 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStudying the Practices of Testing Machine Learning Software in the Wild
Dec 19, 2023
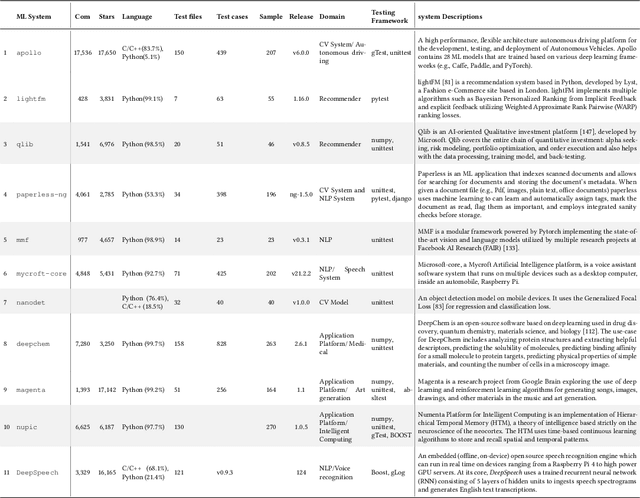
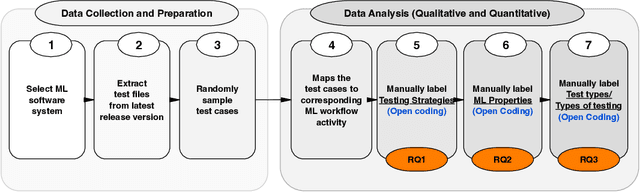

Background: We are witnessing an increasing adoption of machine learning (ML), especially deep learning (DL) algorithms in many software systems, including safety-critical systems such as health care systems or autonomous driving vehicles. Ensuring the software quality of these systems is yet an open challenge for the research community, mainly due to the inductive nature of ML software systems. Traditionally, software systems were constructed deductively, by writing down the rules that govern the behavior of the system as program code. However, for ML software, these rules are inferred from training data. Few recent research advances in the quality assurance of ML systems have adapted different concepts from traditional software testing, such as mutation testing, to help improve the reliability of ML software systems. However, it is unclear if any of these proposed testing techniques from research are adopted in practice. There is little empirical evidence about the testing strategies of ML engineers. Aims: To fill this gap, we perform the first fine-grained empirical study on ML testing practices in the wild, to identify the ML properties being tested, the followed testing strategies, and their implementation throughout the ML workflow. Method: First, we systematically summarized the different testing strategies (e.g., Oracle Approximation), the tested ML properties (e.g., Correctness, Bias, and Fairness), and the testing methods (e.g., Unit test) from the literature. Then, we conducted a study to understand the practices of testing ML software. Results: In our findings: 1) we identified four (4) major categories of testing strategy including Grey-box, White-box, Black-box, and Heuristic-based techniques that are used by the ML engineers to find software bugs. 2) We identified 16 ML properties that are tested in the ML workflow.
Quality Issues in Machine Learning Software Systems
Jun 26, 2023Context: An increasing demand is observed in various domains to employ Machine Learning (ML) for solving complex problems. ML models are implemented as software components and deployed in Machine Learning Software Systems (MLSSs). Problem: There is a strong need for ensuring the serving quality of MLSSs. False or poor decisions of such systems can lead to malfunction of other systems, significant financial losses, or even threats to human life. The quality assurance of MLSSs is considered a challenging task and currently is a hot research topic. Objective: This paper aims to investigate the characteristics of real quality issues in MLSSs from the viewpoint of practitioners. This empirical study aims to identify a catalog of quality issues in MLSSs. Method: We conduct a set of interviews with practitioners/experts, to gather insights about their experience and practices when dealing with quality issues. We validate the identified quality issues via a survey with ML practitioners. Results: Based on the content of 37 interviews, we identified 18 recurring quality issues and 24 strategies to mitigate them. For each identified issue, we describe the causes and consequences according to the practitioners' experience. Conclusion: We believe the catalog of issues developed in this study will allow the community to develop efficient quality assurance tools for ML models and MLSSs. A replication package of our study is available on our public GitHub repository.