 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGR2 Technical Report
Jun 30, 2026Industrial recommendation systems serve billions of users through a multi-stage funnel -- retrieval, early-stage ranking, and re-ranking -- where the final re-ranking step disproportionately shapes user engagement and downstream performance, particularly for carousel and grid display formats. Despite growing enthusiasm for Large Language Models (LLMs) in recommendation, three gaps hinder industrial adoption: (1) most efforts target retrieval and ranking, leaving re-ranking -- the stage closest to the final user experience -- largely underexplored; (2) LLMs are typically deployed zero-shot or via supervised fine-tuning, underutilizing the reasoning capabilities unlocked by reinforcement learning (RL) on verifiable rewards; (3) deployed catalogs index billions of items with non-semantic identifiers that lie outside any base-LLM vocabulary. We present GR2 (Generative Reasoning Re-Ranker), an end-to-end framework that combines (i) mid-training on semantic IDs produced by a tokenizer with >=99% uniqueness, (ii) reasoning-trace distilled from a stronger teacher via targeted prompting and rejection sampling, and (iii) RL with verifiable rewards purpose-built for re-ranking. To make GR2 resource-viable, we further (iv) introduce a context compressor that amortizes training cost, On-Policy Distillation (OPD) as a scalable alternative to SFT -- which we find collapses at industrial scale -- and reasoning distillation for low-latency serving. GR2 delivers +18.7% R@1, +7.1% R@3, and +9.6% N@3 over legacy baselines on industrial-scale traffic. We further find that reward design is critical in re-ranking: LLMs often hack rewards by preserving the incoming order or exploiting position bias, motivating conditional verifiable rewards as essential industrial components.
Aligned Multi Objective Optimization
Feb 19, 2025To date, the multi-objective optimization literature has mainly focused on conflicting objectives, studying the Pareto front, or requiring users to balance tradeoffs. Yet, in machine learning practice, there are many scenarios where such conflict does not take place. Recent findings from multi-task learning, reinforcement learning, and LLMs training show that diverse related tasks can enhance performance across objectives simultaneously. Despite this evidence, such phenomenon has not been examined from an optimization perspective. This leads to a lack of generic gradient-based methods that can scale to scenarios with a large number of related objectives. To address this gap, we introduce the Aligned Multi-Objective Optimization framework, propose new algorithms for this setting, and provide theoretical guarantees of their superior performance compared to naive approaches.
Magentic-One: A Generalist Multi-Agent System for Solving Complex Tasks
Nov 07, 2024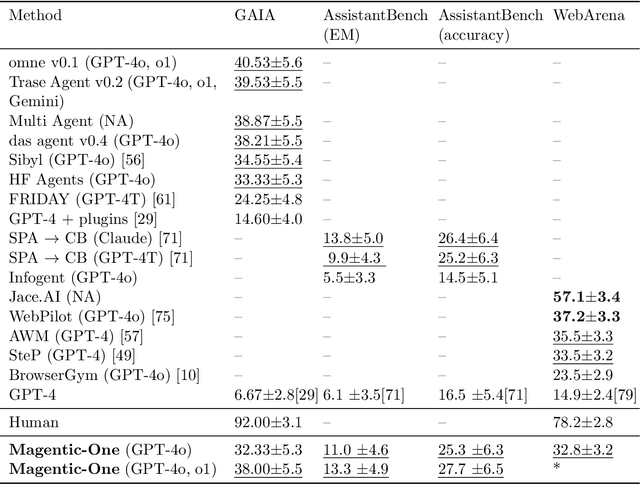
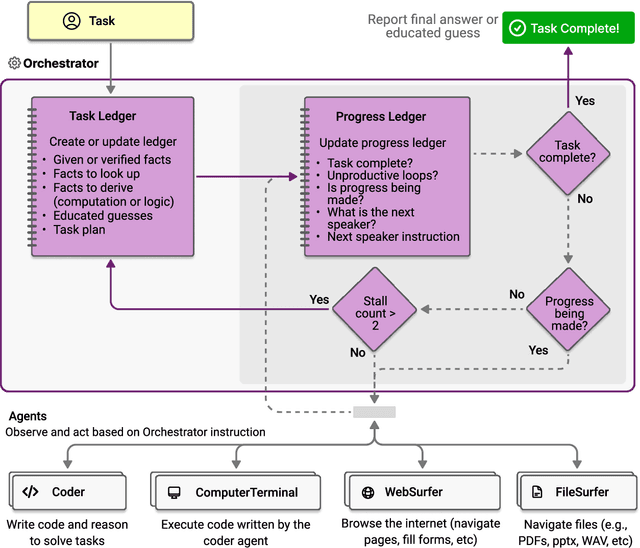
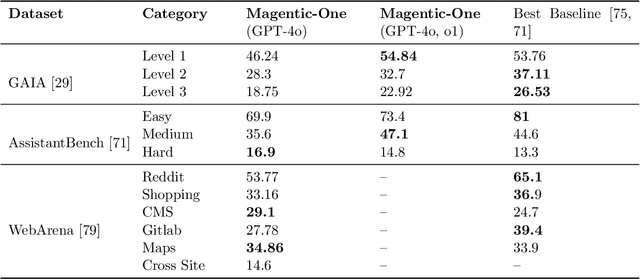
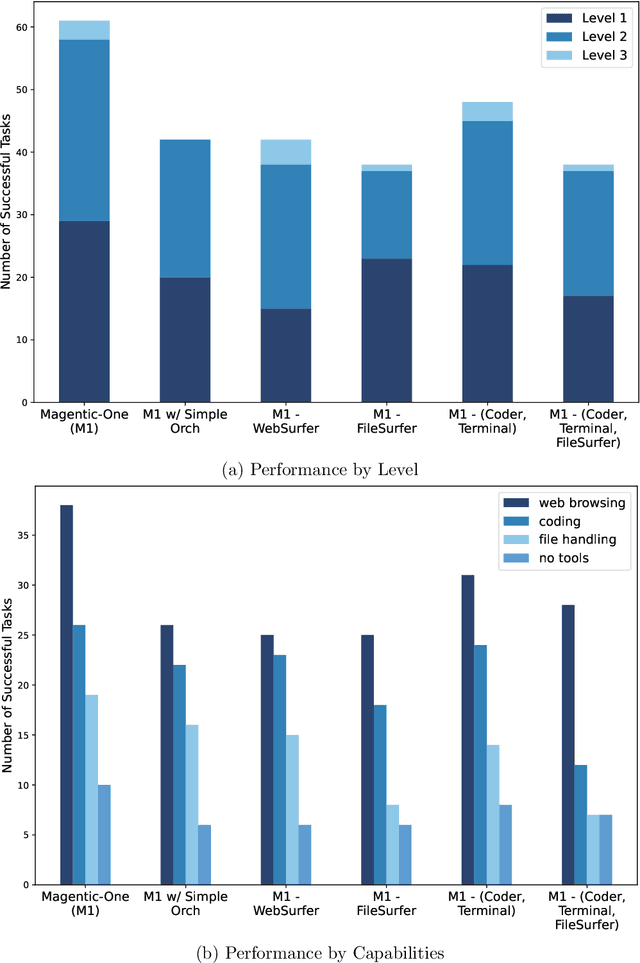
Modern AI agents, driven by advances in large foundation models, promise to enhance our productivity and transform our lives by augmenting our knowledge and capabilities. To achieve this vision, AI agents must effectively plan, perform multi-step reasoning and actions, respond to novel observations, and recover from errors, to successfully complete complex tasks across a wide range of scenarios. In this work, we introduce Magentic-One, a high-performing open-source agentic system for solving such tasks. Magentic-One uses a multi-agent architecture where a lead agent, the Orchestrator, plans, tracks progress, and re-plans to recover from errors. Throughout task execution, the Orchestrator directs other specialized agents to perform tasks as needed, such as operating a web browser, navigating local files, or writing and executing Python code. We show that Magentic-One achieves statistically competitive performance to the state-of-the-art on three diverse and challenging agentic benchmarks: GAIA, AssistantBench, and WebArena. Magentic-One achieves these results without modification to core agent capabilities or to how they collaborate, demonstrating progress towards generalist agentic systems. Moreover, Magentic-One's modular design allows agents to be added or removed from the team without additional prompt tuning or training, easing development and making it extensible to future scenarios. We provide an open-source implementation of Magentic-One, and we include AutoGenBench, a standalone tool for agentic evaluation. AutoGenBench provides built-in controls for repetition and isolation to run agentic benchmarks in a rigorous and contained manner -- which is important when agents' actions have side-effects. Magentic-One, AutoGenBench and detailed empirical performance evaluations of Magentic-One, including ablations and error analysis are available at https://aka.ms/magentic-one
A Comprehensive Survey of LLM Alignment Techniques: RLHF, RLAIF, PPO, DPO and More
Jul 23, 2024



With advancements in self-supervised learning, the availability of trillions tokens in a pre-training corpus, instruction fine-tuning, and the development of large Transformers with billions of parameters, large language models (LLMs) are now capable of generating factual and coherent responses to human queries. However, the mixed quality of training data can lead to the generation of undesired responses, presenting a significant challenge. Over the past two years, various methods have been proposed from different perspectives to enhance LLMs, particularly in aligning them with human expectation. Despite these efforts, there has not been a comprehensive survey paper that categorizes and details these approaches. In this work, we aim to address this gap by categorizing these papers into distinct topics and providing detailed explanations of each alignment method, thereby helping readers gain a thorough understanding of the current state of the field.
Balanced Contrastive Learning for Long-Tailed Visual Recognition
Jul 19, 2022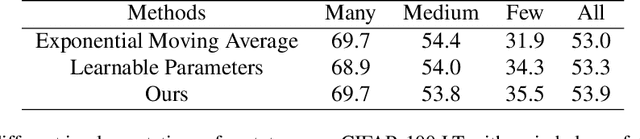
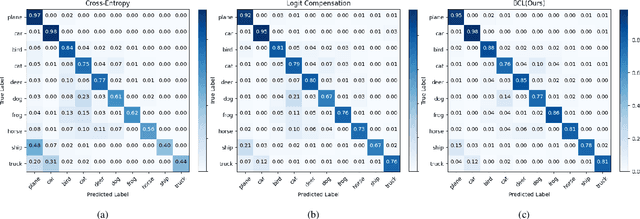
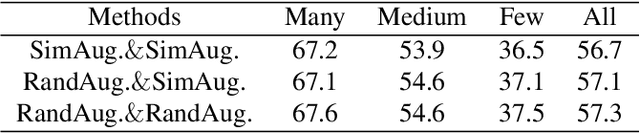
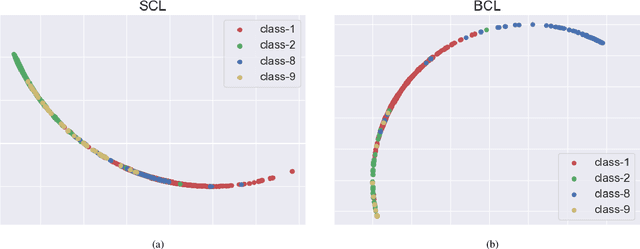
Real-world data typically follow a long-tailed distribution, where a few majority categories occupy most of the data while most minority categories contain a limited number of samples. Classification models minimizing cross-entropy struggle to represent and classify the tail classes. Although the problem of learning unbiased classifiers has been well studied, methods for representing imbalanced data are under-explored. In this paper, we focus on representation learning for imbalanced data. Recently, supervised contrastive learning has shown promising performance on balanced data recently. However, through our theoretical analysis, we find that for long-tailed data, it fails to form a regular simplex which is an ideal geometric configuration for representation learning. To correct the optimization behavior of SCL and further improve the performance of long-tailed visual recognition, we propose a novel loss for balanced contrastive learning (BCL). Compared with SCL, we have two improvements in BCL: class-averaging, which balances the gradient contribution of negative classes; class-complement, which allows all classes to appear in every mini-batch. The proposed balanced contrastive learning (BCL) method satisfies the condition of forming a regular simplex and assists the optimization of cross-entropy. Equipped with BCL, the proposed two-branch framework can obtain a stronger feature representation and achieve competitive performance on long-tailed benchmark datasets such as CIFAR-10-LT, CIFAR-100-LT, ImageNet-LT, and iNaturalist2018. Our code is available at \href{https://github.com/FlamieZhu/BCL}{this URL}.