 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverseeing Agents Without Constant Oversight: Challenges and Opportunities
Feb 18, 2026To enable human oversight, agentic AI systems often provide a trace of reasoning and action steps. Designing traces to have an informative, but not overwhelming, level of detail remains a critical challenge. In three user studies on a Computer User Agent, we investigate the utility of basic action traces for verification, explore three alternatives via design probes, and test a novel interface's impact on error finding in question-answering tasks. As expected, we find that current practices are cumbersome, limiting their efficacy. Conversely, our proposed design reduced the time participants spent finding errors. However, although participants reported higher levels of confidence in their decisions, their final accuracy was not meaningfully improved. To this end, our study surfaces challenges for human verification of agentic systems, including managing built-in assumptions, users' subjective and changing correctness criteria, and the shortcomings, yet importance, of communicating the agent's process.
Magentic-UI: Towards Human-in-the-loop Agentic Systems
Jul 30, 2025AI agents powered by large language models are increasingly capable of autonomously completing complex, multi-step tasks using external tools. Yet, they still fall short of human-level performance in most domains including computer use, software development, and research. Their growing autonomy and ability to interact with the outside world, also introduces safety and security risks including potentially misaligned actions and adversarial manipulation. We argue that human-in-the-loop agentic systems offer a promising path forward, combining human oversight and control with AI efficiency to unlock productivity from imperfect systems. We introduce Magentic-UI, an open-source web interface for developing and studying human-agent interaction. Built on a flexible multi-agent architecture, Magentic-UI supports web browsing, code execution, and file manipulation, and can be extended with diverse tools via Model Context Protocol (MCP). Moreover, Magentic-UI presents six interaction mechanisms for enabling effective, low-cost human involvement: co-planning, co-tasking, multi-tasking, action guards, and long-term memory. We evaluate Magentic-UI across four dimensions: autonomous task completion on agentic benchmarks, simulated user testing of its interaction capabilities, qualitative studies with real users, and targeted safety assessments. Our findings highlight Magentic-UI's potential to advance safe and efficient human-agent collaboration.
Inference-Time Scaling for Complex Tasks: Where We Stand and What Lies Ahead
Mar 31, 2025Inference-time scaling can enhance the reasoning capabilities of large language models (LLMs) on complex problems that benefit from step-by-step problem solving. Although lengthening generated scratchpads has proven effective for mathematical tasks, the broader impact of this approach on other tasks remains less clear. In this work, we investigate the benefits and limitations of scaling methods across nine state-of-the-art models and eight challenging tasks, including math and STEM reasoning, calendar planning, NP-hard problems, navigation, and spatial reasoning. We compare conventional models (e.g., GPT-4o) with models fine-tuned for inference-time scaling (e.g., o1) through evaluation protocols that involve repeated model calls, either independently or sequentially with feedback. These evaluations approximate lower and upper performance bounds and potential for future performance improvements for each model, whether through enhanced training or multi-model inference systems. Our extensive empirical analysis reveals that the advantages of inference-time scaling vary across tasks and diminish as problem complexity increases. In addition, simply using more tokens does not necessarily translate to higher accuracy in these challenging regimes. Results from multiple independent runs with conventional models using perfect verifiers show that, for some tasks, these models can achieve performance close to the average performance of today's most advanced reasoning models. However, for other tasks, a significant performance gap remains, even in very high scaling regimes. Encouragingly, all models demonstrate significant gains when inference is further scaled with perfect verifiers or strong feedback, suggesting ample potential for future improvements.
Steering Language Model Refusal with Sparse Autoencoders
Nov 18, 2024



Responsible practices for deploying language models include guiding models to recognize and refuse answering prompts that are considered unsafe, while complying with safe prompts. Achieving such behavior typically requires updating model weights, which is costly and inflexible. We explore opportunities to steering model activations at inference time, which does not require updating weights. Using sparse autoencoders, we identify and steer features in Phi-3 Mini that mediate refusal behavior. We find that feature steering can improve Phi-3 Minis robustness to jailbreak attempts across various harms, including challenging multi-turn attacks. However, we discover that feature steering can adversely affect overall performance on benchmarks. These results suggest that identifying steerable mechanisms for refusal via sparse autoencoders is a promising approach for enhancing language model safety, but that more research is needed to mitigate feature steerings adverse effects on performance.
Eureka: Evaluating and Understanding Large Foundation Models
Sep 13, 2024Rigorous and reproducible evaluation is critical for assessing the state of the art and for guiding scientific advances in Artificial Intelligence. Evaluation is challenging in practice due to several reasons, including benchmark saturation, lack of transparency in methods used for measurement, development challenges in extracting measurements for generative tasks, and, more generally, the extensive number of capabilities required for a well-rounded comparison across models. We make three contributions to alleviate the above challenges. First, we present Eureka, an open-source framework for standardizing evaluations of large foundation models beyond single-score reporting and rankings. Second, we introduce Eureka-Bench as an extensible collection of benchmarks testing capabilities that (i) are still challenging for state-of-the-art models and (ii) represent fundamental but overlooked language and multimodal capabilities. The inherent space for improvement in non-saturated benchmarks enables us to discover meaningful differences between models at a capability level. Third, using Eureka, we conduct an analysis of 12 state-of-the-art models, providing in-depth insights into failure understanding and model comparison, which can be leveraged to plan targeted improvements. In contrast to recent trends in reports and leaderboards showing absolute rankings and claims for one model or another to be the best, our analysis shows that there is no such best model. Different models have different strengths, but there are models that appear more often than others as best performers for some capabilities. Despite the recent improvements, current models still struggle with several fundamental capabilities including detailed image understanding, benefiting from multimodal input when available rather than fully relying on language, factuality and grounding for information retrieval, and over refusals.
A Weakly Supervised Segmentation Network Embedding Cross-scale Attention Guidance and Noise-sensitive Constraint for Detecting Tertiary Lymphoid Structures of Pancreatic Tumors
Jul 27, 2023


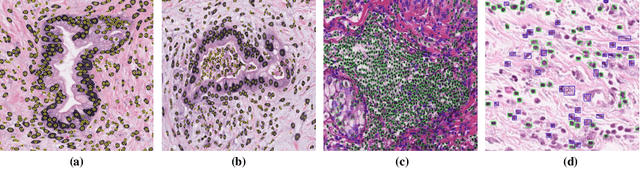
The presence of tertiary lymphoid structures (TLSs) on pancreatic pathological images is an important prognostic indicator of pancreatic tumors. Therefore, TLSs detection on pancreatic pathological images plays a crucial role in diagnosis and treatment for patients with pancreatic tumors. However, fully supervised detection algorithms based on deep learning usually require a large number of manual annotations, which is time-consuming and labor-intensive. In this paper, we aim to detect the TLSs in a manner of few-shot learning by proposing a weakly supervised segmentation network. We firstly obtain the lymphocyte density maps by combining a pretrained model for nuclei segmentation and a domain adversarial network for lymphocyte nuclei recognition. Then, we establish a cross-scale attention guidance mechanism by jointly learning the coarse-scale features from the original histopathology images and fine-scale features from our designed lymphocyte density attention. A noise-sensitive constraint is introduced by an embedding signed distance function loss in the training procedure to reduce tiny prediction errors. Experimental results on two collected datasets demonstrate that our proposed method significantly outperforms the state-of-the-art segmentation-based algorithms in terms of TLSs detection accuracy. Additionally, we apply our method to study the congruent relationship between the density of TLSs and peripancreatic vascular invasion and obtain some clinically statistical results.
Towards Effective Human-AI Collaboration in GUI-Based Interactive Task Learning Agents
Mar 05, 2020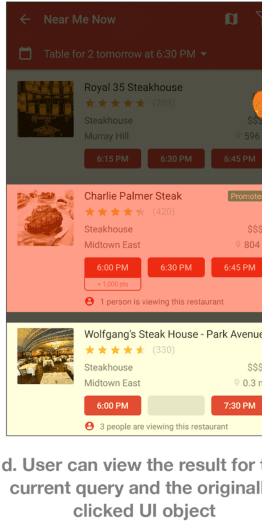
We argue that a key challenge in enabling usable and useful interactive task learning for intelligent agents is to facilitate effective Human-AI collaboration. We reflect on our past 5 years of efforts on designing, developing and studying the SUGILITE system, discuss the issues on incorporating recent advances in AI with HCI principles in mixed-initiative interactions and multi-modal interactions, and summarize the lessons we learned. Lastly, we identify several challenges and opportunities, and describe our ongoing work