 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFundaPod: A Multi-Persona Agent Pod Platform with Knowledge Graph Memory for AI-Assisted Fundamental Investment Research
May 28, 2026Large language models (LLMs) are increasingly applied in finance, yet most existing work emphasizes trading signals or financial NLP tasks centered on prediction. Institutional fundamental research, by contrast, requires human analysts or AI agents to gather evidence, identify business drivers, compare competing viewpoints, and generate investment memos. Its broader goal is not merely to predict outcomes, but to produce investment plans that are transparent, reusable, and verifiable, while contributing to the cumulative development of investment knowledge. We present FundaPod, a multi-persona agent platform for AI-assisted fundamental investment research. We argue that fundamental research is a human-centric decision-support task that is qualitatively distinct from trading-signal generation, and is therefore better served by an independence-preserving architecture. In FundaPod, AI agents with different personas, such as value investors or macro strategists, conduct research independently under a shared provenance contract. Their disagreements are then surfaced post hoc for adjudication by the human portfolio manager (PM) through a knowledge-graph memory system. This paper contributes five design principles for human-AI hybrid systems supporting fundamental research, grounded in design-science practice and theories of cognitive isolation and human-machine coordination. It also describes four architectural mechanisms: a persona distillation pipeline that turns public investor materials into deployable agents; a declarative skill registry that lets the planner derive typed task graphs; a grounded evidence model that links memo claims to verifiable sources; and a knowledge-graph "second brain" that connects tickers, memos, analysts, and themes. We demonstrate the architecture through a complete case study and a persona-based memo comparison.
VILAS: A VLA-Integrated Low-cost Architecture with Soft Grasping for Robotic Manipulation
May 03, 2026We present VILAS, a fully low-cost, modular robotic manipulation platform designed to support end-to-end vision-language-action (VLA) policy learning and deployment on accessible hardware. The system integrates a Fairino FR5 collaborative arm, a Jodell RG52-50 electric gripper, and a dual-camera perception module, unified through a ZMQ-based communication architecture that seamlessly coordinates teleoperation, data collection, and policy deployment within a single framework. To enable safe manipulation of fragile objects without relying on explicit force sensing, we design a kirigami-based soft compliant gripper extension that induces predictable deformation under compressive loading, providing gentle and repeatable contact with delicate targets. We deploy and evaluate three state-of-the-art VLA models on the VILAS platform: pi_0, pi_0.5, and GR00T N1.6. All models are fine-tuned from publicly released pretrained checkpoints using an identical demonstration dataset collected via our teleoperation pipeline. Experiments on a grape grasping task validate the effectiveness of the proposed system, confirming that capable manipulation policies can be successfully trained and deployed on low-cost modular hardware. Our results further provide practical insights into the deployment characteristics of current VLA models in real-world settings.
A Cross-direction Task Decoupling Network for Small Logo Detection
May 04, 2023
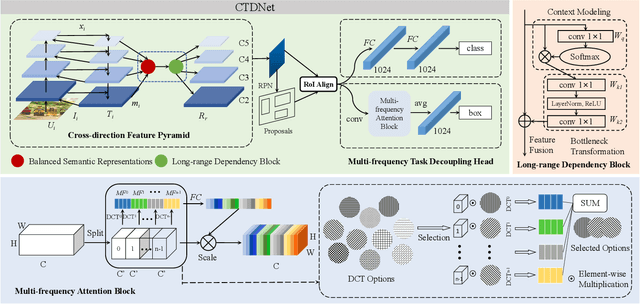


Logo detection plays an integral role in many applications. However, handling small logos is still difficult since they occupy too few pixels in the image, which burdens the extraction of discriminative features. The aggregation of small logos also brings a great challenge to the classification and localization of logos. To solve these problems, we creatively propose Cross-direction Task Decoupling Network (CTDNet) for small logo detection. We first introduce Cross-direction Feature Pyramid (CFP) to realize cross-direction feature fusion by adopting horizontal transmission and vertical transmission. In addition, Multi-frequency Task Decoupling Head (MTDH) decouples the classification and localization tasks into two branches. A multi frequency attention convolution branch is designed to achieve more accurate regression by combining discrete cosine transform and convolution creatively. Comprehensive experiments on four logo datasets demonstrate the effectiveness and efficiency of the proposed method.
Balanced Contrastive Learning for Long-Tailed Visual Recognition
Jul 19, 2022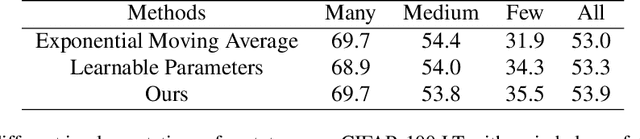
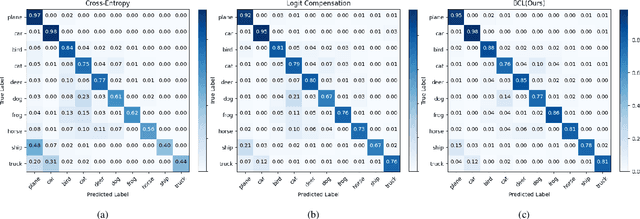
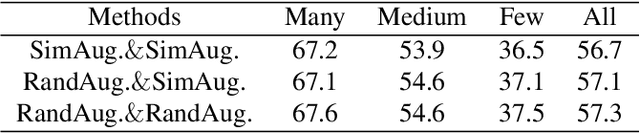
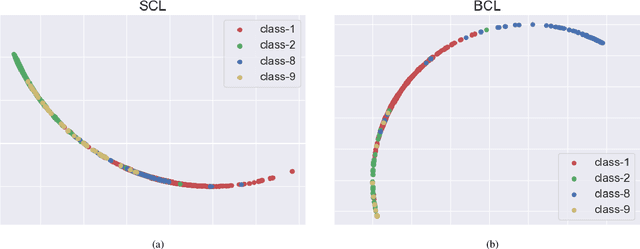
Real-world data typically follow a long-tailed distribution, where a few majority categories occupy most of the data while most minority categories contain a limited number of samples. Classification models minimizing cross-entropy struggle to represent and classify the tail classes. Although the problem of learning unbiased classifiers has been well studied, methods for representing imbalanced data are under-explored. In this paper, we focus on representation learning for imbalanced data. Recently, supervised contrastive learning has shown promising performance on balanced data recently. However, through our theoretical analysis, we find that for long-tailed data, it fails to form a regular simplex which is an ideal geometric configuration for representation learning. To correct the optimization behavior of SCL and further improve the performance of long-tailed visual recognition, we propose a novel loss for balanced contrastive learning (BCL). Compared with SCL, we have two improvements in BCL: class-averaging, which balances the gradient contribution of negative classes; class-complement, which allows all classes to appear in every mini-batch. The proposed balanced contrastive learning (BCL) method satisfies the condition of forming a regular simplex and assists the optimization of cross-entropy. Equipped with BCL, the proposed two-branch framework can obtain a stronger feature representation and achieve competitive performance on long-tailed benchmark datasets such as CIFAR-10-LT, CIFAR-100-LT, ImageNet-LT, and iNaturalist2018. Our code is available at \href{https://github.com/FlamieZhu/BCL}{this URL}.