FNNs) can capture highly nonlinear input-output mappings, yielding efficient surrogates for aircraft performance factors. However, FNNs often fail to generalize over the out-of-distribution (OOD) samples, which hinders their adoption in critical aircraft design optimization. Through SmOOD, our smoothness-based out-of-distribution detection approach, we propose to codesign a model-dependent OOD indicator with the optimized FNN surrogate, to produce a trustworthy surrogate model with selective but credible predictions. Unlike conventional uncertainty-grounded methods, SmOOD exploits inherent smoothness properties of the HF simulations to effectively expose OODs through revealing their suspicious sensitivities, thereby avoiding over-confident uncertainty estimates on OOD samples. By using SmOOD, only high-risk OOD inputs are forwarded to the HF model for re-evaluation, leading to more accurate results at a low overhead cost. Three aircraft performance models are investigated. Results show that FNN-based surrogates outperform their Gaussian Process counterparts in terms of predictive performance. Moreover, SmOOD does cover averagely 85% of actual OODs on all the study cases. When SmOOD plus FNN surrogates are deployed in hybrid surrogate optimization settings, they result in a decrease error rate of 34.65% and a computational speed up rate of 58.36 times, respectively.
Physics-Guided Adversarial Machine Learning for Aircraft Systems Simulation
Sep 07, 2022
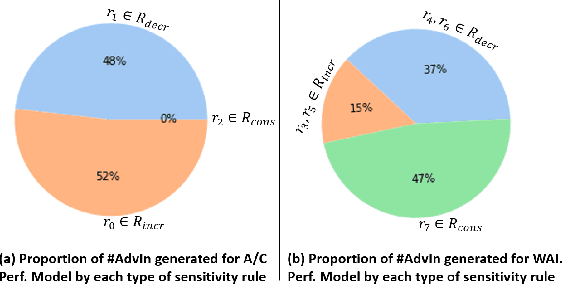

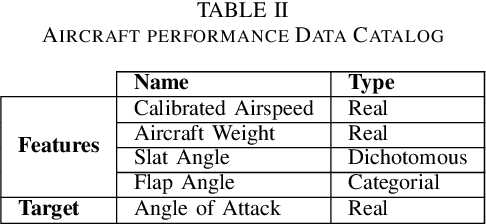
In the context of aircraft system performance assessment, deep learning technologies allow to quickly infer models from experimental measurements, with less detailed system knowledge than usually required by physics-based modeling. However, this inexpensive model development also comes with new challenges regarding model trustworthiness. This work presents a novel approach, physics-guided adversarial machine learning (ML), that improves the confidence over the physics consistency of the model. The approach performs, first, a physics-guided adversarial testing phase to search for test inputs revealing behavioral system inconsistencies, while still falling within the range of foreseeable operational conditions. Then, it proceeds with physics-informed adversarial training to teach the model the system-related physics domain foreknowledge through iteratively reducing the unwanted output deviations on the previously-uncovered counterexamples. Empirical evaluation on two aircraft system performance models shows the effectiveness of our adversarial ML approach in exposing physical inconsistencies of both models and in improving their propensity to be consistent with physics domain knowledge.
DiverGet: A Search-Based Software Testing Approach for Deep Neural Network Quantization Assessment
Jul 13, 2022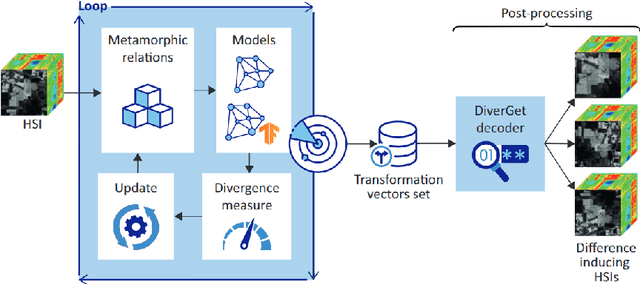
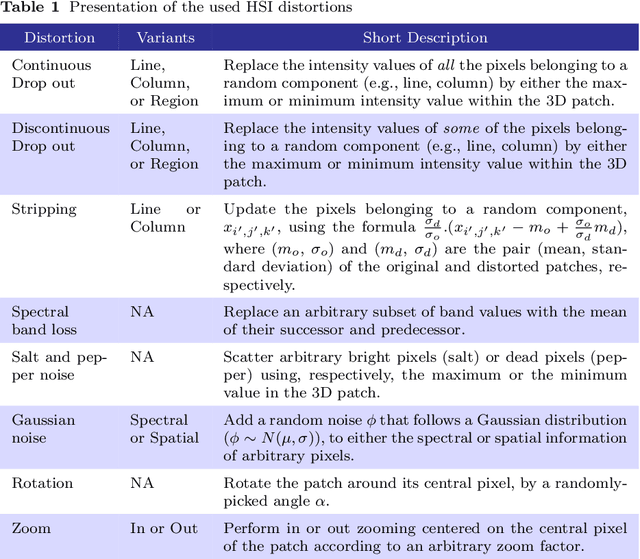
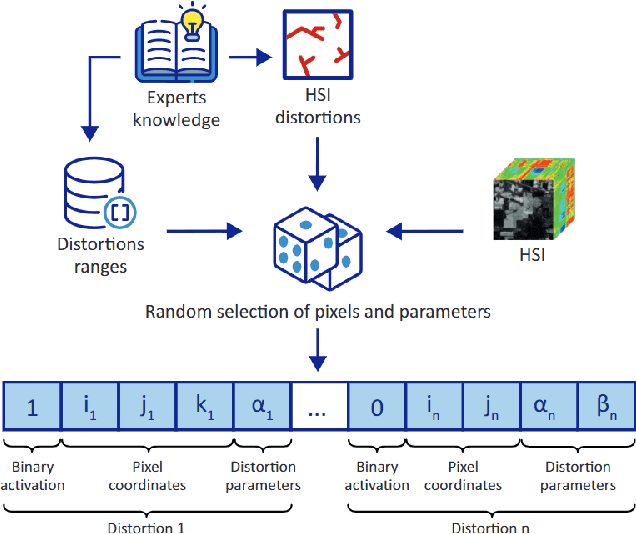
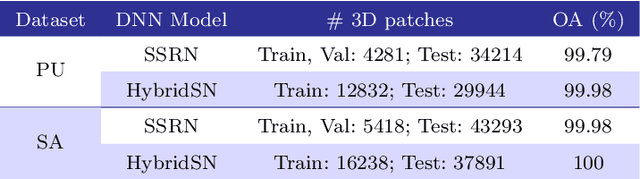
Quantization is one of the most applied Deep Neural Network (DNN) compression strategies, when deploying a trained DNN model on an embedded system or a cell phone. This is owing to its simplicity and adaptability to a wide range of applications and circumstances, as opposed to specific Artificial Intelligence (AI) accelerators and compilers that are often designed only for certain specific hardware (e.g., Google Coral Edge TPU). With the growing demand for quantization, ensuring the reliability of this strategy is becoming a critical challenge. Traditional testing methods, which gather more and more genuine data for better assessment, are often not practical because of the large size of the input space and the high similarity between the original DNN and its quantized counterpart. As a result, advanced assessment strategies have become of paramount importance. In this paper, we present DiverGet, a search-based testing framework for quantization assessment. DiverGet defines a space of metamorphic relations that simulate naturally-occurring distortions on the inputs. Then, it optimally explores these relations to reveal the disagreements among DNNs of different arithmetic precision. We evaluate the performance of DiverGet on state-of-the-art DNNs applied to hyperspectral remote sensing images. We chose the remote sensing DNNs as they're being increasingly deployed at the edge (e.g., high-lift drones) in critical domains like climate change research and astronomy. Our results show that DiverGet successfully challenges the robustness of established quantization techniques against naturally-occurring shifted data, and outperforms its most recent concurrent, DiffChaser, with a success rate that is (on average) four times higher.
Testing Feedforward Neural Networks Training Programs
Apr 01, 2022

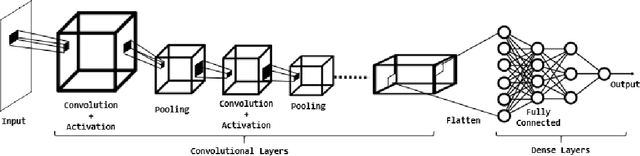
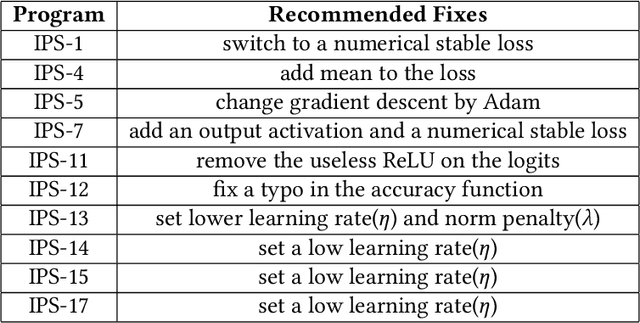
Nowadays, we are witnessing an increasing effort to improve the performance and trustworthiness of Deep Neural Networks (DNNs), with the aim to enable their adoption in safety critical systems such as self-driving cars. Multiple testing techniques are proposed to generate test cases that can expose inconsistencies in the behavior of DNN models. These techniques assume implicitly that the training program is bug-free and appropriately configured. However, satisfying this assumption for a novel problem requires significant engineering work to prepare the data, design the DNN, implement the training program, and tune the hyperparameters in order to produce the model for which current automated test data generators search for corner-case behaviors. All these model training steps can be error-prone. Therefore, it is crucial to detect and correct errors throughout all the engineering steps of DNN-based software systems and not only on the resulting DNN model. In this paper, we gather a catalog of training issues and based on their symptoms and their effects on the behavior of the training program, we propose practical verification routines to detect the aforementioned issues, automatically, by continuously validating that some important properties of the learning dynamics hold during the training. Then, we design, TheDeepChecker, an end-to-end property-based debugging approach for DNN training programs. We assess the effectiveness of TheDeepChecker on synthetic and real-world buggy DL programs and compare it with Amazon SageMaker Debugger (SMD). Results show that TheDeepChecker's on-execution validation of DNN-based program's properties succeeds in revealing several coding bugs and system misconfigurations, early on and at a low cost. Moreover, TheDeepChecker outperforms the SMD's offline rules verification on training logs in terms of detection accuracy and DL bugs coverage.
Models of Computational Profiles to Study the Likelihood of DNN Metamorphic Test Cases
Jul 28, 2021
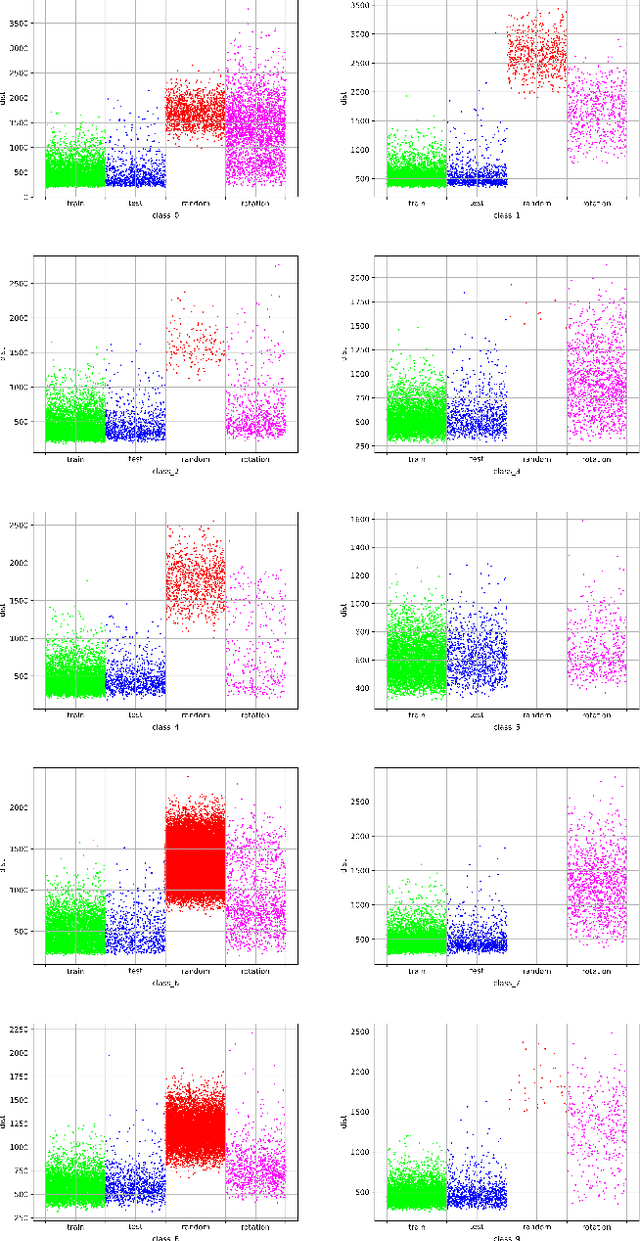

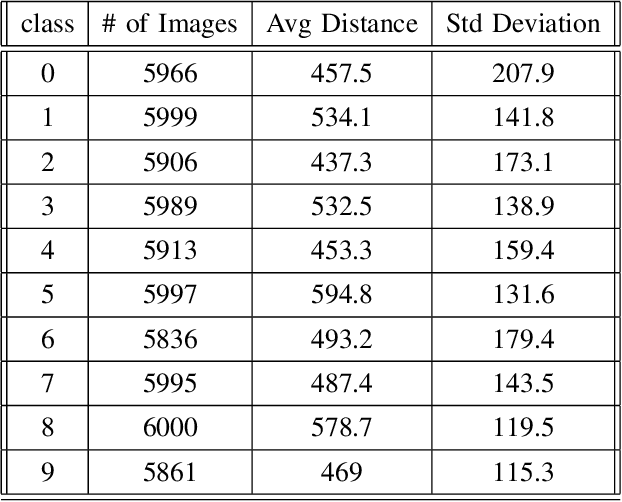
Neural network test cases are meant to exercise different reasoning paths in an architecture and used to validate the prediction outcomes. In this paper, we introduce "computational profiles" as vectors of neuron activation levels. We investigate the distribution of computational profile likelihood of metamorphic test cases with respect to the likelihood distributions of training, test and error control cases. We estimate the non-parametric probability densities of neuron activation levels for each distinct output class. Probabilities are inferred using training cases only, without any additional knowledge about metamorphic test cases. Experiments are performed by training a network on the MNIST Fashion library of images and comparing prediction likelihoods with those obtained from error control-data and from metamorphic test cases. Experimental results show that the distributions of computational profile likelihood for training and test cases are somehow similar, while the distribution of the random-noise control-data is always remarkably lower than the observed one for the training and testing sets. In contrast, metamorphic test cases show a prediction likelihood that lies in an extended range with respect to training, tests, and random noise. Moreover, the presented approach allows the independent assessment of different training classes and experiments to show that some of the classes are more sensitive to misclassifying metamorphic test cases than other classes. In conclusion, metamorphic test cases represent very aggressive tests for neural network architectures. Furthermore, since metamorphic test cases force a network to misclassify those inputs whose likelihood is similar to that of training cases, they could also be considered as adversarial attacks that evade defenses based on computational profile likelihood evaluation.
DeepEvolution: A Search-Based Testing Approach for Deep Neural Networks
Sep 05, 2019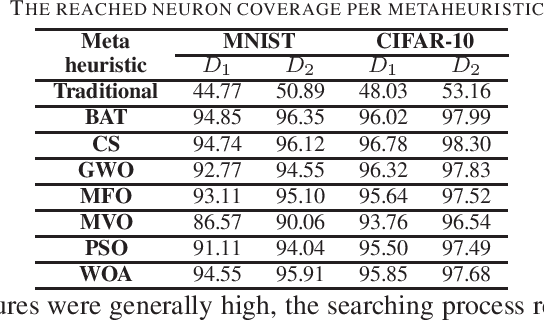

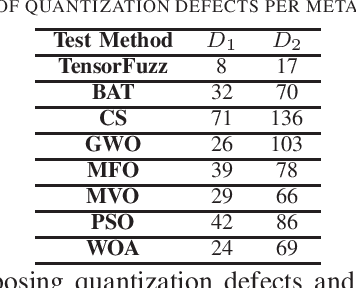
The increasing inclusion of Deep Learning (DL) models in safety-critical systems such as autonomous vehicles have led to the development of multiple model-based DL testing techniques. One common denominator of these testing techniques is the automated generation of test cases, e.g., new inputs transformed from the original training data with the aim to optimize some test adequacy criteria. So far, the effectiveness of these approaches has been hindered by their reliance on random fuzzing or transformations that do not always produce test cases with a good diversity. To overcome these limitations, we propose, DeepEvolution, a novel search-based approach for testing DL models that relies on metaheuristics to ensure a maximum diversity in generated test cases. We assess the effectiveness of DeepEvolution in testing computer-vision DL models and found that it significantly increases the neuronal coverage of generated test cases. Moreover, using DeepEvolution, we could successfully find several corner-case behaviors. Finally, DeepEvolution outperformed Tensorfuzz (a coverage-guided fuzzing tool developed at Google Brain) in detecting latent defects introduced during the quantization of the models. These results suggest that search-based approaches can help build effective testing tools for DL systems.