 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo MLLMs See What We See? Analyzing Visualization Literacy Barriers in AI Systems
Jan 18, 2026Multimodal Large Language Models (MLLMs) are increasingly used to interpret visualizations, yet little is known about why they fail. We present the first systematic analysis of barriers to visualization literacy in MLLMs. Using the regenerated Visualization Literacy Assessment Test (reVLAT) benchmark with synthetic data, we open-coded 309 erroneous responses from four state-of-the-art models with a barrier-centric strategy adapted from human visualization literacy research. Our analysis yields a taxonomy of MLLM failures, revealing two machine-specific barriers that extend prior human-participation frameworks. Results show that models perform well on simple charts but struggle with color-intensive, segment-based visualizations, often failing to form consistent comparative reasoning. Our findings inform future evaluation and design of reliable AI-driven visualization assistants.
The Hitchhikers Guide to Production-ready Trustworthy Foundation Model powered Software (FMware)
May 15, 2025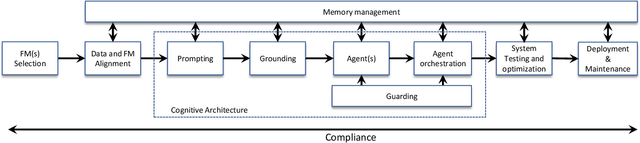
Foundation Models (FMs) such as Large Language Models (LLMs) are reshaping the software industry by enabling FMware, systems that integrate these FMs as core components. In this KDD 2025 tutorial, we present a comprehensive exploration of FMware that combines a curated catalogue of challenges with real-world production concerns. We first discuss the state of research and practice in building FMware. We further examine the difficulties in selecting suitable models, aligning high-quality domain-specific data, engineering robust prompts, and orchestrating autonomous agents. We then address the complex journey from impressive demos to production-ready systems by outlining issues in system testing, optimization, deployment, and integration with legacy software. Drawing on our industrial experience and recent research in the area, we provide actionable insights and a technology roadmap for overcoming these challenges. Attendees will gain practical strategies to enable the creation of trustworthy FMware in the evolving technology landscape.
Maximizing User Connectivity in AI-Enabled Multi-UAV Networks: A Distributed Strategy Generalized to Arbitrary User Distributions
Nov 07, 2024



Deep reinforcement learning (DRL) has been extensively applied to Multi-Unmanned Aerial Vehicle (UAV) network (MUN) to effectively enable real-time adaptation to complex, time-varying environments. Nevertheless, most of the existing works assume a stationary user distribution (UD) or a dynamic one with predicted patterns. Such considerations may make the UD-specific strategies insufficient when a MUN is deployed in unknown environments. To this end, this paper investigates distributed user connectivity maximization problem in a MUN with generalization to arbitrary UDs. Specifically, the problem is first formulated into a time-coupled combinatorial nonlinear non-convex optimization with arbitrary underlying UDs. To make the optimization tractable, a multi-agent CNN-enhanced deep Q learning (MA-CDQL) algorithm is proposed. The algorithm integrates a ResNet-based CNN to the policy network to analyze the input UD in real time and obtain optimal decisions based on the extracted high-level UD features. To improve the learning efficiency and avoid local optimums, a heatmap algorithm is developed to transform the raw UD to a continuous density map. The map will be part of the true input to the policy network. Simulations are conducted to demonstrate the efficacy of UD heatmaps and the proposed algorithm in maximizing user connectivity as compared to K-means methods.
Towards AI-Native Software Engineering (SE 3.0): A Vision and a Challenge Roadmap
Oct 08, 2024



The rise of AI-assisted software engineering (SE 2.0), powered by Foundation Models (FMs) and FM-powered copilots, has shown promise in improving developer productivity. However, it has also exposed inherent limitations, such as cognitive overload on developers and inefficiencies. We propose a shift towards Software Engineering 3.0 (SE 3.0), an AI-native approach characterized by intent-first, conversation-oriented development between human developers and AI teammates. SE 3.0 envisions AI systems evolving beyond task-driven copilots into intelligent collaborators, capable of deeply understanding and reasoning about software engineering principles and intents. We outline the key components of the SE 3.0 technology stack, which includes Teammate.next for adaptive and personalized AI partnership, IDE.next for intent-first conversation-oriented development, Compiler.next for multi-objective code synthesis, and Runtime.next for SLA-aware execution with edge-computing support. Our vision addresses the inefficiencies and cognitive strain of SE 2.0 by fostering a symbiotic relationship between human developers and AI, maximizing their complementary strengths. We also present a roadmap of challenges that must be overcome to realize our vision of SE 3.0. This paper lays the foundation for future discussions on the role of AI in the next era of software engineering.
Learning with Dynamics: Autonomous Regulation of UAV Based Communication Networks with Dynamic UAV Crew
Sep 25, 2024Unmanned Aerial Vehicle (UAV) based communication networks (UCNs) are a key component in future mobile networking. To handle the dynamic environments in UCNs, reinforcement learning (RL) has been a promising solution attributed to its strong capability of adaptive decision-making free of the environment models. However, most existing RL-based research focus on control strategy design assuming a fixed set of UAVs. Few works have investigated how UCNs should be adaptively regulated when the serving UAVs change dynamically. This article discusses RL-based strategy design for adaptive UCN regulation given a dynamic UAV set, addressing both reactive strategies in general UCNs and proactive strategies in solar-powered UCNs. An overview of the UCN and the RL framework is first provided. Potential research directions with key challenges and possible solutions are then elaborated. Some of our recent works are presented as case studies to inspire innovative ways to handle dynamic UAV crew with different RL algorithms.
Keeping Deep Learning Models in Check: A History-Based Approach to Mitigate Overfitting
Jan 18, 2024In software engineering, deep learning models are increasingly deployed for critical tasks such as bug detection and code review. However, overfitting remains a challenge that affects the quality, reliability, and trustworthiness of software systems that utilize deep learning models. Overfitting can be (1) prevented (e.g., using dropout or early stopping) or (2) detected in a trained model (e.g., using correlation-based approaches). Both overfitting detection and prevention approaches that are currently used have constraints (e.g., requiring modification of the model structure, and high computing resources). In this paper, we propose a simple, yet powerful approach that can both detect and prevent overfitting based on the training history (i.e., validation losses). Our approach first trains a time series classifier on training histories of overfit models. This classifier is then used to detect if a trained model is overfit. In addition, our trained classifier can be used to prevent overfitting by identifying the optimal point to stop a model's training. We evaluate our approach on its ability to identify and prevent overfitting in real-world samples. We compare our approach against correlation-based detection approaches and the most commonly used prevention approach (i.e., early stopping). Our approach achieves an F1 score of 0.91 which is at least 5% higher than the current best-performing non-intrusive overfitting detection approach. Furthermore, our approach can stop training to avoid overfitting at least 32% of the times earlier than early stopping and has the same or a better rate of returning the best model.
A Survey on Query-based API Recommendation
Dec 21, 2023Application Programming Interfaces (APIs) are designed to help developers build software more effectively. Recommending the right APIs for specific tasks has gained increasing attention among researchers and developers in recent years. To comprehensively understand this research domain, we have surveyed to analyze API recommendation studies published in the last 10 years. Our study begins with an overview of the structure of API recommendation tools. Subsequently, we systematically analyze prior research and pose four key research questions. For RQ1, we examine the volume of published papers and the venues in which these papers appear within the API recommendation field. In RQ2, we categorize and summarize the prevalent data sources and collection methods employed in API recommendation research. In RQ3, we explore the types of data and common data representations utilized by API recommendation approaches. We also investigate the typical data extraction procedures and collection approaches employed by the existing approaches. RQ4 delves into the modeling techniques employed by API recommendation approaches, encompassing both statistical and deep learning models. Additionally, we compile an overview of the prevalent ranking strategies and evaluation metrics used for assessing API recommendation tools. Drawing from our survey findings, we identify current challenges in API recommendation research that warrant further exploration, along with potential avenues for future research.
Studying the Practices of Testing Machine Learning Software in the Wild
Dec 19, 2023
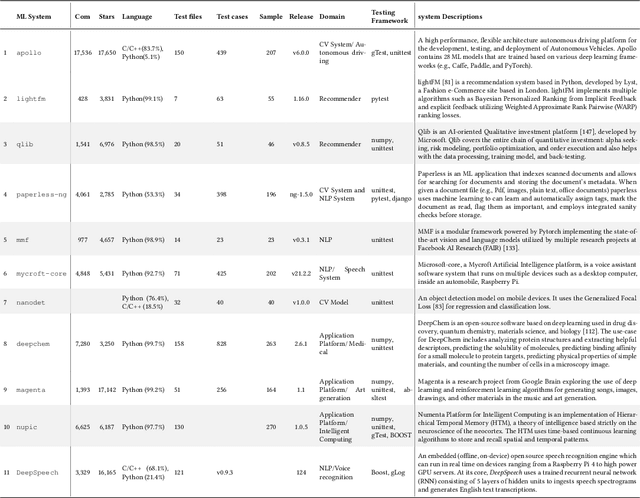
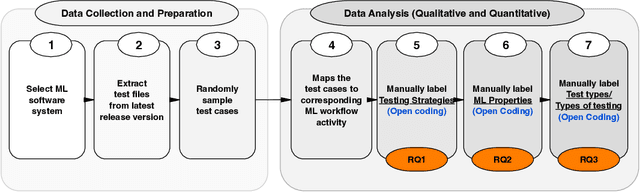

Background: We are witnessing an increasing adoption of machine learning (ML), especially deep learning (DL) algorithms in many software systems, including safety-critical systems such as health care systems or autonomous driving vehicles. Ensuring the software quality of these systems is yet an open challenge for the research community, mainly due to the inductive nature of ML software systems. Traditionally, software systems were constructed deductively, by writing down the rules that govern the behavior of the system as program code. However, for ML software, these rules are inferred from training data. Few recent research advances in the quality assurance of ML systems have adapted different concepts from traditional software testing, such as mutation testing, to help improve the reliability of ML software systems. However, it is unclear if any of these proposed testing techniques from research are adopted in practice. There is little empirical evidence about the testing strategies of ML engineers. Aims: To fill this gap, we perform the first fine-grained empirical study on ML testing practices in the wild, to identify the ML properties being tested, the followed testing strategies, and their implementation throughout the ML workflow. Method: First, we systematically summarized the different testing strategies (e.g., Oracle Approximation), the tested ML properties (e.g., Correctness, Bias, and Fairness), and the testing methods (e.g., Unit test) from the literature. Then, we conducted a study to understand the practices of testing ML software. Results: In our findings: 1) we identified four (4) major categories of testing strategy including Grey-box, White-box, Black-box, and Heuristic-based techniques that are used by the ML engineers to find software bugs. 2) We identified 16 ML properties that are tested in the ML workflow.
Bug Characterization in Machine Learning-based Systems
Jul 26, 2023Rapid growth of applying Machine Learning (ML) in different domains, especially in safety-critical areas, increases the need for reliable ML components, i.e., a software component operating based on ML. Understanding the bugs characteristics and maintenance challenges in ML-based systems can help developers of these systems to identify where to focus maintenance and testing efforts, by giving insights into the most error-prone components, most common bugs, etc. In this paper, we investigate the characteristics of bugs in ML-based software systems and the difference between ML and non-ML bugs from the maintenance viewpoint. We extracted 447,948 GitHub repositories that used one of the three most popular ML frameworks, i.e., TensorFlow, Keras, and PyTorch. After multiple filtering steps, we select the top 300 repositories with the highest number of closed issues. We manually investigate the extracted repositories to exclude non-ML-based systems. Our investigation involved a manual inspection of 386 sampled reported issues in the identified ML-based systems to indicate whether they affect ML components or not. Our analysis shows that nearly half of the real issues reported in ML-based systems are ML bugs, indicating that ML components are more error-prone than non-ML components. Next, we thoroughly examined 109 identified ML bugs to identify their root causes, symptoms, and calculate their required fixing time. The results also revealed that ML bugs have significantly different characteristics compared to non-ML bugs, in terms of the complexity of bug-fixing (number of commits, changed files, and changed lines of code). Based on our results, fixing ML bugs are more costly and ML components are more error-prone, compared to non-ML bugs and non-ML components respectively. Hence, paying a significant attention to the reliability of the ML components is crucial in ML-based systems.
A Cross-direction Task Decoupling Network for Small Logo Detection
May 04, 2023
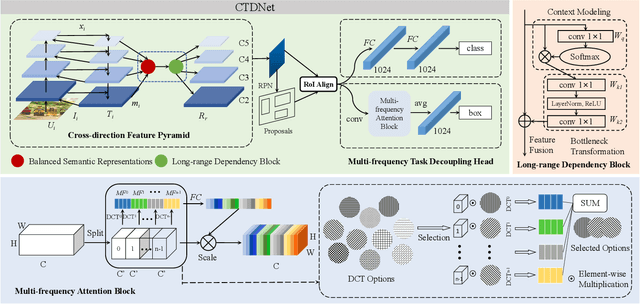


Logo detection plays an integral role in many applications. However, handling small logos is still difficult since they occupy too few pixels in the image, which burdens the extraction of discriminative features. The aggregation of small logos also brings a great challenge to the classification and localization of logos. To solve these problems, we creatively propose Cross-direction Task Decoupling Network (CTDNet) for small logo detection. We first introduce Cross-direction Feature Pyramid (CFP) to realize cross-direction feature fusion by adopting horizontal transmission and vertical transmission. In addition, Multi-frequency Task Decoupling Head (MTDH) decouples the classification and localization tasks into two branches. A multi frequency attention convolution branch is designed to achieve more accurate regression by combining discrete cosine transform and convolution creatively. Comprehensive experiments on four logo datasets demonstrate the effectiveness and efficiency of the proposed method.