 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Debugging Deep Reinforcement Learning Programs with RLExplorer
Oct 06, 2024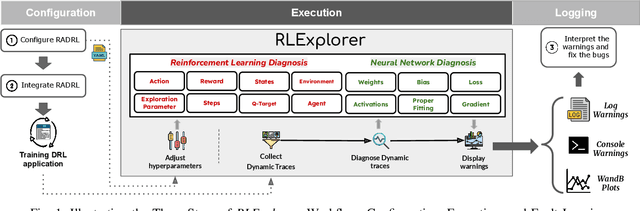
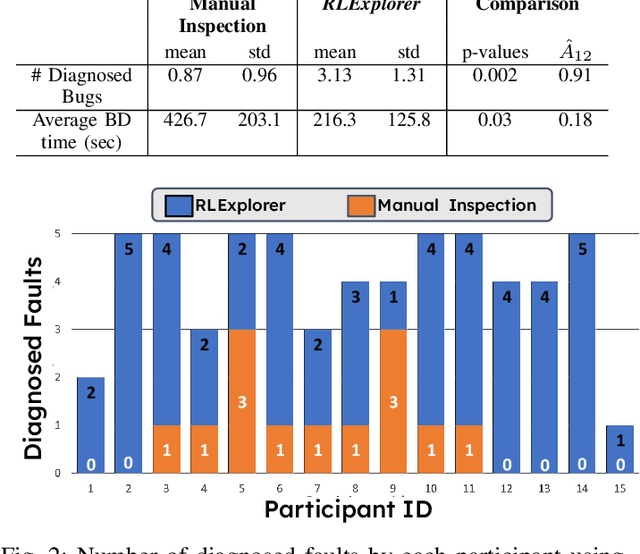
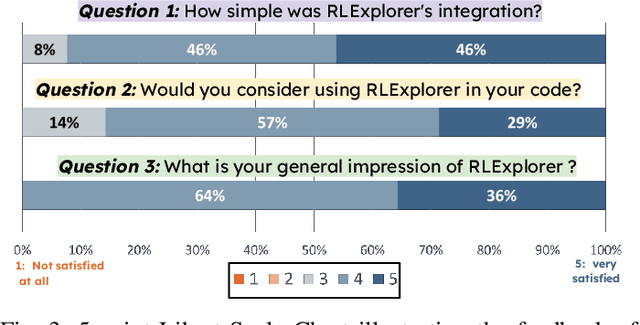
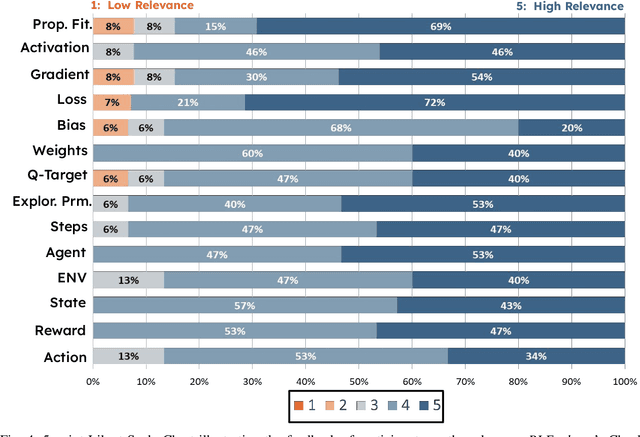
Deep reinforcement learning (DRL) has shown success in diverse domains such as robotics, computer games, and recommendation systems. However, like any other software system, DRL-based software systems are susceptible to faults that pose unique challenges for debugging and diagnosing. These faults often result in unexpected behavior without explicit failures and error messages, making debugging difficult and time-consuming. Therefore, automating the monitoring and diagnosis of DRL systems is crucial to alleviate the burden on developers. In this paper, we propose RLExplorer, the first fault diagnosis approach for DRL-based software systems. RLExplorer automatically monitors training traces and runs diagnosis routines based on properties of the DRL learning dynamics to detect the occurrence of DRL-specific faults. It then logs the results of these diagnoses as warnings that cover theoretical concepts, recommended practices, and potential solutions to the identified faults. We conducted two sets of evaluations to assess RLExplorer. Our first evaluation of faulty DRL samples from Stack Overflow revealed that our approach can effectively diagnose real faults in 83% of the cases. Our second evaluation of RLExplorer with 15 DRL experts/developers showed that (1) RLExplorer could identify 3.6 times more defects than manual debugging and (2) RLExplorer is easily integrated into DRL applications.
An Intentional Forgetting-Driven Self-Healing Method For Deep Reinforcement Learning Systems
Aug 23, 2023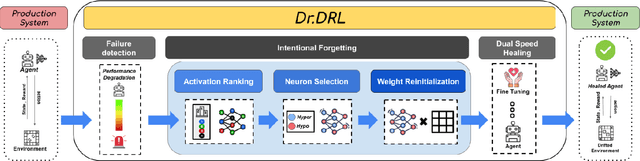
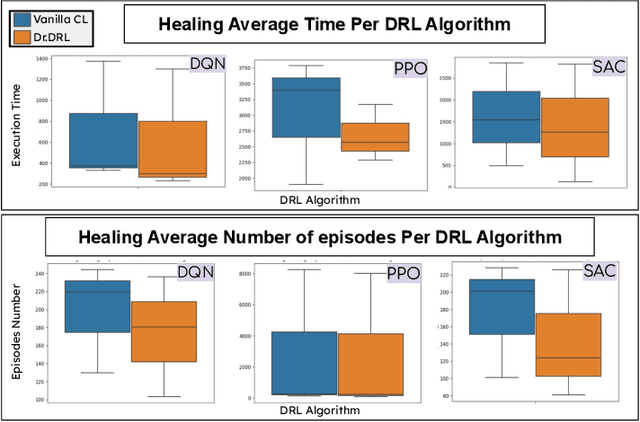
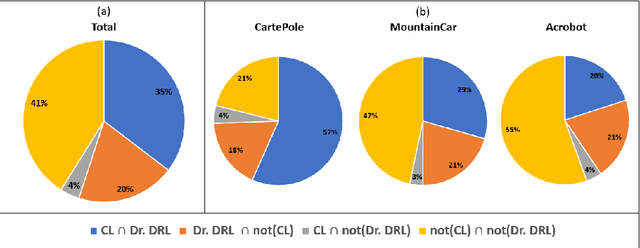
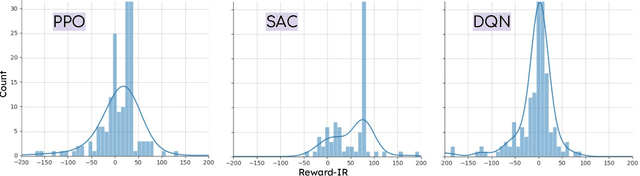
Deep reinforcement learning (DRL) is increasingly applied in large-scale productions like Netflix and Facebook. As with most data-driven systems, DRL systems can exhibit undesirable behaviors due to environmental drifts, which often occur in constantly-changing production settings. Continual Learning (CL) is the inherent self-healing approach for adapting the DRL agent in response to the environment's conditions shifts. However, successive shifts of considerable magnitude may cause the production environment to drift from its original state. Recent studies have shown that these environmental drifts tend to drive CL into long, or even unsuccessful, healing cycles, which arise from inefficiencies such as catastrophic forgetting, warm-starting failure, and slow convergence. In this paper, we propose Dr. DRL, an effective self-healing approach for DRL systems that integrates a novel mechanism of intentional forgetting into vanilla CL to overcome its main issues. Dr. DRL deliberately erases the DRL system's minor behaviors to systematically prioritize the adaptation of the key problem-solving skills. Using well-established DRL algorithms, Dr. DRL is compared with vanilla CL on various drifted environments. Dr. DRL is able to reduce, on average, the healing time and fine-tuning episodes by, respectively, 18.74% and 17.72%. Dr. DRL successfully helps agents to adapt to 19.63% of drifted environments left unsolved by vanilla CL while maintaining and even enhancing by up to 45% the obtained rewards for drifted environments that are resolved by both approaches.
Deploying Deep Reinforcement Learning Systems: A Taxonomy of Challenges
Aug 23, 2023Deep reinforcement learning (DRL), leveraging Deep Learning (DL) in reinforcement learning, has shown significant potential in achieving human-level autonomy in a wide range of domains, including robotics, computer vision, and computer games. This potential justifies the enthusiasm and growing interest in DRL in both academia and industry. However, the community currently focuses mostly on the development phase of DRL systems, with little attention devoted to DRL deployment. In this paper, we propose an empirical study on Stack Overflow (SO), the most popular Q&A forum for developers, to uncover and understand the challenges practitioners faced when deploying DRL systems. Specifically, we categorized relevant SO posts by deployment platforms: server/cloud, mobile/embedded system, browser, and game engine. After filtering and manual analysis, we examined 357 SO posts about DRL deployment, investigated the current state, and identified the challenges related to deploying DRL systems. Then, we investigate the prevalence and difficulty of these challenges. Results show that the general interest in DRL deployment is growing, confirming the study's relevance and importance. Results also show that DRL deployment is more difficult than other DRL issues. Additionally, we built a taxonomy of 31 unique challenges in deploying DRL to different platforms. On all platforms, RL environment-related challenges are the most popular, and communication-related challenges are the most difficult among practitioners. We hope our study inspires future research and helps the community overcome the most common and difficult challenges practitioners face when deploying DRL systems.
DiverGet: A Search-Based Software Testing Approach for Deep Neural Network Quantization Assessment
Jul 13, 2022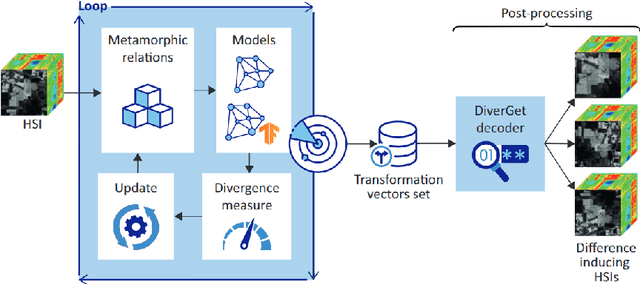
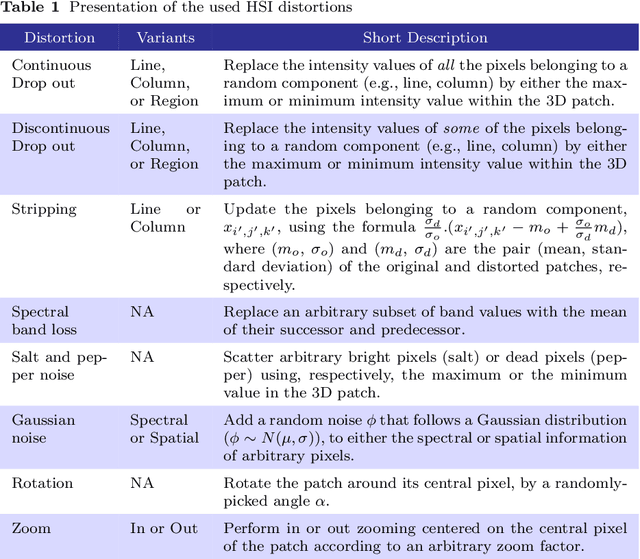
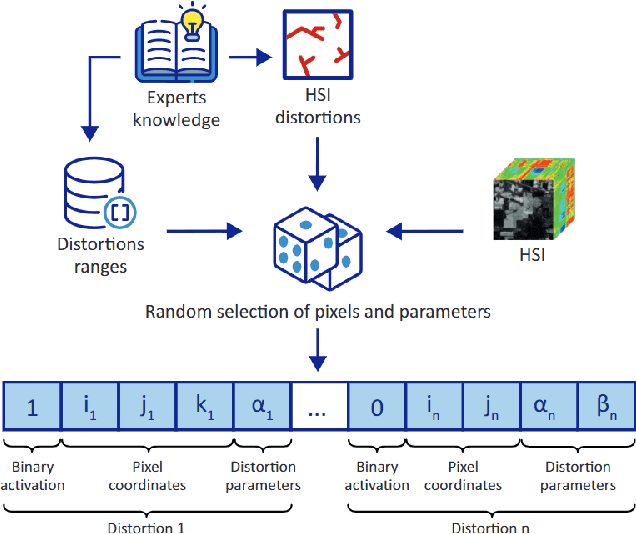
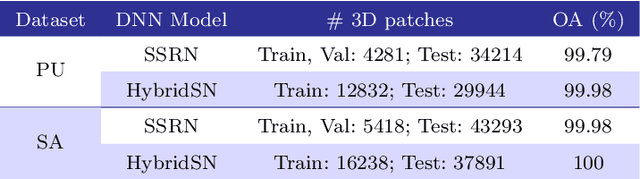
Quantization is one of the most applied Deep Neural Network (DNN) compression strategies, when deploying a trained DNN model on an embedded system or a cell phone. This is owing to its simplicity and adaptability to a wide range of applications and circumstances, as opposed to specific Artificial Intelligence (AI) accelerators and compilers that are often designed only for certain specific hardware (e.g., Google Coral Edge TPU). With the growing demand for quantization, ensuring the reliability of this strategy is becoming a critical challenge. Traditional testing methods, which gather more and more genuine data for better assessment, are often not practical because of the large size of the input space and the high similarity between the original DNN and its quantized counterpart. As a result, advanced assessment strategies have become of paramount importance. In this paper, we present DiverGet, a search-based testing framework for quantization assessment. DiverGet defines a space of metamorphic relations that simulate naturally-occurring distortions on the inputs. Then, it optimally explores these relations to reveal the disagreements among DNNs of different arithmetic precision. We evaluate the performance of DiverGet on state-of-the-art DNNs applied to hyperspectral remote sensing images. We chose the remote sensing DNNs as they're being increasingly deployed at the edge (e.g., high-lift drones) in critical domains like climate change research and astronomy. Our results show that DiverGet successfully challenges the robustness of established quantization techniques against naturally-occurring shifted data, and outperforms its most recent concurrent, DiffChaser, with a success rate that is (on average) four times higher.
An Empirical Study of Challenges in Converting Deep Learning Models
Jun 28, 2022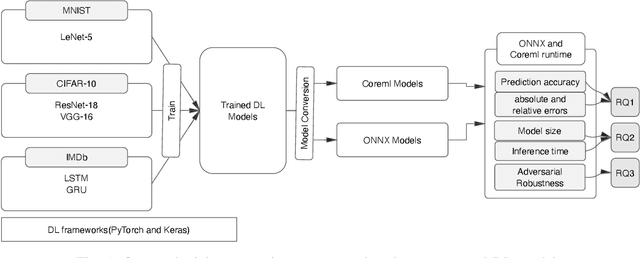
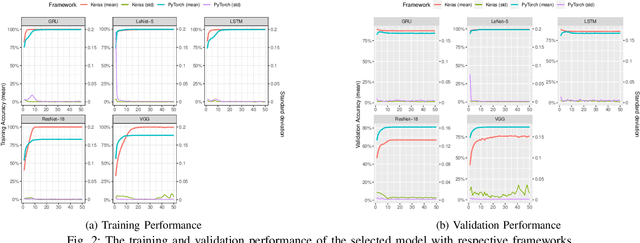
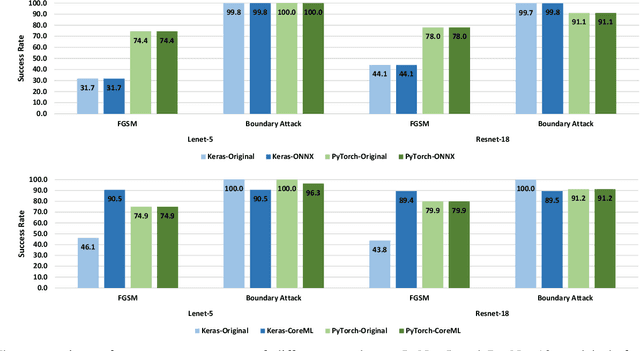
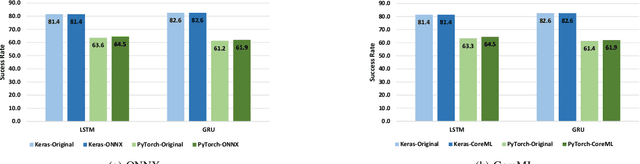
There is an increase in deploying Deep Learning (DL)-based software systems in real-world applications. Usually DL models are developed and trained using DL frameworks that have their own internal mechanisms/formats to represent and train DL models, and usually those formats cannot be recognized by other frameworks. Moreover, trained models are usually deployed in environments different from where they were developed. To solve the interoperability issue and make DL models compatible with different frameworks/environments, some exchange formats are introduced for DL models, like ONNX and CoreML. However, ONNX and CoreML were never empirically evaluated by the community to reveal their prediction accuracy, performance, and robustness after conversion. Poor accuracy or non-robust behavior of converted models may lead to poor quality of deployed DL-based software systems. We conduct, in this paper, the first empirical study to assess ONNX and CoreML for converting trained DL models. In our systematic approach, two popular DL frameworks, Keras and PyTorch, are used to train five widely used DL models on three popular datasets. The trained models are then converted to ONNX and CoreML and transferred to two runtime environments designated for such formats, to be evaluated. We investigate the prediction accuracy before and after conversion. Our results unveil that the prediction accuracy of converted models are at the same level of originals. The performance (time cost and memory consumption) of converted models are studied as well. The size of models are reduced after conversion, which can result in optimized DL-based software deployment. Converted models are generally assessed as robust at the same level of originals. However, obtained results show that CoreML models are more vulnerable to adversarial attacks compared to ONNX.