 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMagentic-One: A Generalist Multi-Agent System for Solving Complex Tasks
Nov 07, 2024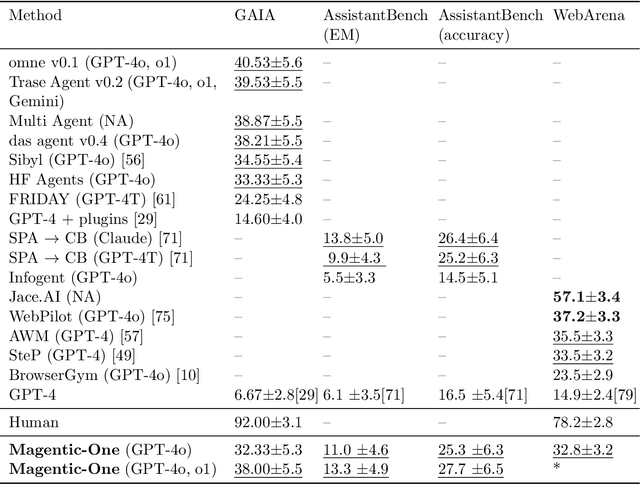
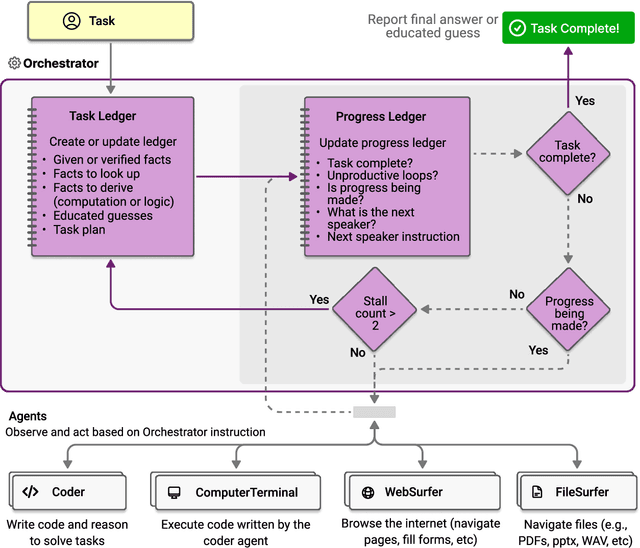
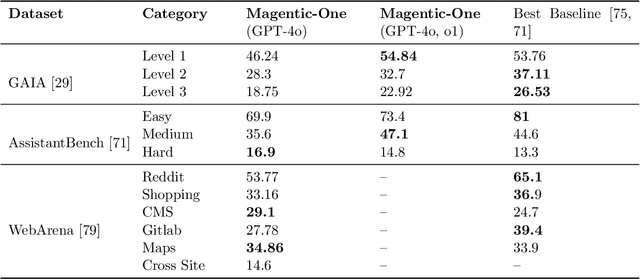
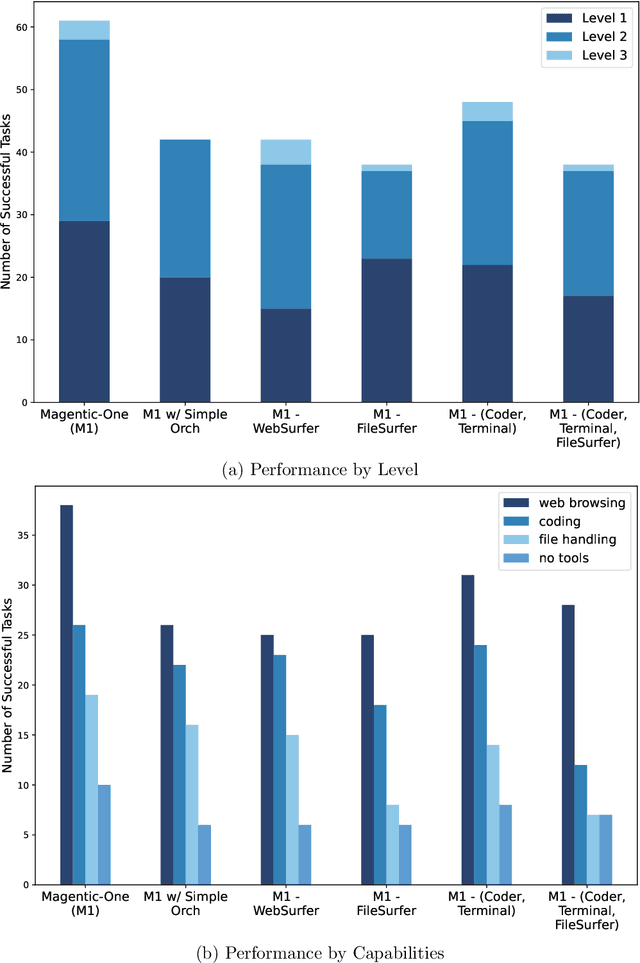
Modern AI agents, driven by advances in large foundation models, promise to enhance our productivity and transform our lives by augmenting our knowledge and capabilities. To achieve this vision, AI agents must effectively plan, perform multi-step reasoning and actions, respond to novel observations, and recover from errors, to successfully complete complex tasks across a wide range of scenarios. In this work, we introduce Magentic-One, a high-performing open-source agentic system for solving such tasks. Magentic-One uses a multi-agent architecture where a lead agent, the Orchestrator, plans, tracks progress, and re-plans to recover from errors. Throughout task execution, the Orchestrator directs other specialized agents to perform tasks as needed, such as operating a web browser, navigating local files, or writing and executing Python code. We show that Magentic-One achieves statistically competitive performance to the state-of-the-art on three diverse and challenging agentic benchmarks: GAIA, AssistantBench, and WebArena. Magentic-One achieves these results without modification to core agent capabilities or to how they collaborate, demonstrating progress towards generalist agentic systems. Moreover, Magentic-One's modular design allows agents to be added or removed from the team without additional prompt tuning or training, easing development and making it extensible to future scenarios. We provide an open-source implementation of Magentic-One, and we include AutoGenBench, a standalone tool for agentic evaluation. AutoGenBench provides built-in controls for repetition and isolation to run agentic benchmarks in a rigorous and contained manner -- which is important when agents' actions have side-effects. Magentic-One, AutoGenBench and detailed empirical performance evaluations of Magentic-One, including ablations and error analysis are available at https://aka.ms/magentic-one
Eureka: Evaluating and Understanding Large Foundation Models
Sep 13, 2024Rigorous and reproducible evaluation is critical for assessing the state of the art and for guiding scientific advances in Artificial Intelligence. Evaluation is challenging in practice due to several reasons, including benchmark saturation, lack of transparency in methods used for measurement, development challenges in extracting measurements for generative tasks, and, more generally, the extensive number of capabilities required for a well-rounded comparison across models. We make three contributions to alleviate the above challenges. First, we present Eureka, an open-source framework for standardizing evaluations of large foundation models beyond single-score reporting and rankings. Second, we introduce Eureka-Bench as an extensible collection of benchmarks testing capabilities that (i) are still challenging for state-of-the-art models and (ii) represent fundamental but overlooked language and multimodal capabilities. The inherent space for improvement in non-saturated benchmarks enables us to discover meaningful differences between models at a capability level. Third, using Eureka, we conduct an analysis of 12 state-of-the-art models, providing in-depth insights into failure understanding and model comparison, which can be leveraged to plan targeted improvements. In contrast to recent trends in reports and leaderboards showing absolute rankings and claims for one model or another to be the best, our analysis shows that there is no such best model. Different models have different strengths, but there are models that appear more often than others as best performers for some capabilities. Despite the recent improvements, current models still struggle with several fundamental capabilities including detailed image understanding, benefiting from multimodal input when available rather than fully relying on language, factuality and grounding for information retrieval, and over refusals.
Aligning LLM Agents by Learning Latent Preference from User Edits
Apr 23, 2024
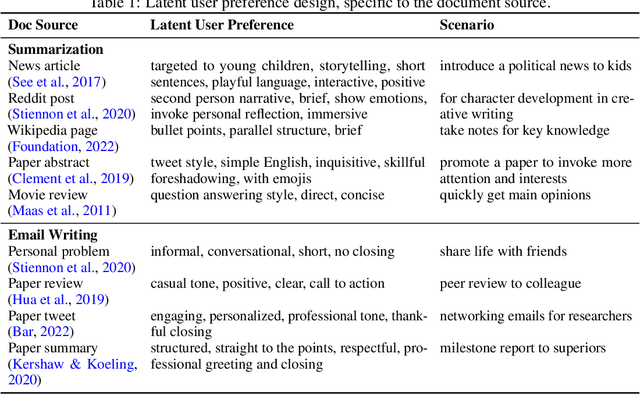


We study interactive learning of language agents based on user edits made to the agent's output. In a typical setting such as writing assistants, the user interacts with a language agent to generate a response given a context, and may optionally edit the agent response to personalize it based on their latent preference, in addition to improving the correctness. The edit feedback is naturally generated, making it a suitable candidate for improving the agent's alignment with the user's preference, and for reducing the cost of user edits over time. We propose a learning framework, PRELUDE that infers a description of the user's latent preference based on historic edit data and using it to define a prompt policy that drives future response generation. This avoids fine-tuning the agent, which is costly, challenging to scale with the number of users, and may even degrade its performance on other tasks. Furthermore, learning descriptive preference improves interpretability, allowing the user to view and modify the learned preference. However, user preference can be complex and vary based on context, making it challenging to learn. To address this, we propose a simple yet effective algorithm named CIPHER that leverages a large language model (LLM) to infer the user preference for a given context based on user edits. In the future, CIPHER retrieves inferred preferences from the k-closest contexts in the history, and forms an aggregate preference for response generation. We introduce two interactive environments -- summarization and email writing, for evaluation using a GPT-4 simulated user. We compare with algorithms that directly retrieve user edits but do not learn descriptive preference, and algorithms that learn context-agnostic preference. On both tasks, CIPHER achieves the lowest edit distance cost and learns preferences that show significant similarity to the ground truth preferences