 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracing Stereotypes in Pre-trained Transformers: From Biased Neurons to Fairer Models
Jan 09, 2026The advent of transformer-based language models has reshaped how AI systems process and generate text. In software engineering (SE), these models now support diverse activities, accelerating automation and decision-making. Yet, evidence shows that these models can reproduce or amplify social biases, raising fairness concerns. Recent work on neuron editing has shown that internal activations in pre-trained transformers can be traced and modified to alter model behavior. Building on the concept of knowledge neurons, neurons that encode factual information, we hypothesize the existence of biased neurons that capture stereotypical associations within pre-trained transformers. To test this hypothesis, we build a dataset of biased relations, i.e., triplets encoding stereotypes across nine bias types, and adapt neuron attribution strategies to trace and suppress biased neurons in BERT models. We then assess the impact of suppression on SE tasks. Our findings show that biased knowledge is localized within small neuron subsets, and suppressing them substantially reduces bias with minimal performance loss. This demonstrates that bias in transformers can be traced and mitigated at the neuron level, offering an interpretable approach to fairness in SE.
FairFLRep: Fairness aware fault localization and repair of Deep Neural Networks
Aug 11, 2025Deep neural networks (DNNs) are being utilized in various aspects of our daily lives, including high-stakes decision-making applications that impact individuals. However, these systems reflect and amplify bias from the data used during training and testing, potentially resulting in biased behavior and inaccurate decisions. For instance, having different misclassification rates between white and black sub-populations. However, effectively and efficiently identifying and correcting biased behavior in DNNs is a challenge. This paper introduces FairFLRep, an automated fairness-aware fault localization and repair technique that identifies and corrects potentially bias-inducing neurons in DNN classifiers. FairFLRep focuses on adjusting neuron weights associated with sensitive attributes, such as race or gender, that contribute to unfair decisions. By analyzing the input-output relationships within the network, FairFLRep corrects neurons responsible for disparities in predictive quality parity. We evaluate FairFLRep on four image classification datasets using two DNN classifiers, and four tabular datasets with a DNN model. The results show that FairFLRep consistently outperforms existing methods in improving fairness while preserving accuracy. An ablation study confirms the importance of considering fairness during both fault localization and repair stages. Our findings also show that FairFLRep is more efficient than the baseline approaches in repairing the network.
Studying the Practices of Testing Machine Learning Software in the Wild
Dec 19, 2023
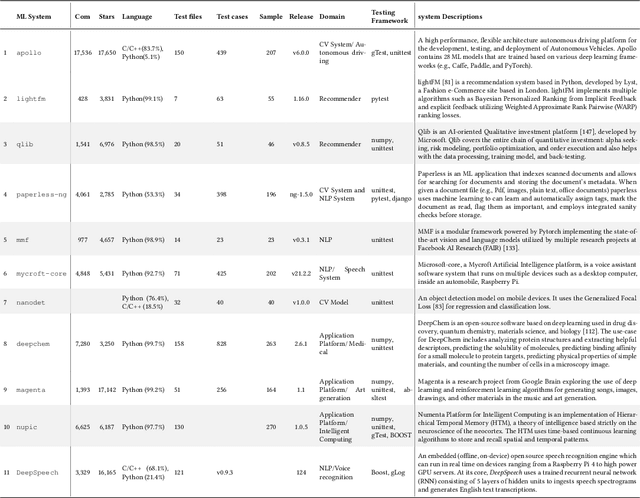
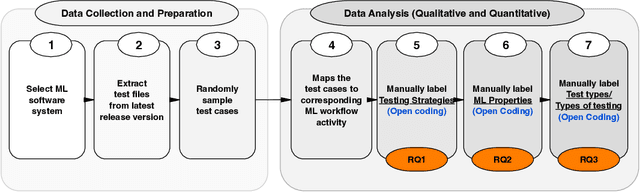

Background: We are witnessing an increasing adoption of machine learning (ML), especially deep learning (DL) algorithms in many software systems, including safety-critical systems such as health care systems or autonomous driving vehicles. Ensuring the software quality of these systems is yet an open challenge for the research community, mainly due to the inductive nature of ML software systems. Traditionally, software systems were constructed deductively, by writing down the rules that govern the behavior of the system as program code. However, for ML software, these rules are inferred from training data. Few recent research advances in the quality assurance of ML systems have adapted different concepts from traditional software testing, such as mutation testing, to help improve the reliability of ML software systems. However, it is unclear if any of these proposed testing techniques from research are adopted in practice. There is little empirical evidence about the testing strategies of ML engineers. Aims: To fill this gap, we perform the first fine-grained empirical study on ML testing practices in the wild, to identify the ML properties being tested, the followed testing strategies, and their implementation throughout the ML workflow. Method: First, we systematically summarized the different testing strategies (e.g., Oracle Approximation), the tested ML properties (e.g., Correctness, Bias, and Fairness), and the testing methods (e.g., Unit test) from the literature. Then, we conducted a study to understand the practices of testing ML software. Results: In our findings: 1) we identified four (4) major categories of testing strategy including Grey-box, White-box, Black-box, and Heuristic-based techniques that are used by the ML engineers to find software bugs. 2) We identified 16 ML properties that are tested in the ML workflow.
Detection and Evaluation of bias-inducing Features in Machine learning
Oct 19, 2023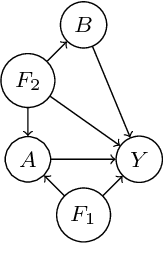
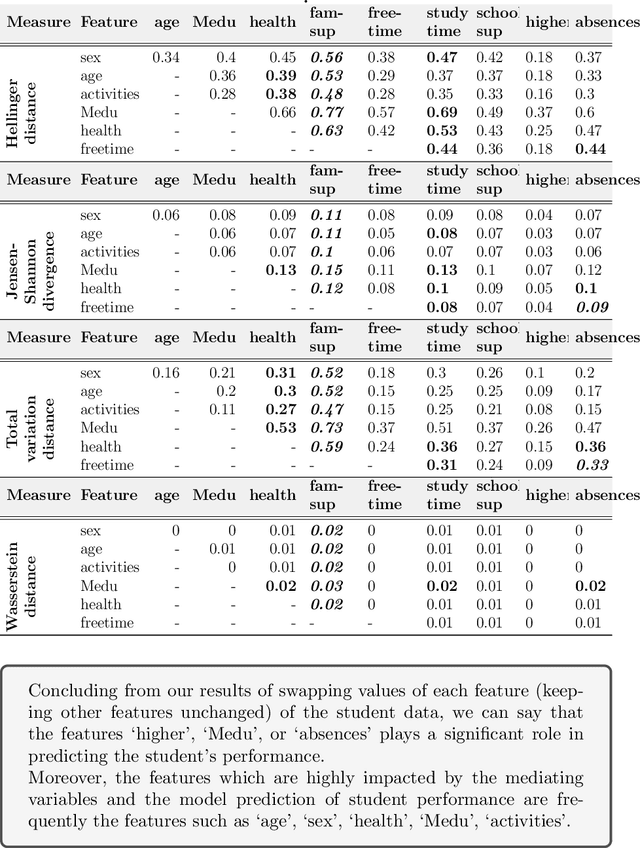
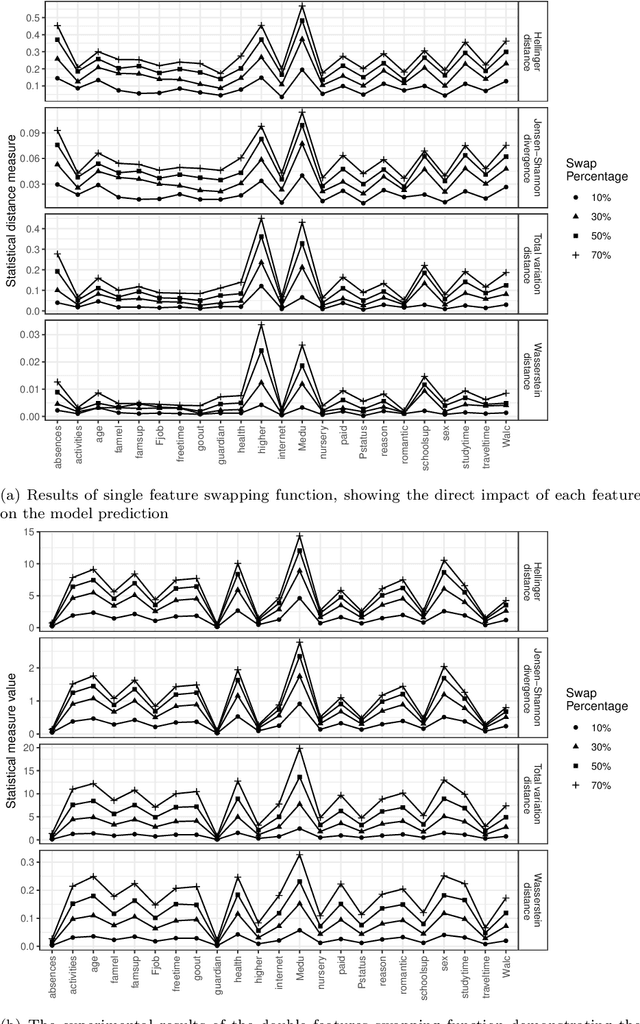
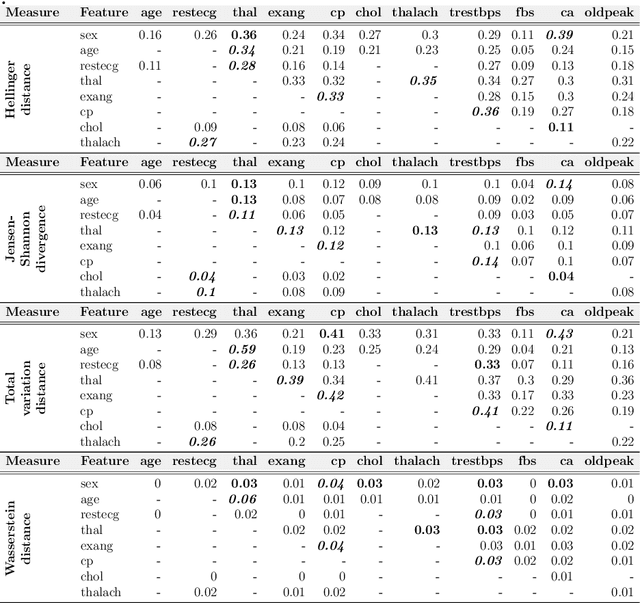
The cause-to-effect analysis can help us decompose all the likely causes of a problem, such as an undesirable business situation or unintended harm to the individual(s). This implies that we can identify how the problems are inherited, rank the causes to help prioritize fixes, simplify a complex problem and visualize them. In the context of machine learning (ML), one can use cause-to-effect analysis to understand the reason for the biased behavior of the system. For example, we can examine the root causes of biases by checking each feature for a potential cause of bias in the model. To approach this, one can apply small changes to a given feature or a pair of features in the data, following some guidelines and observing how it impacts the decision made by the model (i.e., model prediction). Therefore, we can use cause-to-effect analysis to identify the potential bias-inducing features, even when these features are originally are unknown. This is important since most current methods require a pre-identification of sensitive features for bias assessment and can actually miss other relevant bias-inducing features, which is why systematic identification of such features is necessary. Moreover, it often occurs that to achieve an equitable outcome, one has to take into account sensitive features in the model decision. Therefore, it should be up to the domain experts to decide based on their knowledge of the context of a decision whether bias induced by specific features is acceptable or not. In this study, we propose an approach for systematically identifying all bias-inducing features of a model to help support the decision-making of domain experts. We evaluated our technique using four well-known datasets to showcase how our contribution can help spearhead the standard procedure when developing, testing, maintaining, and deploying fair/equitable machine learning systems.
An Empirical Study on the Usage of Automated Machine Learning Tools
Aug 28, 2022
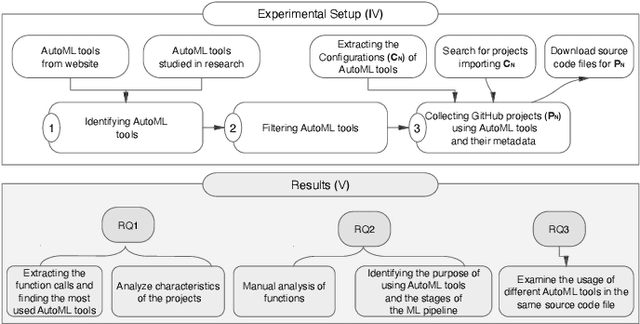

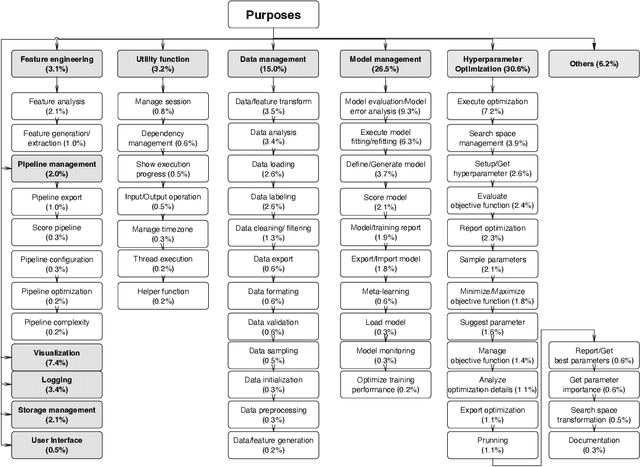
The popularity of automated machine learning (AutoML) tools in different domains has increased over the past few years. Machine learning (ML) practitioners use AutoML tools to automate and optimize the process of feature engineering, model training, and hyperparameter optimization and so on. Recent work performed qualitative studies on practitioners' experiences of using AutoML tools and compared different AutoML tools based on their performance and provided features, but none of the existing work studied the practices of using AutoML tools in real-world projects at a large scale. Therefore, we conducted an empirical study to understand how ML practitioners use AutoML tools in their projects. To this end, we examined the top 10 most used AutoML tools and their respective usages in a large number of open-source project repositories hosted on GitHub. The results of our study show 1) which AutoML tools are mostly used by ML practitioners and 2) the characteristics of the repositories that use these AutoML tools. Also, we identified the purpose of using AutoML tools (e.g. model parameter sampling, search space management, model evaluation/error-analysis, Data/ feature transformation, and data labeling) and the stages of the ML pipeline (e.g. feature engineering) where AutoML tools are used. Finally, we report how often AutoML tools are used together in the same source code files. We hope our results can help ML practitioners learn about different AutoML tools and their usages, so that they can pick the right tool for their purposes. Besides, AutoML tool developers can benefit from our findings to gain insight into the usages of their tools and improve their tools to better fit the users' usages and needs.
An Empirical Study of Challenges in Converting Deep Learning Models
Jun 28, 2022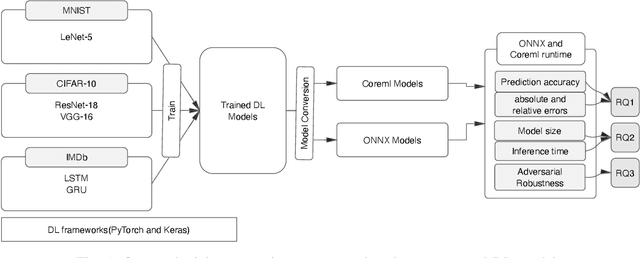
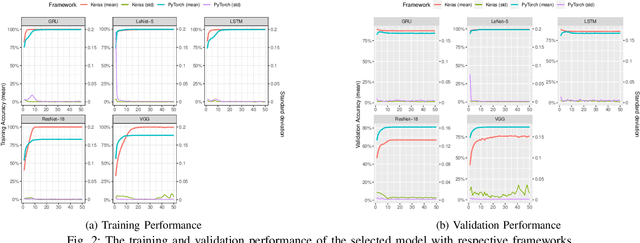
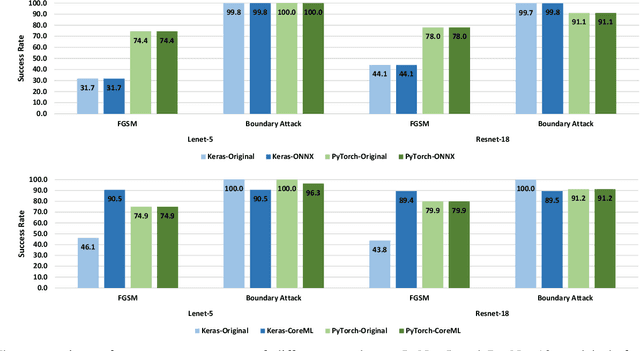
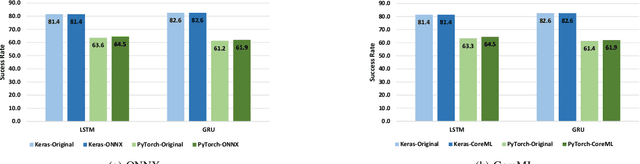
There is an increase in deploying Deep Learning (DL)-based software systems in real-world applications. Usually DL models are developed and trained using DL frameworks that have their own internal mechanisms/formats to represent and train DL models, and usually those formats cannot be recognized by other frameworks. Moreover, trained models are usually deployed in environments different from where they were developed. To solve the interoperability issue and make DL models compatible with different frameworks/environments, some exchange formats are introduced for DL models, like ONNX and CoreML. However, ONNX and CoreML were never empirically evaluated by the community to reveal their prediction accuracy, performance, and robustness after conversion. Poor accuracy or non-robust behavior of converted models may lead to poor quality of deployed DL-based software systems. We conduct, in this paper, the first empirical study to assess ONNX and CoreML for converting trained DL models. In our systematic approach, two popular DL frameworks, Keras and PyTorch, are used to train five widely used DL models on three popular datasets. The trained models are then converted to ONNX and CoreML and transferred to two runtime environments designated for such formats, to be evaluated. We investigate the prediction accuracy before and after conversion. Our results unveil that the prediction accuracy of converted models are at the same level of originals. The performance (time cost and memory consumption) of converted models are studied as well. The size of models are reduced after conversion, which can result in optimized DL-based software deployment. Converted models are generally assessed as robust at the same level of originals. However, obtained results show that CoreML models are more vulnerable to adversarial attacks compared to ONNX.
Studying the Practices of Deploying Machine Learning Projects on Docker
Jun 01, 2022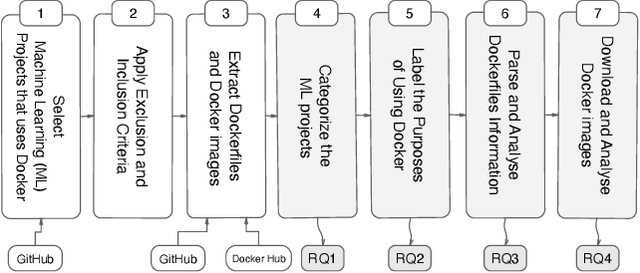
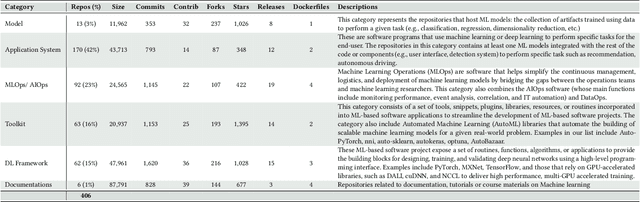
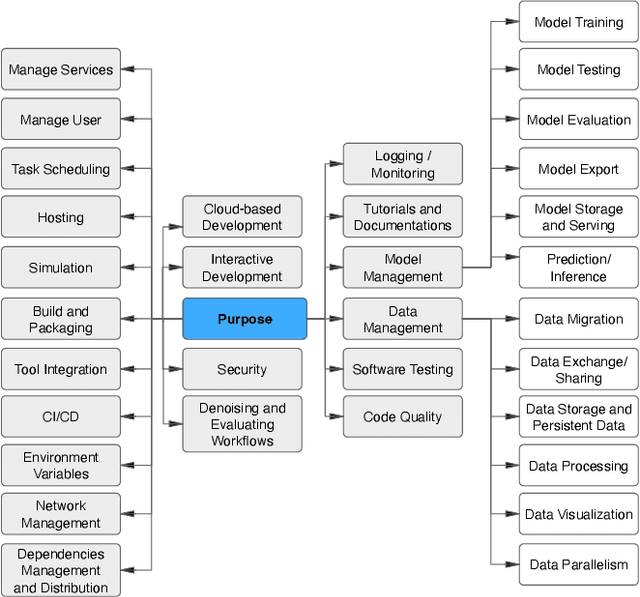

Docker is a containerization service that allows for convenient deployment of websites, databases, applications' APIs, and machine learning (ML) models with a few lines of code. Studies have recently explored the use of Docker for deploying general software projects with no specific focus on how Docker is used to deploy ML-based projects. In this study, we conducted an exploratory study to understand how Docker is being used to deploy ML-based projects. As the initial step, we examined the categories of ML-based projects that use Docker. We then examined why and how these projects use Docker, and the characteristics of the resulting Docker images. Our results indicate that six categories of ML-based projects use Docker for deployment, including ML Applications, MLOps/ AIOps, Toolkits, DL Frameworks, Models, and Documentation. We derived the taxonomy of 21 major categories representing the purposes of using Docker, including those specific to models such as model management tasks (e.g., testing, training). We then showed that ML engineers use Docker images mostly to help with the platform portability, such as transferring the software across the operating systems, runtimes such as GPU, and language constraints. However, we also found that more resources may be required to run the Docker images for building ML-based software projects due to the large number of files contained in the image layers with deeply nested directories. We hope to shed light on the emerging practices of deploying ML software projects using containers and highlight aspects that should be improved.