 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Structured Outputs from Language Models: Benchmark and Studies
Jan 18, 2025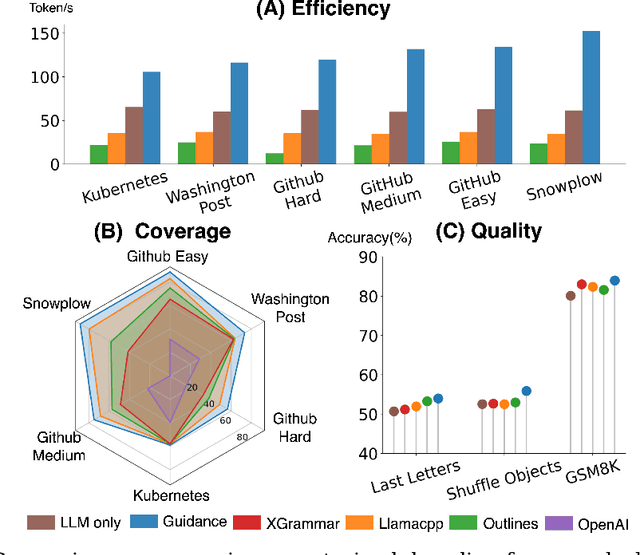
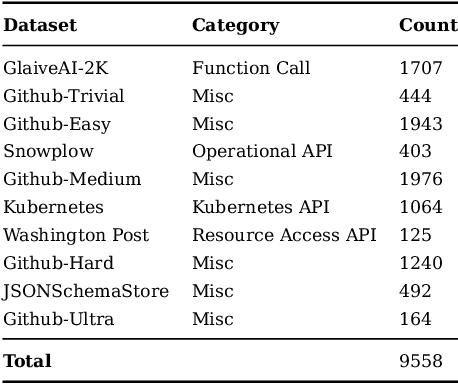
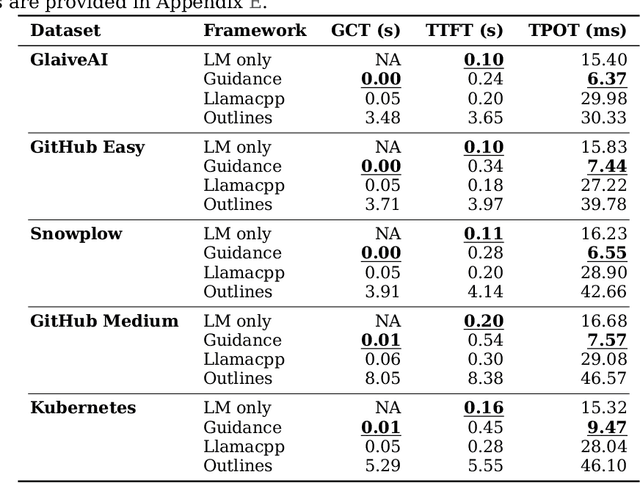
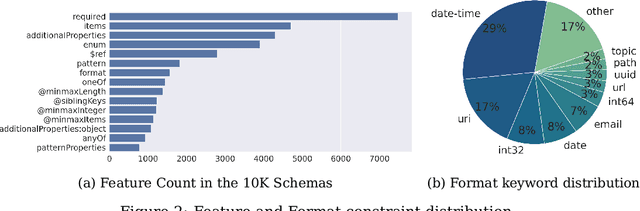
Reliably generating structured outputs has become a critical capability for modern language model (LM) applications. Constrained decoding has emerged as the dominant technology across sectors for enforcing structured outputs during generation. Despite its growing adoption, little has been done with the systematic evaluation of the behaviors and performance of constrained decoding. Constrained decoding frameworks have standardized around JSON Schema as a structured data format, with most uses guaranteeing constraint compliance given a schema. However, there is poor understanding of the effectiveness of the methods in practice. We present an evaluation framework to assess constrained decoding approaches across three critical dimensions: efficiency in generating constraint-compliant outputs, coverage of diverse constraint types, and quality of the generated outputs. To facilitate this evaluation, we introduce JSONSchemaBench, a benchmark for constrained decoding comprising 10K real-world JSON schemas that encompass a wide range of constraints with varying complexity. We pair the benchmark with the existing official JSON Schema Test Suite and evaluate six state-of-the-art constrained decoding frameworks, including Guidance, Outlines, Llamacpp, XGrammar, OpenAI, and Gemini. Through extensive experiments, we gain insights into the capabilities and limitations of constrained decoding on structured generation with real-world JSON schemas. Our work provides actionable insights for improving constrained decoding frameworks and structured generation tasks, setting a new standard for evaluating constrained decoding and structured generation. We release JSONSchemaBench at https://github.com/guidance-ai/jsonschemabench
Steering Language Model Refusal with Sparse Autoencoders
Nov 18, 2024



Responsible practices for deploying language models include guiding models to recognize and refuse answering prompts that are considered unsafe, while complying with safe prompts. Achieving such behavior typically requires updating model weights, which is costly and inflexible. We explore opportunities to steering model activations at inference time, which does not require updating weights. Using sparse autoencoders, we identify and steer features in Phi-3 Mini that mediate refusal behavior. We find that feature steering can improve Phi-3 Minis robustness to jailbreak attempts across various harms, including challenging multi-turn attacks. However, we discover that feature steering can adversely affect overall performance on benchmarks. These results suggest that identifying steerable mechanisms for refusal via sparse autoencoders is a promising approach for enhancing language model safety, but that more research is needed to mitigate feature steerings adverse effects on performance.
From Medprompt to o1: Exploration of Run-Time Strategies for Medical Challenge Problems and Beyond
Nov 06, 2024



Run-time steering strategies like Medprompt are valuable for guiding large language models (LLMs) to top performance on challenging tasks. Medprompt demonstrates that a general LLM can be focused to deliver state-of-the-art performance on specialized domains like medicine by using a prompt to elicit a run-time strategy involving chain of thought reasoning and ensembling. OpenAI's o1-preview model represents a new paradigm, where a model is designed to do run-time reasoning before generating final responses. We seek to understand the behavior of o1-preview on a diverse set of medical challenge problem benchmarks. Following on the Medprompt study with GPT-4, we systematically evaluate the o1-preview model across various medical benchmarks. Notably, even without prompting techniques, o1-preview largely outperforms the GPT-4 series with Medprompt. We further systematically study the efficacy of classic prompt engineering strategies, as represented by Medprompt, within the new paradigm of reasoning models. We found that few-shot prompting hinders o1's performance, suggesting that in-context learning may no longer be an effective steering approach for reasoning-native models. While ensembling remains viable, it is resource-intensive and requires careful cost-performance optimization. Our cost and accuracy analysis across run-time strategies reveals a Pareto frontier, with GPT-4o representing a more affordable option and o1-preview achieving state-of-the-art performance at higher cost. Although o1-preview offers top performance, GPT-4o with steering strategies like Medprompt retains value in specific contexts. Moreover, we note that the o1-preview model has reached near-saturation on many existing medical benchmarks, underscoring the need for new, challenging benchmarks. We close with reflections on general directions for inference-time computation with LLMs.
GAMformer: In-Context Learning for Generalized Additive Models
Oct 06, 2024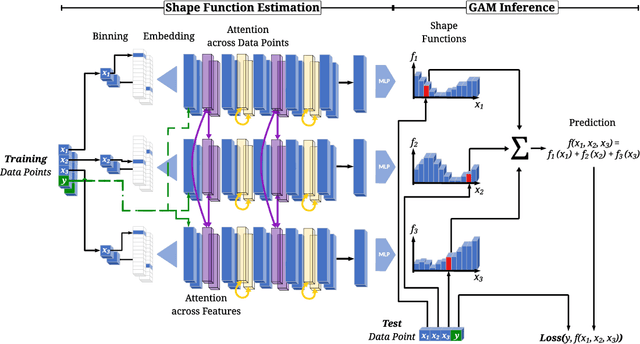
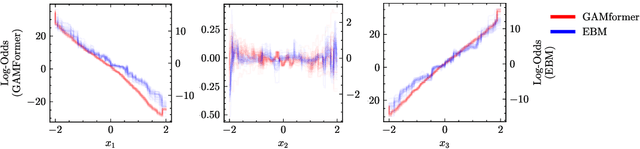

Generalized Additive Models (GAMs) are widely recognized for their ability to create fully interpretable machine learning models for tabular data. Traditionally, training GAMs involves iterative learning algorithms, such as splines, boosted trees, or neural networks, which refine the additive components through repeated error reduction. In this paper, we introduce GAMformer, the first method to leverage in-context learning to estimate shape functions of a GAM in a single forward pass, representing a significant departure from the conventional iterative approaches to GAM fitting. Building on previous research applying in-context learning to tabular data, we exclusively use complex, synthetic data to train GAMformer, yet find it extrapolates well to real-world data. Our experiments show that GAMformer performs on par with other leading GAMs across various classification benchmarks while generating highly interpretable shape functions.
Elephants Never Forget: Memorization and Learning of Tabular Data in Large Language Models
Apr 09, 2024While many have shown how Large Language Models (LLMs) can be applied to a diverse set of tasks, the critical issues of data contamination and memorization are often glossed over. In this work, we address this concern for tabular data. Specifically, we introduce a variety of different techniques to assess whether a language model has seen a tabular dataset during training. This investigation reveals that LLMs have memorized many popular tabular datasets verbatim. We then compare the few-shot learning performance of LLMs on datasets that were seen during training to the performance on datasets released after training. We find that LLMs perform better on datasets seen during training, indicating that memorization leads to overfitting. At the same time, LLMs show non-trivial performance on novel datasets and are surprisingly robust to data transformations. We then investigate the in-context statistical learning abilities of LLMs. Without fine-tuning, we find them to be limited. This suggests that much of the few-shot performance on novel datasets is due to the LLM's world knowledge. Overall, our results highlight the importance of testing whether an LLM has seen an evaluation dataset during pre-training. We make the exposure tests we developed available as the tabmemcheck Python package at https://github.com/interpretml/LLM-Tabular-Memorization-Checker
Elephants Never Forget: Testing Language Models for Memorization of Tabular Data
Mar 11, 2024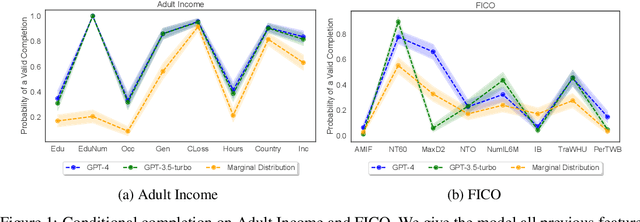
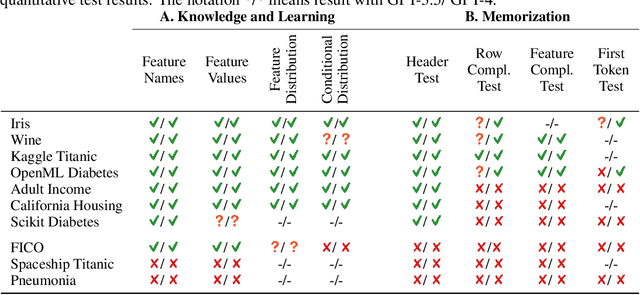
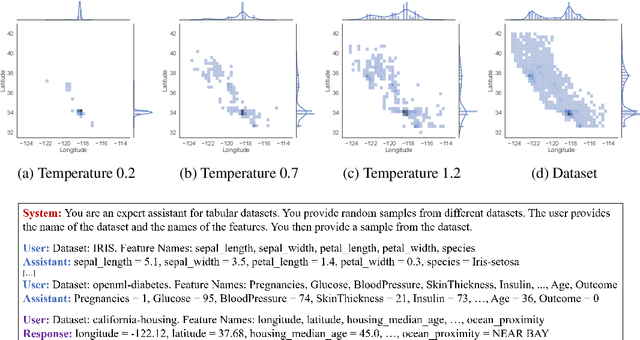
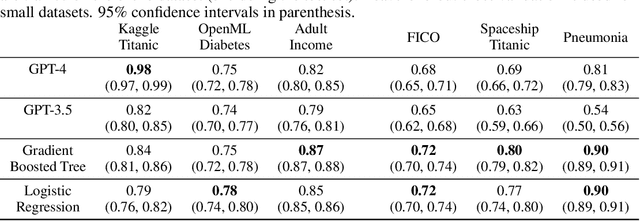
While many have shown how Large Language Models (LLMs) can be applied to a diverse set of tasks, the critical issues of data contamination and memorization are often glossed over. In this work, we address this concern for tabular data. Starting with simple qualitative tests for whether an LLM knows the names and values of features, we introduce a variety of different techniques to assess the degrees of contamination, including statistical tests for conditional distribution modeling and four tests that identify memorization. Our investigation reveals that LLMs are pre-trained on many popular tabular datasets. This exposure can lead to invalid performance evaluation on downstream tasks because the LLMs have, in effect, been fit to the test set. Interestingly, we also identify a regime where the language model reproduces important statistics of the data, but fails to reproduce the dataset verbatim. On these datasets, although seen during training, good performance on downstream tasks might not be due to overfitting. Our findings underscore the need for ensuring data integrity in machine learning tasks with LLMs. To facilitate future research, we release an open-source tool that can perform various tests for memorization \url{https://github.com/interpretml/LLM-Tabular-Memorization-Checker}.
Differentially Private Synthetic Data via Foundation Model APIs 2: Text
Mar 04, 2024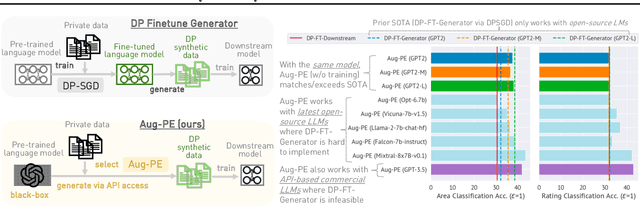
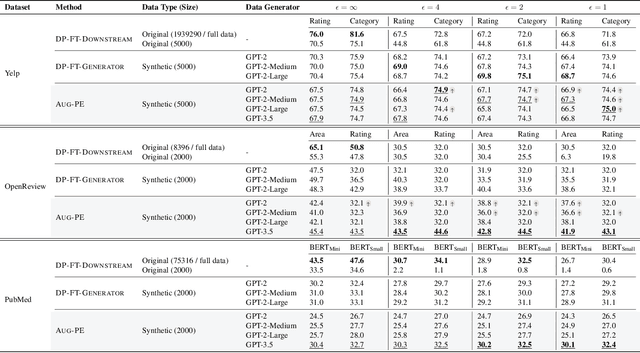
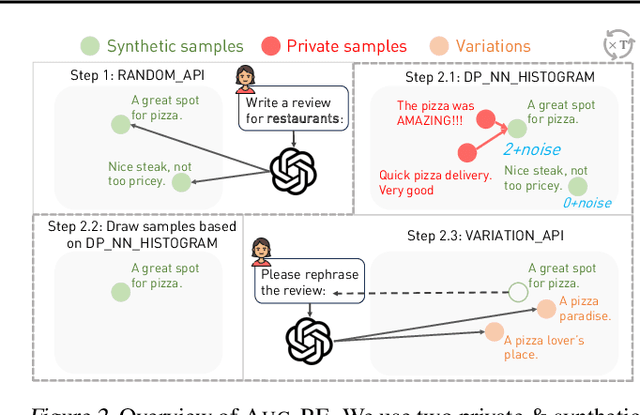
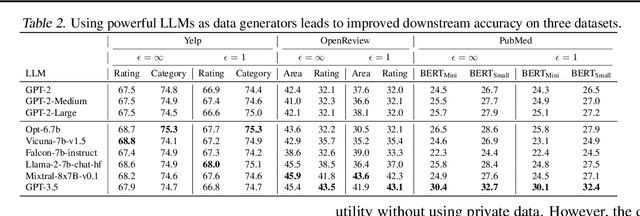
Text data has become extremely valuable due to the emergence of machine learning algorithms that learn from it. A lot of high-quality text data generated in the real world is private and therefore cannot be shared or used freely due to privacy concerns. Generating synthetic replicas of private text data with a formal privacy guarantee, i.e., differential privacy (DP), offers a promising and scalable solution. However, existing methods necessitate DP finetuning of large language models (LLMs) on private data to generate DP synthetic data. This approach is not viable for proprietary LLMs (e.g., GPT-3.5) and also demands considerable computational resources for open-source LLMs. Lin et al. (2024) recently introduced the Private Evolution (PE) algorithm to generate DP synthetic images with only API access to diffusion models. In this work, we propose an augmented PE algorithm, named Aug-PE, that applies to the complex setting of text. We use API access to an LLM and generate DP synthetic text without any model training. We conduct comprehensive experiments on three benchmark datasets. Our results demonstrate that Aug-PE produces DP synthetic text that yields competitive utility with the SOTA DP finetuning baselines. This underscores the feasibility of relying solely on API access of LLMs to produce high-quality DP synthetic texts, thereby facilitating more accessible routes to privacy-preserving LLM applications. Our code and data are available at https://github.com/AI-secure/aug-pe.
Data Science with LLMs and Interpretable Models
Feb 22, 2024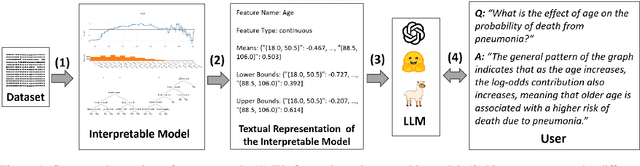
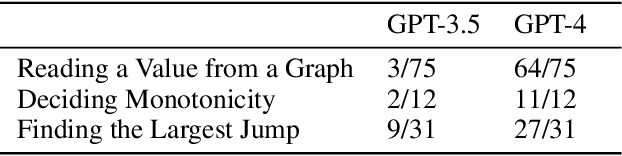


Recent years have seen important advances in the building of interpretable models, machine learning models that are designed to be easily understood by humans. In this work, we show that large language models (LLMs) are remarkably good at working with interpretable models, too. In particular, we show that LLMs can describe, interpret, and debug Generalized Additive Models (GAMs). Combining the flexibility of LLMs with the breadth of statistical patterns accurately described by GAMs enables dataset summarization, question answering, and model critique. LLMs can also improve the interaction between domain experts and interpretable models, and generate hypotheses about the underlying phenomenon. We release \url{https://github.com/interpretml/TalkToEBM} as an open-source LLM-GAM interface.
Can Generalist Foundation Models Outcompete Special-Purpose Tuning? Case Study in Medicine
Nov 28, 2023
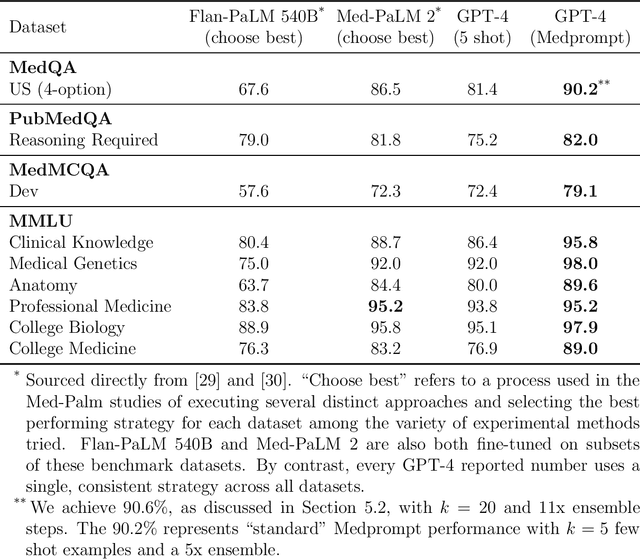


Generalist foundation models such as GPT-4 have displayed surprising capabilities in a wide variety of domains and tasks. Yet, there is a prevalent assumption that they cannot match specialist capabilities of fine-tuned models. For example, most explorations to date on medical competency benchmarks have leveraged domain-specific training, as exemplified by efforts on BioGPT and Med-PaLM. We build on a prior study of GPT-4's capabilities on medical challenge benchmarks in the absence of special training. Rather than using simple prompting to highlight the model's out-of-the-box capabilities, we perform a systematic exploration of prompt engineering. We find that prompting innovation can unlock deeper specialist capabilities and show that GPT-4 easily tops prior leading results for medical benchmarks. The prompting methods we explore are general purpose, and make no specific use of domain expertise, removing the need for expert-curated content. Our experimental design carefully controls for overfitting during the prompt engineering process. We introduce Medprompt, based on a composition of several prompting strategies. With Medprompt, GPT-4 achieves state-of-the-art results on all nine of the benchmark datasets in the MultiMedQA suite. The method outperforms leading specialist models such as Med-PaLM 2 by a significant margin with an order of magnitude fewer calls to the model. Steering GPT-4 with Medprompt achieves a 27% reduction in error rate on the MedQA dataset over the best methods to date achieved with specialist models and surpasses a score of 90% for the first time. Beyond medical problems, we show the power of Medprompt to generalize to other domains and provide evidence for the broad applicability of the approach via studies of the strategy on exams in electrical engineering, machine learning, philosophy, accounting, law, nursing, and clinical psychology.
Interpretable Predictive Models to Understand Risk Factors for Maternal and Fetal Outcomes
Oct 16, 2023Although most pregnancies result in a good outcome, complications are not uncommon and can be associated with serious implications for mothers and babies. Predictive modeling has the potential to improve outcomes through better understanding of risk factors, heightened surveillance for high risk patients, and more timely and appropriate interventions, thereby helping obstetricians deliver better care. We identify and study the most important risk factors for four types of pregnancy complications: (i) severe maternal morbidity, (ii) shoulder dystocia, (iii) preterm preeclampsia, and (iv) antepartum stillbirth. We use an Explainable Boosting Machine (EBM), a high-accuracy glass-box learning method, for prediction and identification of important risk factors. We undertake external validation and perform an extensive robustness analysis of the EBM models. EBMs match the accuracy of other black-box ML methods such as deep neural networks and random forests, and outperform logistic regression, while being more interpretable. EBMs prove to be robust. The interpretability of the EBM models reveals surprising insights into the features contributing to risk (e.g. maternal height is the second most important feature for shoulder dystocia) and may have potential for clinical application in the prediction and prevention of serious complications in pregnancy.