 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Debugging Deep Reinforcement Learning Programs with RLExplorer
Oct 06, 2024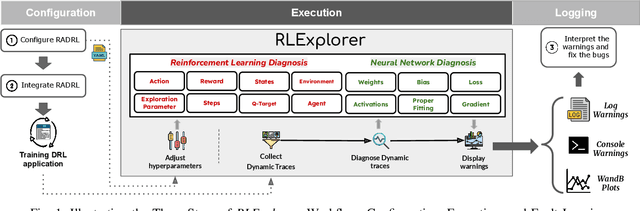
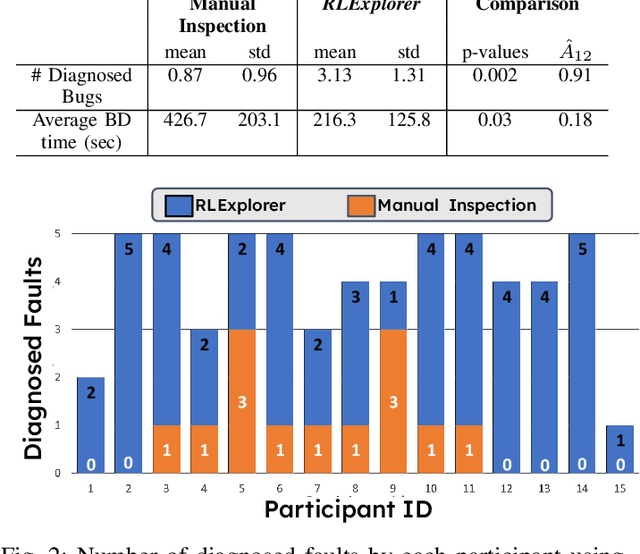
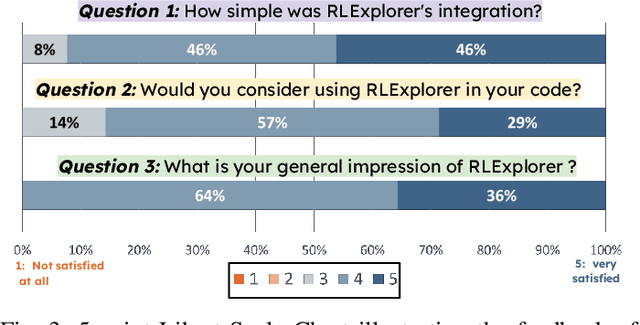
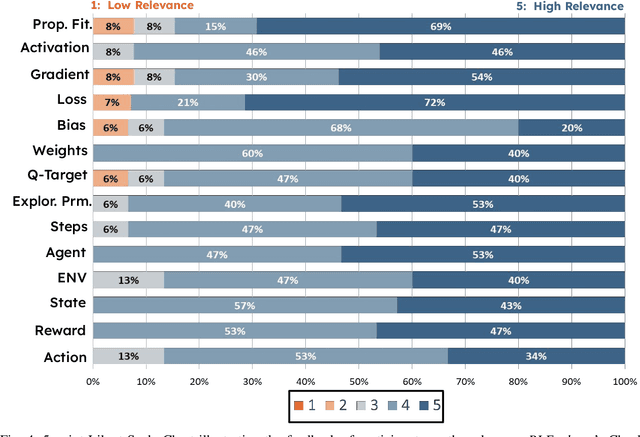
Deep reinforcement learning (DRL) has shown success in diverse domains such as robotics, computer games, and recommendation systems. However, like any other software system, DRL-based software systems are susceptible to faults that pose unique challenges for debugging and diagnosing. These faults often result in unexpected behavior without explicit failures and error messages, making debugging difficult and time-consuming. Therefore, automating the monitoring and diagnosis of DRL systems is crucial to alleviate the burden on developers. In this paper, we propose RLExplorer, the first fault diagnosis approach for DRL-based software systems. RLExplorer automatically monitors training traces and runs diagnosis routines based on properties of the DRL learning dynamics to detect the occurrence of DRL-specific faults. It then logs the results of these diagnoses as warnings that cover theoretical concepts, recommended practices, and potential solutions to the identified faults. We conducted two sets of evaluations to assess RLExplorer. Our first evaluation of faulty DRL samples from Stack Overflow revealed that our approach can effectively diagnose real faults in 83% of the cases. Our second evaluation of RLExplorer with 15 DRL experts/developers showed that (1) RLExplorer could identify 3.6 times more defects than manual debugging and (2) RLExplorer is easily integrated into DRL applications.
An Intentional Forgetting-Driven Self-Healing Method For Deep Reinforcement Learning Systems
Aug 23, 2023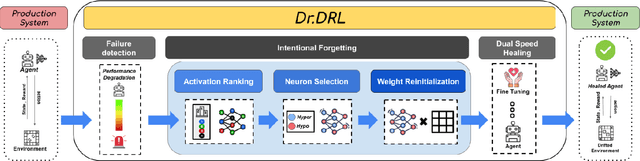
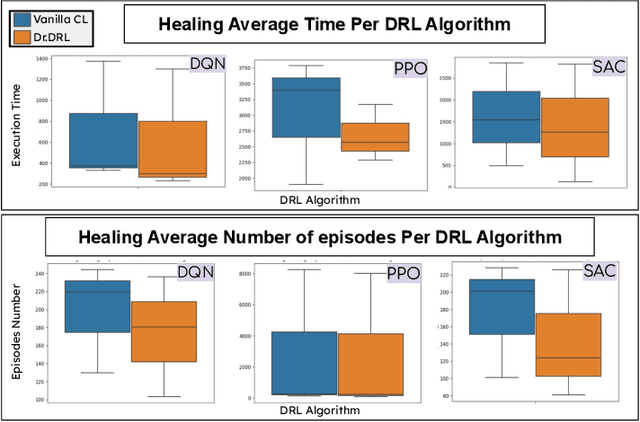
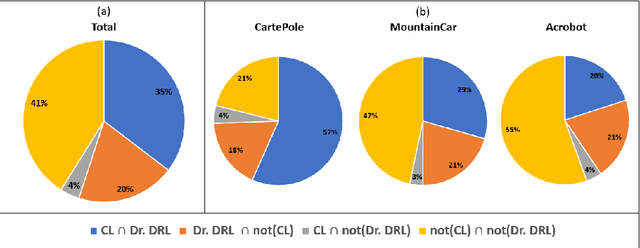
Deep reinforcement learning (DRL) is increasingly applied in large-scale productions like Netflix and Facebook. As with most data-driven systems, DRL systems can exhibit undesirable behaviors due to environmental drifts, which often occur in constantly-changing production settings. Continual Learning (CL) is the inherent self-healing approach for adapting the DRL agent in response to the environment's conditions shifts. However, successive shifts of considerable magnitude may cause the production environment to drift from its original state. Recent studies have shown that these environmental drifts tend to drive CL into long, or even unsuccessful, healing cycles, which arise from inefficiencies such as catastrophic forgetting, warm-starting failure, and slow convergence. In this paper, we propose Dr. DRL, an effective self-healing approach for DRL systems that integrates a novel mechanism of intentional forgetting into vanilla CL to overcome its main issues. Dr. DRL deliberately erases the DRL system's minor behaviors to systematically prioritize the adaptation of the key problem-solving skills. Using well-established DRL algorithms, Dr. DRL is compared with vanilla CL on various drifted environments. Dr. DRL is able to reduce, on average, the healing time and fine-tuning episodes by, respectively, 18.74% and 17.72%. Dr. DRL successfully helps agents to adapt to 19.63% of drifted environments left unsolved by vanilla CL while maintaining and even enhancing by up to 45% the obtained rewards for drifted environments that are resolved by both approaches.
Quality Issues in Machine Learning Software Systems
Jun 26, 2023Context: An increasing demand is observed in various domains to employ Machine Learning (ML) for solving complex problems. ML models are implemented as software components and deployed in Machine Learning Software Systems (MLSSs). Problem: There is a strong need for ensuring the serving quality of MLSSs. False or poor decisions of such systems can lead to malfunction of other systems, significant financial losses, or even threats to human life. The quality assurance of MLSSs is considered a challenging task and currently is a hot research topic. Objective: This paper aims to investigate the characteristics of real quality issues in MLSSs from the viewpoint of practitioners. This empirical study aims to identify a catalog of quality issues in MLSSs. Method: We conduct a set of interviews with practitioners/experts, to gather insights about their experience and practices when dealing with quality issues. We validate the identified quality issues via a survey with ML practitioners. Results: Based on the content of 37 interviews, we identified 18 recurring quality issues and 24 strategies to mitigate them. For each identified issue, we describe the causes and consequences according to the practitioners' experience. Conclusion: We believe the catalog of issues developed in this study will allow the community to develop efficient quality assurance tools for ML models and MLSSs. A replication package of our study is available on our public GitHub repository.
Can Ensembling Pre-processing Algorithms Lead to Better Machine Learning Fairness?
Dec 05, 2022As machine learning (ML) systems get adopted in more critical areas, it has become increasingly crucial to address the bias that could occur in these systems. Several fairness pre-processing algorithms are available to alleviate implicit biases during model training. These algorithms employ different concepts of fairness, often leading to conflicting strategies with consequential trade-offs between fairness and accuracy. In this work, we evaluate three popular fairness pre-processing algorithms and investigate the potential for combining all algorithms into a more robust pre-processing ensemble. We report on lessons learned that can help practitioners better select fairness algorithms for their models.
Quality issues in Machine Learning Software Systems
Aug 22, 2022Context: An increasing demand is observed in various domains to employ Machine Learning (ML) for solving complex problems. ML models are implemented as software components and deployed in Machine Learning Software Systems (MLSSs). Problem: There is a strong need for ensuring the serving quality of MLSSs. False or poor decisions of such systems can lead to malfunction of other systems, significant financial losses, or even threat to human life. The quality assurance of MLSSs is considered as a challenging task and currently is a hot research topic. Moreover, it is important to cover all various aspects of the quality in MLSSs. Objective: This paper aims to investigate the characteristics of real quality issues in MLSSs from the viewpoint of practitioners. This empirical study aims to identify a catalog of bad-practices related to poor quality in MLSSs. Method: We plan to conduct a set of interviews with practitioners/experts, believing that interviews are the best method to retrieve their experience and practices when dealing with quality issues. We expect that the catalog of issues developed at this step will also help us later to identify the severity, root causes, and possible remedy for quality issues of MLSSs, allowing us to develop efficient quality assurance tools for ML models and MLSSs.